
結論:AIエージェントはプロンプト1行・モデルバージョン変更・ツール仕様更新で品質が黙って劣化する。一度きりの評価では防げない。PR単位でゴールデンデータセットを回し、閾値割れでマージをブロックする「継続的評価 × CI/CD回帰ゲート」が2026年の標準プロセスになっている。
- 要点1:PR単位のオフライン評価 + 回帰ゲートでサイレントデグレを検知できる
- 要点2:ゴールデンデータセットは20〜50件から始め、実障害ケースを継続追加して育てる
- 要点3:カナリアリリース + ドリフト検知でオンライン評価まで繋げると本番品質の継続保証が実現する
対象読者:AIエージェントを本番運用しているMLエンジニア・QAエンジニア・DevOpsエンジニア
今日やること:ゴールデンデータセットのディレクトリをリポジトリに作り、最初の10件を実業務ログから拾ってcommitする
なぜAIエージェントに「継続的」評価が必要なのか
通常のソフトウェアは、コードを変えなければ動作が変わらない。しかしAIエージェントは違う。プロンプトを1行変えただけで、特定のエッジケースでの挙動が大きく変わる。使っているLLMのモデルバージョンがサービス側の判断で更新されても、出力分布がシフトする。ツール(外部API・RAG・コードインタープリタ)の仕様が変わっても、静かに失敗する。
これが「サイレントデグレ」と呼ばれる問題だ。エラーが出るわけではない。例外もスローされない。でも品質は着実に落ちている。ユーザーからのクレームが積み上がって初めて気づく、という状況が今も多くの現場で起きている。
一度きりのリリース前評価(オフライン評価)だけでは、この問題は防げない。評価した瞬間は合格しても、その後の変更で合格水準を割るからだ。開発速度が高い現代のAIプロダクトでは、プロンプト変更・モデルアップグレード・ツール更新が週単位で走る。評価も同じ頻度で回す必要がある。
「継続的評価」とは、この問題に対する構造的な答えだ。コードのPRと同じように、AIエージェントのあらゆる変更に対して自動評価を走らせ、品質の回帰(デグレ)をCI/CDで検知してブロックするプロセスを指す。
オフライン評価をCI/CDに組み込む:回帰ゲートの設計
オフライン評価をCI/CDに組み込む基本パターンは以下の流れだ。
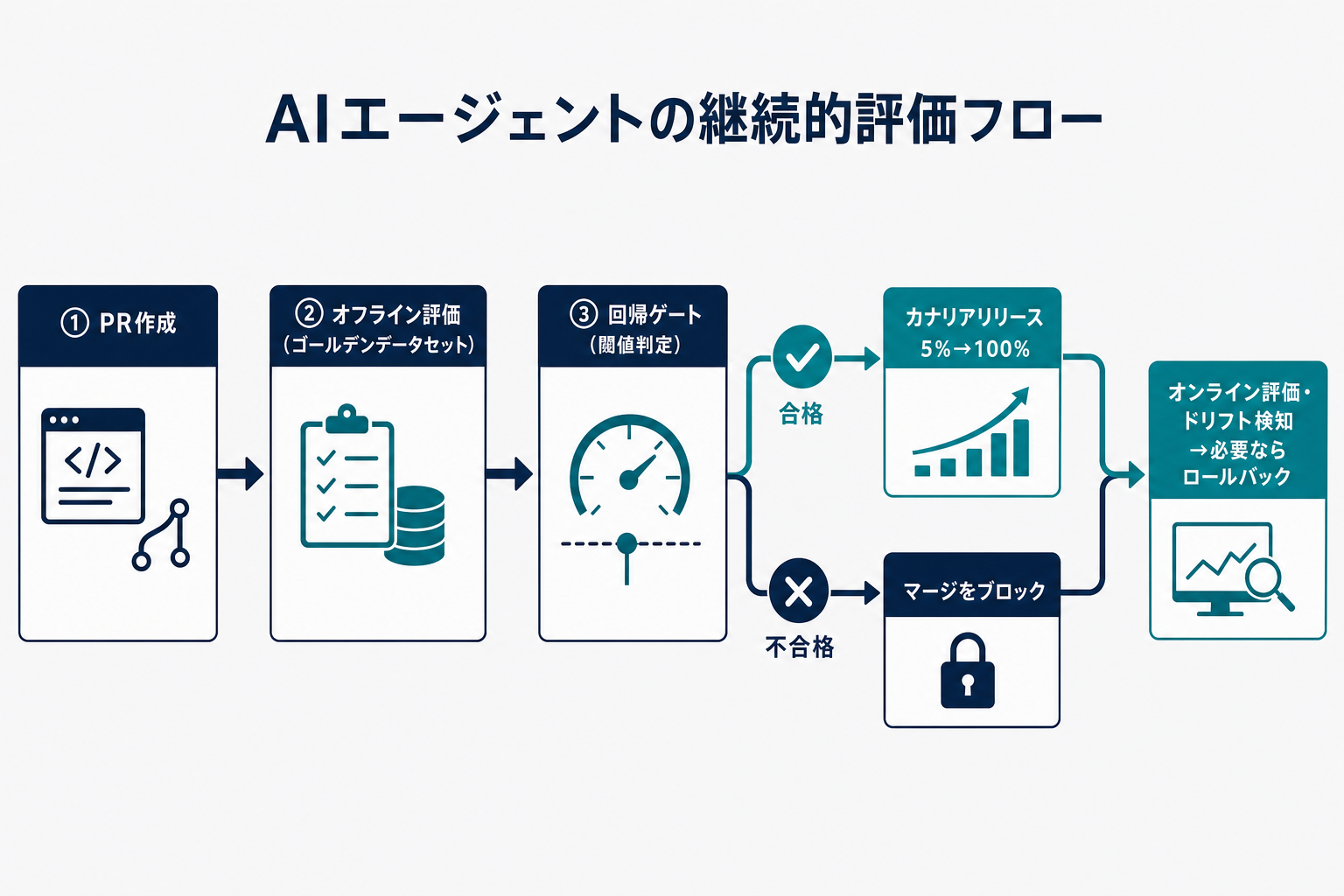
PRがオープンされると、CIパイプラインが自動的にエージェント評価を実行する。ゴールデンデータセット(後述)に含まれる入力をエージェントに投げ、得られた出力を評価器(deterministic評価またはLLM-as-judge)でスコアリングする。全件のスコアを集計して平均スコアを計算し、事前に設定した閾値(threshold)と比較する。閾値を下回った場合、そのPRのマージをブロックする。これが「回帰ゲート」だ。
以下はGitHub ActionsでPR単位の評価を回し、閾値割れでfailさせる設定例(疑似コード)だ。
# .github/workflows/agent-eval.yml
name: Agent Regression Gate
on:
pull_request:
paths:
- 'agent/**'
- 'prompts/**'
- 'tools/**'
jobs:
evaluate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
- name: Install dependencies
run: pip install -r requirements-eval.txt
- name: Run evaluation against golden dataset
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
EVAL_THRESHOLD: '0.85' # タスク成功率の閾値
