
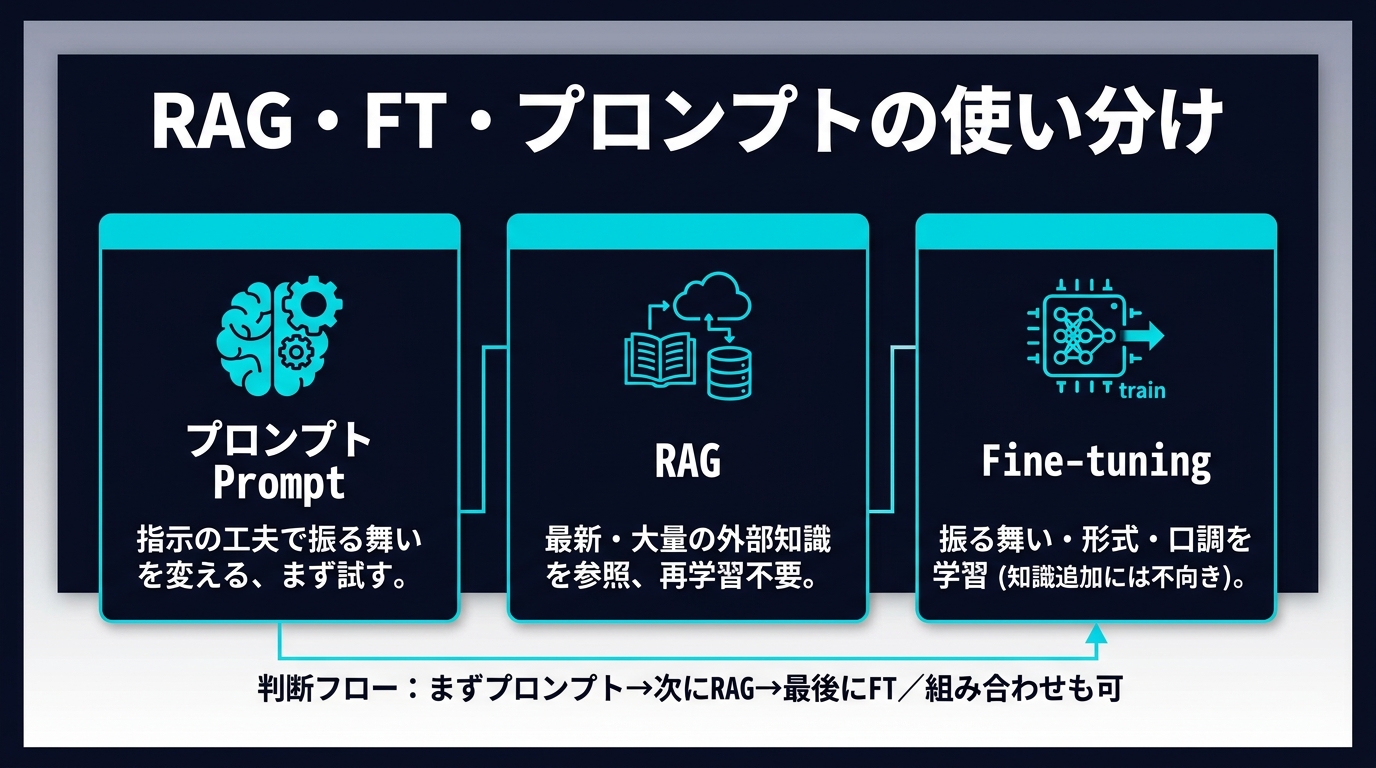
結論: 「精度を上げたい」と思ったら、まずプロンプト → 次にRAG → 最後にファインチューニング(FT)の順で検討する。RAGは「知識を足す」、FTは「振る舞い・形式を固める」ための技術であり、両者は別軸の問題を解く。最新情報や独自データを参照させたいだけならFTは不要で、RAGで足りる。
この記事の要点:
- 要点1: OpenAIは精度最適化を「文脈(何を知っているか)」と「振る舞い(どう動くか)」の2軸で整理し、RAGは前者・FTは後者の問題を解くと公式に明言している。
- 要点2: 「FTで知識を覚えさせる」は典型的な落とし穴。OpenAI/Anthropicとも、新しい知識の注入はプロンプト内のコンテキスト(=RAG)で行うことを推奨している。
- 要点3: 最初に試すべきはプロンプトエンジニアリング。要約・翻訳・コード生成などはプロンプトだけで完結することが多く、コストもゼロに近い。
対象読者: LLMアプリ/AIエージェントの精度を上げたいが、どの手法に投資すべきか迷っている開発者・技術リード
難易度: 中級
読了時間: 約13分
「出力の精度を上げたい。RAGを組むべきか、それともファインチューニングか、いやプロンプトを直すだけで済むのか——結局どれに手を付ければいいのか分からない」
LLMを業務に組み込んでいると、ほぼ必ずこの分岐にぶつかります。3つの手法は名前が並列で語られがちですが、実際には「解いている問題」がまったく違います。にもかかわらず、いきなりファインチューニング(以下FT)に飛びついて、数週間かけてデータセットを作ったのに精度が上がらなかった、というのはよくある失敗です。
この記事では、プロンプト・RAG・FTがそれぞれ何を変えるのかを整理したうえで、判断軸を表にまとめ、意思決定フローと組み合わせ(ハイブリッド)の考え方、そしてハマりやすい誤解までを、開発者向けに実装イメージ付きで解説します。読み終えれば、自分のユースケースで「次に何に投資すべきか」が明確になるはずです。
AIエージェントの全体像から手法選定の位置づけを掴みたい方は、AIエージェント実装ロードマップ|RAG・実行・運用の必須技術も併せて参照してください。
3つの手法は「別の問題」を解いている
まず最初に押さえるべきは、プロンプト・RAG・FTが競合する選択肢ではなく、異なる軸の問題に対応する技術だという点です。OpenAIの公式ガイド「Optimizing LLM Accuracy」は、精度の問題を次の2軸で整理しています(2026年6月時点)。
- 文脈最適化(context optimization): モデルが「何を知っているか」の問題。学習データに含まれない知識、古くなった情報、社内固有のドキュメントが必要なケース。→ 応答の正確さを上げる軸。
- 振る舞い最適化(LLM optimization): モデルが「どう動くか」の問題。出力フォーマットが安定しない、口調・トーンが合わない、推論の手順を一貫して守ってくれないケース。→ 挙動の一貫性を上げる軸。
この2軸に各手法を当てはめると、役割の違いがはっきりします。OpenAIの表現を借りれば、RAGは「試験中に教科書を持ち込む」ようなその場で参照する記憶の問題を、FTは訓練によって挙動を身体に染み込ませる学習済みの記憶の問題を解きます。
プロンプトエンジニアリングが変えるもの
