
結論:本番AIエージェントの障害は「気づいたら数十万円の請求が来ていた」「サイレントに品質が落ちていた」という形で発生する。アラートが鳴った後の初動オペレーション—重大度判定・ランブック実行・グレースフルデグレード・ポストモーテム—を事前に設計しておくことで、MTTRを大幅に短縮できる。
- 要点1:AIエージェント特有の障害モード(無限ループ・コストスパイク・サイレント品質劣化)は通常のサービス障害と検知・対処が異なる
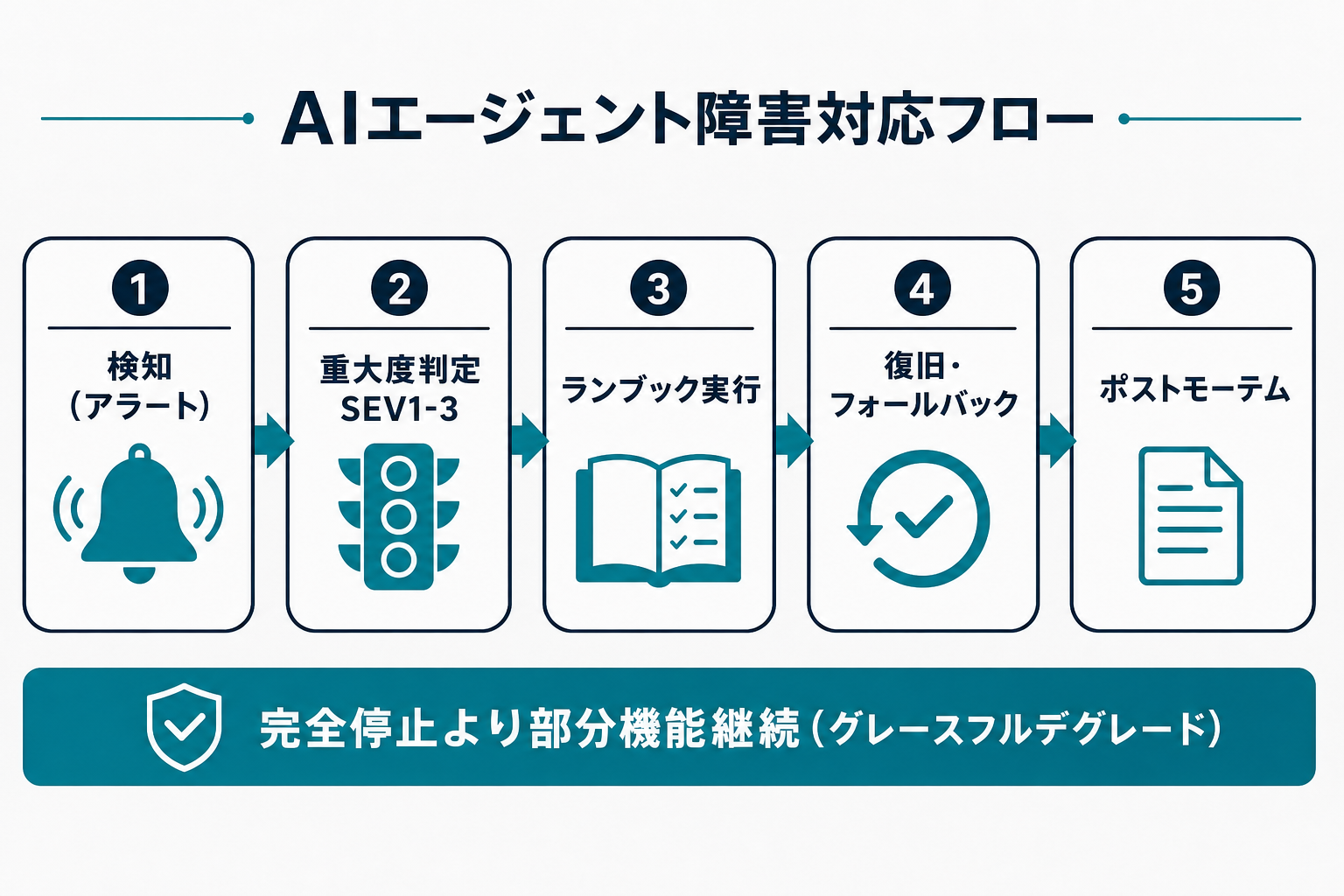
- 要点2:SEV1〜3の重大度分類を事前に決め、ランブックと紐づけることで初動のオペレーターが迷わない
- 要点3:サーキットブレーカーとグレースフルデグレードを実装しておくと、完全停止を回避しながら復旧時間を稼げる
対象読者:本番環境でAIエージェントを運用するSRE・プラットフォームエンジニア・開発チームリード
今日やること:自チームの直近インシデントを1件選び、本記事のランブックテンプレートに当てはめて整備を開始する
深夜2時、請求アラートで目を覚ます。ドキュメント要約エージェントが前夜からリトライループに入り、朝まで何千ものAPI呼び出しを繰り返していた——しかも、障害アラートは一件も鳴らなかった。こうしたシナリオは、AIエージェントを本番運用するチームにとって決して他人事ではない。
AIエージェントの障害は、従来のWebサービス障害と根本的に性質が違う。エラーを返さずに壊れ、成功レスポンスを返しながらコストを溶かし、HTTPステータス200のまま品質が劣化する。だからこそ「アラートが鳴った後に何をするか」をあらかじめ設計しておく必要がある。
モニタリングと計装の設計については既存記事(AIエージェントSREモニタリングガイド・OpenTelemetry/LangSmith/Phoenix観測ガイド)に譲る。本記事では「アラートが鳴った後」だけに絞る——重大度の判定から、ランブック実行、グレースフルデグレード、ポストモーテムまで、インシデントレスポンスの実務手順を解説する。
AIエージェント特有の障害モード7種
まず前提として、AIエージェントの障害が通常サービスと何が違うのかを整理しておく。通常のAPIサーバーは「落ちているか動いているか」の二値で判定しやすいが、AIエージェントは以下の7種類の障害モードを持つ。
| 障害モード | 概要 | 通常システムとの違い | 検知の難しさ |
|---|---|---|---|
| モデルAPI障害・過負荷 | Anthropic/OpenAI等のAPI側がエラー(529 overloaded、500 api_error、504 timeout等) | 自社インフラ外の依存性。ステータスページを別途確認必要 | 中(HTTP 5xxで検知可) |
| レート制限超過(429) | TPM/RPM上限を超えてリクエストが拒否される | トークン消費量は1リクエストごとに大きく変動するため予測が困難 | 中(429コードで検知可だが発生前兆が見えにくい) |
| 無限ループ・暴走(再帰的ツール呼び出し) | エージェントが同じツール呼び出しを繰り返し続ける | CPUスパイクではなくコスト・トークンがスパイクする形で現れる | 高(成功レスポンスを返し続けるため外形監視では気づけない) |
| コストスパイク | API課金が異常速度で増加 | 金銭的損害が直接発生。技術的障害でなく財務障害の側面を持つ | 高(リアルタイムコスト監視を別途実装しなければ翌朝まで気づけない) |
| プロンプトインジェクション起因の異常動作 | 外部入力(Webページ・ユーザー入力等)に悪意ある指示が含まれ、エージェントが意図しない行動を取る | セキュリティ障害。出力の内容審査が必要になる | 非常に高(動作は正常に見えるが意図が違う) |
| 出力品質の急低下(サイレント障害) | エラーは返さないが、生成物の品質が突然悪化する | SLAに「品質」を定義していないと検知不能 | 非常に高(HTTPレスポンスは200のまま) |
