
結論: マルチターンのAIエージェントを作るとき、つまずく原因のほとんどは「状態(state)と会話履歴の扱い方」にあります。会話履歴は全部渡せばいいわけではなく、トークン上限とコストの制約のなかで「直近N件+要約」を組み合わせ、セッション単位で永続化・復元できる設計が必要です。
この記事の要点:
- 要点1: エージェントの状態は「会話履歴」「ツール実行の途中状態」「ユーザー文脈」の3つに分けて考えると整理しやすい
- 要点2: 会話履歴をそのまま無限に渡すことはできない。トークン上限とコストの制約から「直近N件」「要約」「ハイブリッド」の3戦略を使い分ける
- 要点3: LangGraphは
thread_id+ checkpointer、OpenAI Agents SDKはSQLiteSessionなど、主要フレームワークは状態管理を標準で備えている(2026年6月時点)
対象読者: マルチターンのチャットボット・AIエージェントを実装する開発者
難易度: 中級
読了時間: 約14分
「単発のプロンプトなら動くのに、会話を続けると前のやり取りを覚えていない」「履歴を全部渡したらトークン上限で落ちた」「サーバーを再起動したら会話が消えた」——マルチターンのエージェントを作り始めると、こうした壁に必ずぶつかります。
LLM自体はステートレスです。APIを叩くたびに、モデルは過去のやり取りを一切覚えていません。つまり「会話が続いているように見せる」仕事は、すべて私たち開発者の側の実装に委ねられています。ここを場当たり的に作ると、トークン超過・コスト爆発・再起動で履歴消失といった事故が次々起きます。
この記事では、AIエージェントの「状態・会話履歴・セッション管理」を、①状態とは何か ②会話履歴の保持と渡し方 ③セッションの管理 ④状態の永続化 ⑤割り込み・再開 という5つの観点から、実装イメージ付きで整理します。最後まで読めば、自前のマルチターンエージェントに必要な状態設計の全体像がつかめるはずです。
なお、本記事は「会話状態・セッション・履歴をどう管理するか」という実装の配管に焦点を当てます。「何を長期的に覚えておくか」というメモリ設計(短期・長期・エピソード記憶)については、AIエージェントのメモリ設計|Short/Long/Episodic実装ガイドで別途詳しく解説しています。あわせて読むと立体的に理解できます。
AIエージェントの「状態」とは何か — 3つの構成要素
まず「状態(state)」という言葉が指すものを分解します。マルチターンのエージェントが保持すべき状態は、大きく次の3つに分けられます。
| 状態の種類 | 中身 | 具体例 | 揮発性 |
|---|---|---|---|
| 会話履歴 | ユーザーとアシスタントのメッセージ列 | 「予約したい」「いつですか?」のやり取り | セッション中は保持 |
| ツール実行の途中状態 | 処理の進行度・中間結果・承認待ちフラグ | 「外部APIを呼んだ結果」「人の承認を待っている」 | 処理完了で破棄 or 永続化 |
| ユーザー文脈 | ユーザー固有の設定・属性・長期的な好み | 「言語は日本語」「過去に問い合わせた製品」 | セッションをまたいで保持 |
この3分類が重要なのは、それぞれ「どこに、いつまで保存するか」が違うからです。会話履歴はセッション中だけ手元に持てばよく、ユーザー文脈はセッションをまたいでDBに残す必要があります。ツールの途中状態は、エラーからの復帰や人の承認を挟む場合に永続化が必要になります。
LangGraphの設計はこの考え方をそのまま反映しています。同じスレッド内のやり取り(会話履歴・処理の途中状態)は「short-term memory」として checkpointer に保存され、ユーザーをまたいで残すデータ(ユーザー文脈)は「long-term memory」として Store に保存されます。状態を1つの塊として扱わず、寿命の違いで分けて設計するのが第一歩です。