run: |
python scripts/run_eval.py
--dataset data/golden_dataset/v2.jsonl
--threshold $EVAL_THRESHOLD
--output eval_results.json
- name: Check regression gate
run: |
python scripts/check_gate.py
--results eval_results.json
--fail-on-regression
# スコアが閾値未満なら exit code 1 でCI fail
- name: Upload eval report
uses: actions/upload-artifact@v4
if: always()
with:
name: eval-report
path: eval_results.json
実装時の重要なポイントをまとめる。
- CIは「安くて速い評価」と「重い評価」を分ける:PR毎に実行するチェックは高速・低コストな決定論的評価(文字列マッチ・JSONスキーマ検証・ツール呼び出しの有無)を中心にする。LLM-as-judgeによる重い評価は、夜間のスケジュール実行(nightly)にまわすのが実用的だ
- 閾値はベースラインから設定する:最初から固定値を決めようとしない。まず現状の性能を計測してベースラインを取り、そこから5〜10ポイント下をソフト閾値(警告)、15〜20ポイント下をハード閾値(ブロック)として設定すると運用しやすい
- 評価結果をPRコメントに自動投稿する:スコアの変動・改善・退行をPRに直接コメントとして残すと、レビュアーが文脈を把握しやすくなる。OpenAI Evals(github.com/openai/evals)等のフレームワークはこの機能を持つものが多い
ゴールデンデータセットの作り方と育て方
回帰ゲートの精度は、ゴールデンデータセットの質に直結する。形ばかりのデータセットでは、本当に重要なデグレを検知できない。
最初の20〜50件から始める
初期のエージェントはper-changeの効果量が大きいため、小さなデータセットでも十分なシグナルが取れる。まず実業務ログから20〜50件を手動で選定し、「良い出力の例」と「期待する出力のラベル」を付けてcommitする。完璧なデータセットを最初から作ろうとしない。動き始めたら育てていく思想が重要だ。
含めるべきケースの3分類
| 分類 | 内容 | 含める割合の目安 |
|---|---|---|
| 代表ケース | 日常的に最も多く発生するユーザーリクエスト。エージェントの「本線」を守るために必要 | 50〜60% |
| エッジケース | 境界条件・曖昧な入力・マルチターン・複数ツール連携が必要なケース。弱点を可視化する | 25〜35% |
| 回帰ケース | 過去に実際に発生した障害・バグの再現シナリオ。一度直した問題が再発しないことを保証する | 10〜20% |
データセットのバージョン管理
ゴールデンデータセットはコードと同じリポジトリにcommitし、バージョン管理する。data/golden_dataset/v1.jsonl、data/golden_dataset/v2.jsonl のように明示的にバージョンを分けることで、どのデータセットで評価したかをCI実行ログと紐づけられる。データセットを更新した際は、必ず変更理由をコミットメッセージに記録する。
また、データセットは「生きている」ことを意識する。新しいユーザーパターン・制度変更・API仕様変更が発生したら、対応するケースを追加する。四半期ごとにデータセットを見直し、古くなったケースを入れ替えるサイクルを設けることが品質の長期的な安定につながる。
評価指標の選び方:何を計測するかで守れる品質が変わる