| コンテキスト溢れ | 会話・ツール呼び出し履歴がモデルのコンテキストウィンドウ上限に達する | ループが続くほど1ステップあたりのコストが指数的に増加する | 中(コンテキスト長をメトリクスとして監視しておく必要がある) |
特に「無限ループ」と「サイレント障害」は、通常のインフラ監視では絶対に検知できない。仮に4,000トークンのコンテキストがステップごとに倍増すると、5ステップ目には128,000トークンに達し、1ステップあたりのコストは32倍になる。エラーは出ないまま、課金だけが指数的に膨らむ。この障害モードの理解が、以降の対処設計の前提になる。
重大度分類(SEV1〜3)の決め方
インシデントレスポンスで最初にすべきことは重大度の判定だ。「とりあえず全員起こす」はオンコール疲弊の原因になる。AIエージェントでは、ユーザー影響・コスト影響・安全性影響の3軸で判断する。
| 重大度 | 定義 | コスト影響 | ユーザー影響 | 安全性影響 | 初動目標(TTR) | エスカレーション |
|---|---|---|---|---|---|---|
| SEV1 | サービス完全停止 or コストが異常暴走 or 安全性リスク | 予算上限の30%超/時 or 制御不能 | 全ユーザーが機能を使えない | 意図しない外部アクション実行・データ漏洩疑い | 15分以内に初動・1時間以内に仮復旧 | 担当エンジニア+CTO+経営判断が必要な場合は経営層 |
| SEV2 | 部分的機能停止 or コスト異常増加傾向 | 通常の200〜500%以内 | 特定機能・特定ユーザー層に影響 | なし | 30分以内に初動・4時間以内に仮復旧 | 担当エンジニア+チームリード |
| SEV3 | 品質低下・軽微な誤動作 | 通常の200%未満 | 体験が悪化するが機能は使える | なし | 翌営業日内に調査開始 | 担当エンジニアのみ |
AIエージェント特有のSEV1トリガーとして「コスト暴走」を必ず含めること。従来のサービス障害では財務インパクトが後から来るが、LLMエージェントはインシデント発生中にリアルタイムで課金が積み上がる。
また「プロンプトインジェクション起因の異常動作」は、コスト・ユーザー影響がゼロでも安全性フラグからSEV1として扱うべきだ。
ランブックの作り方:障害モード別テンプレート
ランブックとは「誰が読んでも同じ手順で動けるドキュメント」だ。オンコール担当が深夜に半分眠りながら見ることを想定して、判断の余地を極力排除した形式にする。
以下は実務で使えるランブック骨格の例だ。
ランブック例1:モデルAPI障害(上流プロバイダー障害)
# RUNBOOK: モデルAPI障害(上流プロバイダー障害)
## トリガー: HTTP 5xx / 529 overloaded / 504 timeout が5分以内に3回以上
## Step 1: 上流ステータス確認(2分以内)
1. https://status.anthropic.com/ を開く(Anthropicの場合)
2. インシデント掲示を確認 → あり=上流障害(Step 3へ) / なし=自社側の問題(Step 2へ)
## Step 2: 自社側原因の切り分け(5分以内)
- API keyのクォータ確認: Anthropic Console → Usage
- 最近のデプロイを確認: `git log --oneline -10`
- ローカルで最小リクエストを手動実行して再現確認
## Step 3: フォールバックモデルへの切替(10分以内)
- 設定ファイル / 環境変数の MODEL_ID を変更してデプロイ
- 例: claude-opus-4 → claude-sonnet-4-6 (軽量モデルへ降格)
- フォールバック先のコスト・品質トレードオフを承認する担当者を事前に決めておく