プロンプトは、モデルの重みもデータも変えず、指示の与え方だけで出力を制御する手法です。役割の明示、出力フォーマットの指定、Few-shot(例示)、思考の手順を踏ませる、といったテクニックで挙動を整えます。コストはAPI呼び出し1回分のトークンだけ、変更は数秒で反映され、失敗してもすぐ巻き戻せます。OpenAIは「要約・翻訳・コード生成のようなユースケースでは、プロンプトエンジニアリングだけで十分なことが多い」としています。
# プロンプトだけで出力フォーマットを固定する例(Few-shot + ロール指定)
SYSTEM = """あなたは契約書レビューの専門家です。
入力された条項を以下のJSONで返してください。説明文は付けないこと。
{"risk_level": "high|medium|low", "reason": "100字以内"}"""
FEWSHOT = [
{"role": "user", "content": "本契約は甲の都合により無条件で解除できる。"},
{"role": "assistant", "content": '{"risk_level":"high","reason":"一方的な無条件解除条項。乙に著しく不利。"}'},
]
messages = [{"role": "system", "content": SYSTEM}, *FEWSHOT,
{"role": "user", "content": user_clause}]
RAGが変えるもの
RAG(Retrieval-Augmented Generation)は、外部の知識ベースから関連情報を検索し、それをプロンプトに差し込んでから生成させる手法です。AWSの定義によれば、RAGは「学習データの外にある信頼できる知識ベースを参照させる」もので、モデルを再学習させることなく、最新の研究・統計・ニュースや社内固有の情報をLLMに与えられます。これは2軸でいう「文脈最適化」そのものです。
RAGの強みは、知識の更新がデータ側の差し替えだけで済むこと。料金表が変わったらドキュメントを入れ替えればよく、モデルには一切触れません。週次・日次で更新されるような情報は、RAGがほぼ必須です。RAGの内部実装(チャンク分割・埋め込みモデル選定・評価)は別記事で深掘りしていますが、ここでは「知識を足す技術」という役割だけ押さえれば十分です。
# RAGの最小構成:検索 → 文脈注入 → 生成
def answer(question: str) -> str:
docs = vector_store.similarity_search(question, k=4) # 知識ベースから検索
context = "nn".join(d.page_content for d in docs)
prompt = f"""以下の社内ドキュメントだけを根拠に回答してください。
根拠がなければ「該当情報なし」と答えること。
# ドキュメント
{context}
# 質問
{question}"""
return llm.invoke(prompt)
ファインチューニングが変えるもの
FTは、教師データでモデルの重みそのものを追加学習させ、挙動・形式・トーンを恒常的に書き換える手法です。OpenAIは、FTが得意なのは「分類、構造化出力のフォーマット化、指示追従の失敗の修正、特定の文体・トーンでの生成」だとしています。逆に言えば、FTは「新しい事実を覚えさせる」ための技術ではありません。
FTのもう一つの実用的な価値は、小さく安いモデルを特定タスクに特化させること。OpenAIは「大きなモデルではコストが見合わないタスクで、小さく安く速いモデルを訓練して同等の精度を出せる」と述べています。プロンプトに毎回詰め込んでいた長い指示やFew-shot例を重みに焼き込めば、推論時のトークンが減り、レイテンシとコストが下がる、というのが正しい使いどころです。