評価指標の選定は、守りたい品質の定義そのものだ。タスクとビジネス要件に応じて適切な指標を選ぶ必要がある。以下に代表的な指標を整理した。
| 指標 | 計測対象 | 評価手法 | 回帰閾値の目安 |
|---|---|---|---|
| タスク成功率 | エージェントが目的のタスクを完遂できたか | Deterministic / LLM-judge | ベースライン -5%以内 |
| ツール呼び出し正確性 | 正しいツールを正しい引数で呼び出せたか | JSON schema検証 / exact match | ベースライン -3%以内 |
| LLM-as-judge スコア | 応答の関連性・正確性・有用性の総合評価 | 高性能モデルでスコアリング | 0.85以上を維持 |
| 平均レイテンシ | エンドツーエンドの応答時間 | 計測値(ms) | ベースライン +20%以内 |
| コスト(トークン) | 1リクエストあたりのLLM消費トークン数 | APIレスポンスのusageフィールド | ベースライン +30%以内 |
| エラー率 | ツール呼び出し失敗・例外・タイムアウトの発生率 | ログ集計 | 1%以下を維持 |
| ハルシネーション率 | ファクトとして誤った情報を出力した割合 | LLM-judge(参照文書との照合) | ベースライン -2%以内 |
特に注意したいのは、コスト・レイテンシも回帰対象に含めることだ。品質だけ追いかけてプロンプトを増やした結果、コストが2倍になっていた、という事故は珍しくない。プロンプト変更のPRにはコスト・レイテンシの変動も自動的に表示させる設計が望ましい。
LLM-as-judgeを採用する場合は、まず人間のアノテーション結果と突き合わせてキャリブレーションを行うこと。人間の判断と相関が取れていないジャッジモデルをゲートに使っても、意味のある回帰検知にならない。
オンライン評価とカナリアリリース:本番品質を段階的に保証する
オフライン評価(CI上のゴールデンデータセット評価)は必要条件だが、十分条件ではない。合成データや過去のケースでは捉えきれない本番特有の入力分布・リアルユーザーの行動パターンは、実際にトラフィックを流してみないとわからない。ここでオンライン評価とカナリアリリースが登場する。
カナリアリリースの仕組み
新バージョン(candidate)を本番に展開する前に、まず全トラフィックの5〜10%だけを新バージョンに向ける。残り90〜95%は現行バージョン(baseline)で処理する。この状態でオンライン評価を24〜48時間実行し、candidateのメトリクスがbaselineと比較して許容範囲内か確認する。問題がなければ段階的に比率を上げ(10% → 25% → 50% → 100%)、完全移行する。問題が検出されたら即座にcandidateへのトラフィックを0%に戻す(自動ロールバック)。
オンライン評価のメトリクス
本番トラフィックのサンプリング(例:100リクエストに1回)に対して以下を継続計測する。
- 5分間隔のリアルタイム品質スコア(LLM-judge or Deterministic)
- エラー率・タイムアウト率の急変
- ユーザーフィードバック(thumbsup/down・エスカレーション率)
- コスト・レイテンシの分布変化
自動ロールバックの閾値設定が重要だ。候補バージョンのエラー率が現行比で2倍を超えた、またはp99レイテンシが現行比で30%超になった、等の条件でアラートを上げ、必要に応じて自動でトラフィックを戻す。Google Cloud Vertex AIのMLOpsドキュメント(cloud.google.com)ではこのパターンを「継続的評価」として標準化している。
ドリフト検知:入力・出力の経時変化を追う
「ドリフト」はAIエージェントが抱えるもう一つのサイレントリスクだ。コードもプロンプトも変えていないのに、時間の経過とともに品質が変化していく現象を指す。主な原因は3つある。