## Step 4: 状況をインシデントチャンネルに報告
- 発生時刻・影響範囲・現在の対応状況・次のアクションを投稿
## 復旧確認
- 正常レスポンス率 >99% が5分以上継続したことを確認してから解除
ランブック例2:無限ループ・コストスパイク
# RUNBOOK: 無限ループ / コストスパイク
## トリガー: 同一エージェントのAPI呼び出しが10分以内に50回以上 or
## コストが過去24hの平均の500%超(コスト監視Alertより)
## 即時対応(SEV1判定 → 5分以内)
1. エージェントプロセスを即時停止
- Kubernetes: `kubectl rollout pause deployment/agent-worker`
- Lambda: コンカレンシー制限を0に設定
- その他: サーキットブレーカーをFORCE_OPENに設定
2. 現在進行中のジョブを確認・キャンセル
- キューに積まれたジョブを確認してflush
3. 原因調査(停止後に実施)
- ループ開始直前のAgentの最終ステップを確認
- ツール呼び出し履歴のパターンを確認(同じtool_callが繰り返されているか)
4. 修正なしでは再起動しない
- ループの原因(ツールエラー時のリトライ設定 / プロンプトの指示 / 終了条件の欠如)を特定してから再開
ランブックのポイントは「Step番号と時間目標が明記されていること」と「判断が必要な箇所が最小化されていること」だ。「状況を見て対応する」という記述はランブックではなくメモにすぎない。
サーキットブレーカーとフォールバックの実装
ランブックで「停止する」「フォールバックする」と書いても、それを手動でやっていては深夜のインシデントに間に合わない。コードレベルでサーキットブレーカーを実装しておくことで、異常検知から自動遮断までを人間の介在なしに処理できる。
以下は概念的なPython実装例だ。本番環境では必ずテスト環境での動作確認を行うこと。
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
# 動作環境: Python 3.11+
import time
import threading
from enum import Enum
from dataclasses import dataclass, field
from typing import Callable, Any
class CircuitState(Enum):
CLOSED = "closed" # 正常動作中
OPEN = "open" # 遮断中(フォールバックに切替)
HALF_OPEN = "half_open" # 回復テスト中
@dataclass
class AgentCircuitBreaker:
"""AIエージェント用サーキットブレーカー"""
failure_threshold: int = 5 # 何回失敗でOPENにするか
recovery_timeout: float = 60.0 # OPEN → HALF_OPENの待機時間(秒)
max_iterations: int = 30 # 1タスクあたりの最大イテレーション数
max_cost_usd: float = 5.0 # 1タスクあたりの最大コスト(USD)
_state: CircuitState = field(default=CircuitState.CLOSED, init=False)
_failure_count: int = field(default=0, init=False)
_last_failure_time: float = field(default=0.0, init=False)
_lock: threading.Lock = field(default_factory=threading.Lock, init=False)