# FT用データセット(JSONL)の例:振る舞い/形式を教える
{"messages":[{"role":"system","content":"丁寧語の社内ヘルプデスク"},{"role":"user","content":"パスワードを忘れた"},{"role":"assistant","content":"お手数をおかけします。社内ポータルの『パスワード再設定』からお手続きください。1時間以内に反映されます。"}]}
{"messages":[{"role":"system","content":"丁寧語の社内ヘルプデスク"},{"role":"user","content":"VPNが繋がらない"},{"role":"assistant","content":"恐れ入ります。まずクライアントを再起動のうえ、社内ネットワーク外からの接続かをご確認ください。改善しなければ情シスへ起票します。"}]}
判断軸で比較する
5つの観点で3手法を比べると、それぞれが向く問題の輪郭が見えてきます。記事冒頭で挙げた「最新性・知識量・独自フォーマット/口調・コスト・運用負荷」を軸に整理します。
| 判断軸 | プロンプト | RAG | ファインチューニング |
|---|---|---|---|
| 最新性(情報の鮮度) | △ プロンプトに都度貼れば可 | ◎ データ差し替えで即反映 | ✕ 再学習しない限り固定 |
| 知識量(参照できる情報の規模) | ✕ コンテキスト窓に制限 | ◎ 大規模な外部DBを参照可 | △ 学習量に依存・更新困難 |
| 独自フォーマット/口調 | ○ 例示で誘導(ばらつき残る) | ✕ 苦手(知識の問題ではない) | ◎ 最も安定して固定できる |
| 初期コスト | ◎ ほぼゼロ | ○ 検索基盤の構築が必要 | ✕ データ作成+学習コスト大 |
| 運用負荷 | ◎ 軽い | △ 検索精度の継続改善が必要 | ✕ モデルver追従・再学習が重い |
| 推論コスト/レイテンシ | △ 指示が長いと増える | △ 検索+長い文脈で増える | ◎ 指示を重みに焼け込めば軽い |
この表から読み取れる原則はシンプルです。「知らない」問題はRAGで、「うまく動けない」問題はFTで解く。そして、どちらの問題かを切り分ける前に、まずプロンプトで改善の余地がないかを試す——これが最もコスト効率の良い順序です。
意思決定フロー:何を試すべきか
実務では、次の順番で検討すると無駄な投資を避けられます。OpenAIもAnthropicも「プロンプトを起点に、評価で不足が見えた箇所だけ次の手法に進む」加算的アプローチを推奨しています。手法は排他ではなく、積み重ねるものだという前提です。
- まず評価(eval)の物差しを作る。何点なら合格かを定義しないと、どの手法が効いたか判断できない。これが無いまま手法選定に進むのが最大の失敗。
- プロンプトエンジニアリングを試す。役割指定・出力フォーマット明示・Few-shot・思考手順の付与。要約/翻訳/分類はここで終わることが多い。
- 出力が「事実を知らない/古い/社内情報を参照できない」なら RAG を追加。知識の問題はプロンプトの工夫では埋まらない。外部知識ベースを検索して文脈注入する。
- 知識はあるのに「形式が崩れる/口調が合わない/指示を守らない」なら FT を検討。振る舞いの一貫性が、プロンプトとFew-shotの限界を超えて必要なときの最終手段。