この分け方を意識すると、よくある混乱が解けます。たとえば「ユーザーの名前」を会話履歴の中だけに持っていると、新しいスレッドを始めた瞬間に忘れてしまいます。名前のようにセッションをまたいで覚えておきたい情報は、会話履歴ではなくユーザー文脈(long-term側)に置くべきです。逆に「いまどのステップまで処理が進んだか」のような一時的な進行状態を long-term に書き込むと、不要なデータが永続層に溜まっていきます。「この情報はこの会話だけのものか、それともユーザーにずっと紐づくものか」を、保存する前に一度問いかける習慣をつけると、状態の置き場所を間違えにくくなります。
会話履歴の保持と渡し方 — 全部渡せない問題
LLMはステートレスなので、会話を続けるには「過去のメッセージを毎回プロンプトに入れて渡す」のが基本です。しかし、ここで最初の落とし穴に出会います。会話履歴をそのまま無限に渡すことはできません。
理由は2つあります。1つはコンテキストウィンドウ(トークン上限)です。モデルには入力できる最大トークン数があり、履歴が長くなれば必ず上限に達します。もう1つはコストです。多くのLLM APIは入力トークン数に比例して課金されるため、毎ターン全履歴を渡すと、会話が長引くほど1リクエストの料金が膨らみ続けます。
そこで、履歴の渡し方には主に3つの戦略があります。
| 戦略 | やること | 長所 | 短所 |
|---|---|---|---|
| 全部渡す | 毎回すべての履歴を渡す | 実装が単純・情報欠落なし | すぐトークン上限・コスト増 |
| 直近N件 | 最新のNメッセージ(または直近Mトークン)だけ渡す | シンプル・トークン量が安定 | 古い文脈が落ちる |
| 要約 | 古い履歴をLLMで要約して圧縮 | 長い会話でも文脈を保てる | 要約のための追加API・情報ロス |
実務では、これらを組み合わせた「ハイブリッド」がよく使われます。直近のやり取りは原文のまま渡し、それより古い部分は要約して1つのシステムメッセージに畳む、という方式です。下は最小限の擬似コードです。
def build_messages(history, system_prompt, max_recent=10):
# 直近 max_recent 件はそのまま使う
recent = history[-max_recent:]
old = history[:-max_recent]
messages = [{"role": "system", "content": system_prompt}]
# 古い履歴があれば要約してシステムメッセージに畳む
if old:
summary = summarize_with_llm(old) # 別のLLM呼び出しで要約
messages.append({
"role": "system",
"content": f"これまでの会話の要約:n{summary}"
})
messages.extend(recent)
return messages
どこで要約に切り替えるかは「トークン数のしきい値」で判断するのが定石です。たとえば履歴が8,000トークンを超えたら、古い半分を要約に置き換える、といった具合です。この「履歴をどう圧縮し、何を残すか」という設計はコンテキストエンジニアリングそのものであり、より踏み込んだ圧縮・予算設計はコンテキストエンジニアリング完全ガイドで詳しく扱っています。
注意点として、要約は万能ではありません。要約のたびに細部の情報が失われるため、「3つ前に伝えた住所」のような具体的事実が消えることがあります。固有名詞・数値・ユーザーの明示的な指示は、要約に畳まず別途キーバリューで保持する、といった補強が必要です。