def call(self, func: Callable, *args, fallback: Callable = None, **kwargs) -> Any:
with self._lock:
# OPEN状態: 復旧タイムアウト経過後にHALF_OPENへ
if self._state == CircuitState.OPEN:
if time.time() - self._last_failure_time > self.recovery_timeout:
self._state = CircuitState.HALF_OPEN
else:
# まだ遮断中 → フォールバックを実行
if fallback:
return fallback(*args, **kwargs)
raise RuntimeError("Circuit OPEN: エージェントは現在停止中です")
try:
result = func(*args, **kwargs)
with self._lock:
# 成功したらリセット
if self._state == CircuitState.HALF_OPEN:
self._state = CircuitState.CLOSED
self._failure_count = 0
return result
except Exception as e:
with self._lock:
self._failure_count += 1
self._last_failure_time = time.time()
if self._failure_count >= self.failure_threshold:
self._state = CircuitState.OPEN
# SEV1アラートをここで発火する
self._alert_incident(str(e))
raise
def _alert_incident(self, error_msg: str):
"""インシデントチャンネルへの通知(実装はSlack/PagerDuty等に合わせる)"""
print(f"[INCIDENT ALERT] Circuit OPEN: {error_msg}")
ポイントは3つある。まず「失敗回数による遮断(circuit breaker)」と「イテレーション上限」と「コスト上限」を独立したガードとして実装すること。どれか1つが欠けていると必ずそこを抜けてくる。次に、OPEN状態でもフォールバック処理を返せるようにすること——ユーザーへのレスポンスが完全に止まるよりも、定型応答や人間エスカレーション誘導を返せる方がサービス継続性が上がる。最後に、遮断時には必ずアラートを発火する場所をコード内に明示的に確保しておくことだ。
グレースフルデグレード:機能縮退の設計
「エージェントが壊れたら全停止」ではなく、「できる範囲で動き続ける」設計がグレースフルデグレードだ。AIエージェントが実務に浸透したことで、この設計の重要性が急速に高まっている。
縮退のレイヤーを事前に定義しておくことが重要だ。以下に典型的な3段階を示す。
| 縮退レベル | 発動条件の例 | 動作 | ユーザー体験 |
|---|---|---|---|
| L1: モデル降格 | 主モデルが過負荷 / コスト閾値超過 | 高性能モデル → 軽量モデルへ自動切替(例: Opus → Sonnet → Haiku) | レスポンス品質がやや下がるが機能は継続 |
| L2: キャッシュ応答 | 連続エラー or レート制限超過 | 直近の類似クエリに対するキャッシュ済み回答を返す | 古い情報の可能性ありをUIで表示 |
| L3: 人間エスカレーション | エージェントが完全停止 or SEV1 | 「現在AIが応答できません。担当者が対応します」を返し、サポートキューに登録 | AIではなく人間が対応(SLAを別途定義) |