- コスト/レイテンシが問題で、長い指示を毎回送りたくないなら FT で小型モデルに特化。大型モデル+長大プロンプトを、小型FTモデルで置き換える。
注意したいのは、3→4の判断です。「精度が低い」を一括りにせず、原因が知識不足(→RAG)なのか挙動不安定(→FT)なのかを評価データで切り分けること。ここを取り違えると、RAGで解けた問題にFTのコストを払う、あるいはその逆が起きます。比較記事として上位の構造も確認しましたが、結論はおおむねこの順序に収束します。
切り分けの実務的なコツは、失敗ケースを具体的に分類することです。たとえばQAボットの誤答を「答えそのものが間違っている/古い」グループと「答えは合っているがフォーマットや口調が崩れている」グループに仕分けます。前者が多ければRAGの検索精度や知識ソースの問題、後者が多ければプロンプトかFTの問題、と原因の所在がデータで見えてきます。感覚で「とりあえずFT」と判断しないための、最も確実な物差しが評価データです。
組み合わせる:RAG+FTのハイブリッド
本番システムでは、3手法を組み合わせるのが一般的です。「別の問題を解く」技術なので、足し合わせると弱点を補い合います。代表的なパターンは RAG+FT です。
- RAGで「最新かつ正確な知識」を供給し、ハルシネーションと情報の陳腐化を防ぐ。
- FTで「その知識をどう使い、どう答えるか」の振る舞いを固める。たとえば「検索結果を必ず根拠として引用する」「指定JSONで返す」「自社の専門用語・トーンで話す」といった挙動を安定させる。
具体例として、社内ヘルプデスクのエージェントを考えます。知識(手順書・規程)は頻繁に更新されるのでRAGで参照させ、回答スタイル(丁寧語・エスカレーション判断・引用の付け方)はFTで固定する。こうすると、ドキュメントを差し替えるだけで知識は最新を保ちつつ、応答品質はブレません。逆に、知識までFTに焼き込もうとすると、規程が変わるたびに再学習が必要になり、運用が破綻します。
「どちらを先に着手するか」で迷ったら、ほとんどのケースでRAGが先、FTは後です。理由は3つあります。第一に、知識不足によるハルシネーションはユーザーの信頼を直接損なうため、影響が大きい。第二に、RAGはデータ側で完結するためベースモデルの進化にそのまま乗れる。第三に、RAGで土台を固めてから残った「振る舞いのブレ」を観察したほうが、FTで何を教えるべきかが明確になります。FTのデータセットは、RAG運用で蓄積した実ログ(理想的な回答例)から作るのが効率的で、ゼロから合成するより質の高い教師データになります。
# ハイブリッド:RAGで知識、FTモデルで振る舞いを担保
docs = vector_store.similarity_search(question, k=4) # 知識はRAGで最新化
context = "nn".join(d.page_content for d in docs)
resp = client.chat.completions.create(
model="ft:gpt-xxx:helpdesk-style", # 口調・引用形式・JSONはFTで固定済み
messages=[
{"role": "system", "content": "根拠ドキュメントのみを引用して回答。"},
{"role": "user", "content": f"# 根拠n{context}nn# 質問n{question}"},
],
)