OpenAIのResponses APIのように、サーバー側で会話状態を管理する仕組みもあります。previous_response_id に直前のレスポンスIDを渡すと、過去のやり取りをAPI側がつないでくれるため、クライアントで全履歴を組み立てる手間が減ります(2026年6月時点)。ただしこの場合でも、トークン課金や上限の制約からは逃れられない点は同じです。サーバー側に状態を預ける方式は実装が楽になる反面、「どの履歴がどう渡っているか」がブラックボックスになりやすいので、コストやプロンプトの中身を厳密にコントロールしたい場合は、自前で履歴を組み立てる方式を選ぶ判断もあります。
もう1つ、戦略を選ぶ前に押さえておきたいのが「何トークンまで許容するか」というトークン予算(budget)の考え方です。1リクエストに使えるトークンを「システムプロンプト+要約+直近履歴+ツール定義+出力余白」に配分し、その合計が上限を超えないように設計します。たとえば上限の半分を履歴に割り当てると決めておけば、履歴が膨らんでも自動的に古い部分を要約に回す、という判断基準が明確になります。逆にこの予算を決めずに「とりあえず履歴を全部入れる」実装にすると、ユーザーごと・会話の長さごとにトークン量が読めなくなり、コストの上振れや突然のエラーを招きます。
実装上のもう一つのコツは、履歴の保持と「モデルに渡す形」を分けて持つことです。データベースには会話の全文を残しておき、モデルに渡すときだけ要約・間引きを適用する、という二段構えにします。こうすると、後から「やはり古い情報も参照したい」となったときに原文へ戻れますし、要約ロジックを改善しても過去ログを失わずに済みます。永続化された全文(記録用)と、毎ターン組み立てるプロンプト(消費用)は別物として扱うのが安全です。
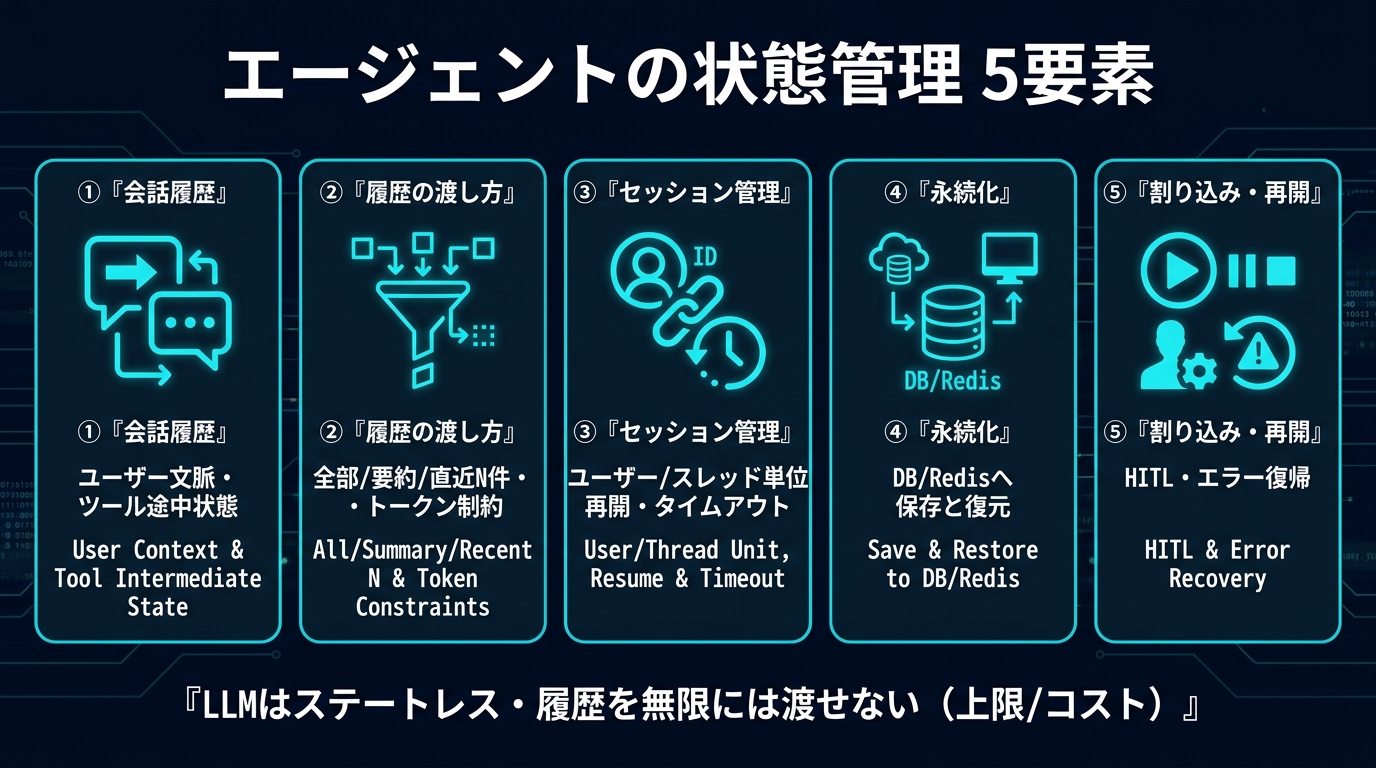
セッションの管理 — ユーザー/スレッド単位で履歴を分ける
会話履歴を保持できても、それが「誰の、どの会話か」を区別できなければ、複数ユーザーの履歴が混ざってしまいます。これを防ぐのがセッション管理です。
セッションとは「一連の会話を識別する単位」で、通常はユーザーIDやスレッドIDで区切ります。チャットアプリなら「ユーザーAのスレッド1」「ユーザーAのスレッド2」「ユーザーBのスレッド1」をそれぞれ別の状態として扱う、ということです。
主要フレームワークは、このセッション識別を標準で備えています。
| フレームワーク | セッション識別 | 履歴の取得・操作 |
|---|---|---|
| LangGraph | config={"configurable": {"thread_id": "..."}} |
graph.get_state(config) で StateSnapshot を取得 |
| OpenAI Agents SDK | SQLiteSession("session_id") |
session.get_items() / add_items() / clear_session() |
LangGraphでは、グラフ呼び出し時に thread_id を渡すだけで、その会話の状態が自動的に分離・保存されます。同じ thread_id で呼び出せば前回の続きから、別の thread_id なら新しい会話として扱われます(2026年6月時点)。
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, MessagesState
# checkpointer を渡してグラフをコンパイル
graph = builder.compile(checkpointer=InMemorySaver())
# thread_id ごとに会話状態が分離される
config = {"configurable": {"thread_id": "user-123-chat-1"}}