- コンセプトドリフト:ユーザーリクエストの意図・語彙・文脈が変化する(例:新機能がリリースされたらそれに関する質問が急増する)
- データドリフト:入力の分布が変化する(例:季節・イベントでクエリの性質が変わる)
- モデルドリフト:基盤LLMのバージョンがサービス側で更新され、出力分布がシフトする
ドリフト検知の実装パターン
以下のPythonコードは、生産環境の入力分布の変化を埋め込み(embedding)ベースで検知する基本的な実装例だ。
# 注意: 本番環境で使用する前に必ずテスト環境で動作確認してください。
# 動作環境: Python 3.11+, openai>=1.30.0, numpy>=1.26.0, scipy>=1.13.0
import numpy as np
from scipy.spatial.distance import cosine
from datetime import datetime
from openai import OpenAI
client = OpenAI()
def get_embedding(text: str) -> list[float]:
"""テキストの埋め込みベクトルを取得する"""
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
def compute_distribution_shift(
baseline_texts: list[str],
current_texts: list[str],
threshold: float = 0.05 # コサイン距離の変化閾値
) -> dict:
"""
ベースライン期間と現在期間の入力分布シフトを計算する。
コサイン距離の平均で分布変化を近似する。
"""
baseline_embeddings = [get_embedding(t) for t in baseline_texts]
current_embeddings = [get_embedding(t) for t in current_texts]
baseline_centroid = np.mean(baseline_embeddings, axis=0)
current_centroid = np.mean(current_embeddings, axis=0)
distance = cosine(baseline_centroid, current_centroid)
is_drifted = distance > threshold
return {
"distribution_shift": distance,
"is_drifted": is_drifted,
"threshold": threshold,
"alert": is_drifted,
"measured_at": datetime.utcnow().isoformat()
}
# 使用例
result = compute_distribution_shift(
baseline_texts=["...先週のリクエストサンプル..."], # 先週の100件
current_texts=["...今週のリクエストサンプル..."], # 今週の100件
threshold=0.05
)
if result["is_drifted"]:
print(f"[ALERT] 入力分布ドリフト検知: shift={result['distribution_shift']:.4f}")
# Slack通知・再評価トリガーを実行
ドリフト検知の結果がアラートを上げた場合の対応フローは以下の通りだ。
- 入力ドリフトの場合:ゴールデンデータセットに新しいパターンを追加し、再評価を実行してから判断する
- 出力品質の劣化の場合:基盤モデルのバージョン変更がないか確認し、プロンプトの調整またはfine-tuningを検討する