RAG側の検索精度がそもそも低いと、いくらFTで挙動を固めても土台が崩れます。チャンク設計や埋め込みモデルの選定が効くポイントなので、Embeddingモデル選定ガイド|RAG精度を上げる実装と比較も参照しておくと、ハイブリッド構成の足腰が安定します。
【注意】よくある誤解と落とし穴
手法選定でつまずく典型パターンを、❌正しくない理解/⭕正しい理解の形で整理します。
誤解1: ファインチューニングで知識を覚えさせる
❌ 「社内ドキュメントをFTすれば、モデルが内容を暗記して答えてくれる」
⭕ FTは振る舞い・形式の学習に向き、新しい事実の注入には向かない。OpenAI/Anthropicとも、知識はプロンプト内のコンテキスト(=RAG)で与えることを推奨。知識をFTに焼き込むと、更新のたびに再学習が必要で、しかも暗記の精度も不安定になりやすい。
誤解2: RAGとFTはどちらか一方を選ぶもの
❌ 「RAGかFTか、二択で決めなければならない」
⭕ 両者は別軸の問題を解くので、足し合わせられる。OpenAIも「これらは排他ではなく加算的に重なる(stack)」と明言。本番では RAG+FT+プロンプトの併用が普通。
誤解3: 精度が低い=すぐFT
❌ 「出力が悪いから、いきなりFTで作り込もう」
⭕ まずプロンプトとevalで原因を切り分ける。多くの精度問題は、出力フォーマットの指定漏れやFew-shot不足など、プロンプトで解決できる。FTはコスト・運用負荷が最も高いので、他を試し切ってから。
誤解4: FTすれば運用が楽になる
❌ 「一度FTすれば、あとはメンテ不要」
⭕ FTモデルはベースモデルのバージョンアップに追従できず、新しい優れたモデルが出ても乗り換えが容易でない。データ・学習パイプラインの保守も含め、運用負荷はむしろ重い。トレードオフを正直に見積もること。
まとめ: 今日から始める3つのアクション
- 今日: 自分のユースケースの不満を「知識不足(知らない)」か「挙動不安定(うまく動けない)」かに仕分けてみる。前者ならRAG、後者ならまずプロンプト→FTの方向。
- 今週中: 評価データ(合否を判定できる入出力例を10〜20件)を用意し、現状のプロンプトだけでどこまで上がるかを測る。FTの判断はその後。
- 今月中: 知識系はRAGを最小構成で組み、振る舞いの安定が本当に必要なタスクに絞ってFTを検討。最初からハイブリッド前提で設計する。
AIエージェント・ツールの最新情報をキャッチアップしたい方へ
Agent Labでは、週1回のニュースレターでAIツールの最新比較・活用事例をお届けしています。
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』(SBクリエイティブ)。
ご質問・ご相談は お問い合わせフォーム からお気軽にどうぞ。
参考・出典
- Optimizing LLM Accuracy — OpenAI(文脈最適化 vs 振る舞い最適化の2軸モデル、参照日: 2026-06-05)
- Model optimization(Fine-tuning guide) — OpenAI(FTの得意領域とプロンプト/RAG優先の推奨、参照日: 2026-06-05)
- Prompt engineering overview — Anthropic(プロンプトを起点とする最適化、コスト/レイテンシはモデル選定で、参照日: 2026-06-05)
- RAG(検索拡張生成)とは — AWS(再学習なしで外部知識・最新情報を参照させる定義、参照日: 2026-06-05)