縮退レベルの切り替えは手動確認を挟まずに自動化するほうがよい。SEV1が発生して人間が確認してからL3に落とすまでに5分かかるなら、その間もユーザーはエラー画面を見ている。サーキットブレーカーのOPEN状態と縮退レベルを連動させることで、「壊れたら自動でL2、それも無理ならL3」というフローを無人で実行できる。
また、AIエージェント特有の縮退として「ツールアクセスの制限」がある。例えば、コードを実行するツールや外部APIを呼ぶツールに問題が発生した場合、「読み取りのみ」「テキスト生成のみ」に機能を絞ったエージェントとして動き続けることができる。完全停止より部分機能継続を優先する発想が重要だ。
オンコール運用:AIエージェント固有のシグナルとローテーション
AIエージェントのオンコールは、従来のインフラオンコールと見るべきシグナルが異なる。CPUやメモリではなく、以下を主要シグナルとして監視する。
- ツール呼び出し回数 / 分:正常時の基準値から3倍以上で警告、10倍以上でSEV1
- APIコスト / 時間:過去7日間の同曜日・同時刻の平均値と比較してスパイクを検出
- エージェントの「タスク完了率」:完了せず途中でエラー終了する率が上昇していないか
- 出力長の分布:突然短くなる(コンテキスト窓切れ)や異常に長くなる(ループの兆候)を検知
- 上流プロバイダーのステータス:status.anthropic.com / OpenAI status を定期ポーリング
オンコールローテーションを設計するとき、AIエージェント特有の懸念が1つある。エージェントの動作を理解するには、そのエージェントがどういう目的で・どういうツールを持ち・どんな失敗パターンがあるかを知っている必要がある。「誰でもオンコールできる」状態にするためにはランブックの整備が前提条件になる。ランブックがない状態でローテーションだけ回しても、深夜に何もできないオンコール担当が生まれるだけだ。
エスカレーションポリシーは以下の構造を推奨する。
- Tier 1(0〜15分):オンコール担当エンジニアが一人対応。ランブック手順を実行
- Tier 2(15〜30分):Tier 1が解決できない場合、チームリード or シニアエンジニアを呼ぶ
- Tier 3(30分〜):SEV1かつ財務・安全性影響がある場合、経営層に報告
エスカレーション先の連絡先(Slack ID・電話番号)をランブックに直接書いておくことで、深夜に「誰に電話するか調べる」という無駄な時間を排除できる。
よくある対応ミスと回避策
失敗1:原因特定前に再起動する
「とりあえず再起動して直ったからOK」は最悪のパターンだ。ループが止まっただけでループが起きた条件は変わっていないため、次のタスクで必ず再発する。停止 → 原因特定 → 修正 → 再起動の順を守ること。
失敗2:フォールバックモデルを決めていない
インシデント発生中に「どのモデルに切り替えるか」を議論し始めると、その間ずっとサービスが停止する。主モデル・フォールバックモデル・非常用の定型応答の3段階を事前に決め、コードに実装しておくこと。
失敗3:コストアラートを翌日通知にしている
クラウドのコストアラートは多くのチームが「日次集計 → 翌朝通知」で設定しているが、AIエージェントの暴走は数時間で壊滅的なコストになる。リアルタイムまたは15分間隔での監視に切り替えること。Anthropic ConsoleやOpenAI Dashboardにも使用量アラートの設定が用意されている。
失敗4:「モデルのせいにして終わる」ポストモーテム
「モデルがハルシネーションした」「APIが落ちた」を根本原因とするポストモーテムは再発防止にならない。「なぜそのハルシネーションを検知できなかったか」「なぜAPI障害時のフォールバックがなかったか」まで掘り下げることが必要だ。
ポストモーテム:AIエージェント障害の再発防止
ポストモーテム(事後分析)は、障害の再発を防ぐためのプロセスだ。SRE文化では「ブレームレス(非難なし)」原則が基本になっている(Google SRE Book: Postmortem Culture)。