- モデルバージョン更新の場合:更新前と同じゴールデンデータセットで評価を走らせ、スコアの変化を定量確認してから本番利用を継続するか判断する
回帰検知の運用フロー:誰が・いつ・どう動くか
技術的な仕組みを整えても、「誰が最終判断するか」「どのアラートに即座に反応するか」が曖昧だと機能しない。以下に実際に使える運用フローを示す。
オフライン評価(CI)のフロー
- PRオープン:変更種別(プロンプト/モデル/ツール/コード)をPRテンプレートに明記する
- 自動評価実行:CIがゴールデンデータセットで評価を実行(所要時間:5〜15分が理想)
- 結果PRコメント:各指標のスコア変化(改善/中立/退行)をPRにコメント投稿
- 回帰ゲート判定:ハード閾値を超える退行 → CI fail(マージブロック)。ソフト閾値 → 警告コメントのみ(マージ可能だがレビュー必須)
- 人間レビュー:CI failの場合、担当エンジニアが退行の原因を特定して修正するか、意図的な変更であることをレビュアーが承認してオーバーライドする(オーバーライドは履歴を残す)
オンライン評価(本番監視)のフロー
- カナリア展開:新バージョンを5%のトラフィックに展開
- 24h監視:エラー率・品質スコア・レイテンシをリアルタイムでダッシュボードに表示
- 自動ロールバック条件:エラー率が現行比2倍超 / p99レイテンシが現行比30%超 / LLM-judgeスコアが0.80未満の場合、自動でトラフィックを0%に戻しSlack通知
- 段階的展開:24h後に問題なければ25% → 50% → 100%へ段階的に上げる
よくある失敗パターンと回避策
失敗1:閾値を厳しく設定しすぎてCI failが頻発する
評価指標を複数持つと、どれかが必ずちょっとズレてCIが常にfailし続け、やがてチームがCIを無視するようになる。回避策は「ハード閾値はタスク成功率1本に絞る」「他指標はソフト閾値(警告のみ)で運用する」ことだ。
失敗2:LLM-as-judgeをキャリブレーションせずにゲートに使う
モデルベースの評価器が「正確に見えるが実は人間の判断と乖離している」状態で回帰ゲートを設定すると、本当に重要な退行を見逃す。50件以上の人間アノテーション結果でキャリブレーションを実施してから、本番ゲートに採用すること。
失敗3:ゴールデンデータセットを一度作ったら更新しない
製品が成長するにつれてユーザーの使い方が変わり、最初に作ったデータセットと実際の本番トラフィックの分布が乖離していく。月次でデータセットの代表性を確認し、新しいパターンを追加するサイクルを作ることが重要だ。
失敗4:評価コストを見積もらずに全件LLM-judgeにする
100件のデータセットに対して高精度モデルでjudgeを実行すると、PRごとに相応のコストが発生し得る。1日10本のPRが走る開発体制では月数万円規模になることもある。CIで回す評価はまず決定論的チェック(コスト0)を最大化し、LLM-judgeは夜間のnightly evalに集中させるアーキテクチャが現実的だ。
フレームワーク・ツールの選び方(ツール非依存の観点から)
本記事はツール非依存のプロセス設計に焦点を当てているが、実装選択の参考として、ツール選定の判断軸だけ示す。
| 判断軸 | セルフホスト重視 | クラウド連携重視 |
|---|---|---|
| データの機密性 | 高(医療・金融・社内業務) | 中〜低 |
| エバル実行コスト | インフラコスト主体 | SaaSライセンス主体 |
| CI/CD統合の容易さ | GitHub Actions + Pythonスクリプトで完結できる | 既存CI/CDにSDKを追加するだけ |
| LLM-judgeの透明性 | モデル・プロンプト・スコアリングロジックを完全管理 | プラットフォーム依存(ブラックボックスリスクあり) |