graph.invoke(
{"messages": [{"role": "user", "content": "こんにちは"}]},
config,
)
# 同じ thread_id なら前回の続きから
graph.invoke(
{"messages": [{"role": "user", "content": "さっきの話の続きで"}]},
config,
)
# 現在の状態スナップショットを取得
snapshot = graph.get_state(config)
セッション管理では、識別だけでなく「再開」と「タイムアウト」の設計も必要です。実装時に決めておくべきポイントを整理します。
- 再開(resume): ユーザーが離脱して戻ってきたとき、同じセッションIDで状態を引き当てられるようにする。IDの採番・保存方法(Cookie・JWT・DBのユーザー紐付け)を先に決める。
- タイムアウト(timeout): 一定時間アクセスのないセッションをどう扱うか。完全に破棄するのか、要約だけ残してアーカイブするのかを決める。無期限保持はストレージとプライバシーの両面でリスクになる。
- 明示的なクリア: ユーザーが「会話をリセット」したいとき用に、履歴を消す導線(
clear_session()相当)を用意する。
OpenAI Agents SDKのセッションも同じ思想です。SQLiteSession はデフォルトではインメモリ(プロセス終了で消える)ですが、ファイルパスを渡すと永続化されます。RedisSession を使えば、複数サーバーにスケールアウトした構成でもセッションを共有できます。
状態の永続化 — DB/Redisへの保存と復元
インメモリで状態を持つと、プロセスが落ちたり再起動したりした瞬間にすべての会話が消えます。プロトタイプならそれでもよいですが、本番では状態を外部ストレージに永続化する必要があります。
LangGraphでは、この役割を checkpointer(チェックポインター)が担います。グラフが1ステップ(super-step)進むたびに、状態の完全なスナップショットがチェックポイントとして保存されます。バックエンドはクラスを差し替えるだけで切り替えられます。
| checkpointer クラス | バックエンド | 適した用途 |
|---|---|---|
InMemorySaver |
プロセスメモリ | 開発・テスト(永続化なし) |
SqliteSaver |
SQLite | 単一プロセスのプロトタイプ |
PostgresSaver / AsyncPostgresSaver |
PostgreSQL | 本番・マルチワーカー構成 |
RedisSaver / MongoDBSaver |
Redis / MongoDB | 既存インフラに合わせて選択 |
本番ではデータベースバックエンドの checkpointer を使うのが基本です。下はPostgreSQLを使う例です。
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://user:pass@localhost:5432/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # 初回はテーブル作成が必要
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "user-123-chat-1"}}
graph.invoke({"messages": [...]}, config)