AIエージェント特有のポストモーテムで押さえるべき観点を整理しておく。通常システムのポストモーテムは「誰が何をしたか」の時系列を軸に構成できる。しかしAIエージェントの場合、障害の原因が「モデルのアップデート」「プロンプトの微妙な変更」「外部ツールのAPI変更」「入力データの分布シフト」など複数のレイヤーに散在することが多い。
AIエージェントポストモーテムのテンプレート項目は以下が有効だ。
- インパクト概要:影響ユーザー数・影響時間・コスト・品質への影響(定量)
- タイムライン:障害発生〜検知〜初動〜復旧の時刻と担当者のアクション
- 根本原因(技術層・プロンプト層・運用層で分類):「モデル更新で動作が変わった」ならモデル層、「ランブックに手順がなかった」なら運用層に分類する
- 検知の遅れがあった場合、なぜ遅れたか:「このシグナルが監視対象になかった」という学びを書く
- 再発防止アクション:各アクションに担当者・期日・完了基準を明記。「監視を強化する」では実行されないので「Xメトリクスにアラートを追加する(担当:○○, 期日:○月○日, 完了基準:アラート発火テスト通過)」と書く
AIエージェント特有の再発防止アクションの典型例を挙げる。
- 「同じツールを10回以上連続で呼び出したらサーキットブレーカーが発動するように実装する」
- 「モデルAPIの新バージョンリリース時に自動でshadow testingを走らせ、品質回帰を検知する」
- 「コスト/時のリアルタイムアラートを15分間隔で設定し、過去7日間平均の300%超で通知する」
- 「今回未整備だった『コストスパイク時』のランブックを今月中に作成し、オンコール担当に周知する」
重要なのは、ポストモーテムを「過去を責める儀式」でなく「システムを改善するインプット」として扱うことだ。「プロンプトを直して終わり」のポストモーテムは根本原因に到達していない。プロンプトを直したことでなく、「なぜそのプロンプトの問題が本番投入前に発見できなかったか」まで問うことが非難なしの真の意味だ。継続的な品質検証の仕組みについてはAIエージェントの継続的評価とCI/CD回帰検知ガイドも参照してほしい。
まとめ:今日から始める3つのアクション
- 今日やること:自チームが運用中のエージェントを1つ選んで、「無限ループ」「コストスパイク」「モデルAPI障害」の3障害モードに対するランブックが存在するか確認する。なければ本記事のテンプレートを使って今日中に作成する
- 今週中:サーキットブレーカーとイテレーション上限のガードがコードに実装されているか確認し、実装されていなければ本記事のコード例を参考に追加する。合わせてリアルタイムコストアラートを15分間隔で設定する
- 今月中:オンコールローテーションのメンバー全員が各ランブックを手順通りに実行できるか、ドライランで確認する。不明点・追記事項をランブックに反映して、「深夜でも迷わず動ける」状態にする
あわせて読みたい:
- AIエージェントのSREモニタリング設計ガイド(計装・メトリクス設計の詳細)
- OpenTelemetry・LangSmith・Phoenix 観測ツール比較(可観測性ツールの選定)
参考・出典
- Postmortem Culture: Learning from Failure — Google SRE Book(参照日: 2026-06-08)
- Errors – Claude API Docs — Anthropic公式ドキュメント(参照日: 2026-06-08)
- Anthropic Status — 上流プロバイダーのステータスページ(参照日: 2026-06-08)
この記事を読んで導入イメージが固まってきた方へ
UravationではAIエージェント導入の研修・コンサルを行っています。
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』。
ご質問・ご相談は お問い合わせフォーム からお気軽にどうぞ。
AIエージェント運用シリーズ