| 適したフェーズ | MVP〜中規模(エンジニアが評価プロセスを理解したい段階) | 大規模・複数チーム(スケールとガバナンスを優先する段階) |
まず小さく始める場合は、独自Pythonスクリプト + GitHub Actionsで十分だ。評価プロセスを自分たちで理解し、ゴールデンデータセットの設計思想を確立した後に、専用ツールへの移行を検討するほうが長期的にうまくいく。GitHub Actions公式ドキュメントにはマトリクスジョブ・アーティファクト管理等、評価パイプラインに使える機能が豊富にある。
まとめ:継続的評価を組織のリリースプロセスに組み込む
AIエージェントの品質保証は、一度きりの評価では完結しない。プロセスとして継続する仕組みを組織のリリースフローに埋め込むことが本質だ。本記事で解説した要素を再整理する。
- ゴールデンデータセット:代表ケース・エッジケース・回帰ケースを含む20〜50件から始め、実障害を継続追加して育てる
- CI回帰ゲート:PR単位でオフライン評価を自動実行し、タスク成功率を中心とした閾値割れでマージをブロックする
- 評価指標:タスク成功率・ツール呼び出し精度・LLM-judgeスコアに加え、コスト・レイテンシも回帰対象に含める
- カナリアリリース:本番トラフィックの5〜10%から段階的に展開し、自動ロールバック条件を設定しておく
- ドリフト検知:入力・出力分布の週次監視を自動化し、閾値超過時に再評価をトリガーする
正直に言うと、このフルプロセスを一気に整備しようとすると挫折する。まずPR単位のCIと20件のゴールデンデータセットだけで始め、回帰を検知した経験を積みながら段階的に仕組みを厚くしていくのが現実的なアプローチだ。リリース後に問題が起きたときの対応はAIエージェント障害対応・オンコール運用ガイドも参照してほしい。
詳しくは Google Cloud MLOps: 機械学習の継続的デリバリーと自動化パイプライン も参考になる。
よくある質問(FAQ)
- Q. ゴールデンデータセットは何件から始めれば十分ですか?
- A. 20〜50件が現実的な出発点です。エージェントの変更が大きいほど少ない件数でも統計的に有意なシグナルが取れます。件数よりケースの多様性(代表・エッジ・回帰の3分類バランス)が重要です。
- Q. LLM-as-judgeの評価はどのモデルを使うべきですか?
- A. 評価対象のエージェントより高性能なモデルを使うのが原則です。ただしどのモデルを使っても必ず人間のアノテーションと突き合わせてキャリブレーションをしてから本番ゲートに採用してください。
- Q. 回帰ゲートの閾値はどう決めますか?
- A. まず現状の性能をベースラインとして計測し、そこから5〜10ポイント下をソフト閾値、15〜20ポイント下をハード閾値として設定する方法が運用しやすいです。固定値から始めるより相対値がおすすめです。
- Q. ドリフト検知はどのくらいの頻度で実行すべきですか?
- A. 週次バッチが現実的なスタート地点です。トラフィックが多い場合や変化の激しいドメインでは日次にしてもよいですが、アラートノイズが増えすぎないよう閾値調整が必要になります。
- Q. CI評価の実行時間が長くてPRレビューが遅くなります。どう短縮しますか?
- A. PR毎に回すチェックは高速な決定論的評価(JSON schema検証・文字列マッチ)に絞り、LLM-as-judgeによる重い評価は夜間のnightly evalにまわす分割が有効です。データセットも全件ではなくランダムサンプリング(例:50件中20件)を使うと速度と信頼性のバランスが取れます。
この記事を読んでAIエージェントの品質保証プロセスを整備したい方へ
UravationではAIエージェント導入・運用体制構築の研修・コンサルを行っています。継続的評価プロセスの設計から運用定着まで支援します。
AIエージェント運用シリーズ