# サーバーを再起動しても、同じ thread_id で続きから再開できる
ここで重要なのが、前述した「状態の3分類」と保存先の対応です。会話履歴とツールの途中状態はスレッド単位の checkpointer(short-term)に、ユーザーをまたいで残すべきユーザー文脈は Store(long-term)に保存します。LangGraphでは InMemoryStore / PostgresStore などがあり、データは (user_id, "memories") のようなタプルの名前空間(namespace)で整理されます。
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("user-123", "preferences")
# ユーザー固有データを保存(セッションをまたいで残る)
store.put(namespace, "language", {"value": "ja"})
# 別セッションでも取り出せる
pref = store.get(namespace, "language")
OpenAI Agents SDKでも、セッションをファイルベースのSQLiteにすれば同様に永続化されます。AdvancedSQLiteSession を使うと、会話のブランチ(分岐)や、ターンごとのトークン使用量の記録といった高度な管理もできます(2026年6月時点)。session.get_items() で全履歴を取り出し、session.add_items() で手動でメッセージを足し、session.pop_item() で直前の発言を取り消す、といった操作が用意されているため、履歴の細かい編集も実装しやすくなっています。
ストレージ・バックエンドの選び方
「永続化が必要」と分かっても、SQLite・PostgreSQL・Redisのどれを選ぶかで迷うことが多いはずです。判断軸は「プロセスが1つか複数か」「読み書きの頻度」「運用のしやすさ」の3つです。
| バックエンド | 向いている構成 | 特徴・注意点 |
|---|---|---|
| SQLite | 単一プロセス・プロトタイプ | セットアップ不要・ファイル1つで完結。複数サーバーからの同時書き込みには不向き |
| PostgreSQL | 本番・マルチワーカー | JSONBで複雑な状態を保存でき、トランザクション整合性も担保。本番の第一候補 |
| Redis | 高頻度アクセス・スケールアウト | 高速で水平スケールに強い。永続化設定(AOF/RDB)を誤ると再起動で消える点に注意 |
迷ったら、開発はSQLite(またはインメモリ)、本番はPostgreSQL、という標準ルートで問題ありません。アクセスが非常に多くレイテンシをさらに詰めたいときに、セッションのキャッシュ層としてRedisを足す、という順序が現実的です。LangGraphもOpenAI Agents SDKも、バックエンドはクラスや接続先を差し替えるだけで切り替えられる設計になっているため、最初からPostgreSQL前提で過剰設計する必要はありません。まずは動かし、負荷が見えてから移行するアプローチで十分です。
もう1点、本番運用ではマイグレーション(テーブル作成・スキーマ更新)を忘れずに。LangGraphの PostgresSaver は初回に checkpointer.setup() を呼んでテーブルを作る必要があり、これを飛ばすと実行時にテーブル不在のエラーになります。デプロイ手順にスキーマ初期化を組み込んでおくと、環境ごとの取りこぼしを防げます。
割り込みと再開 — Human-in-the-loopとエラー復帰
マルチターンのエージェントでは、処理の途中で「いったん止めて、後で再開する」場面がよくあります。代表例が2つあります。
1つは Human-in-the-loop(人による承認)です。たとえば「外部にメールを送る」「データを削除する」といった取り返しのつかない操作の前で、エージェントを一時停止し、人の承認を待ってから再開します。もう1つは エラーからの復帰です。外部APIがタイムアウトした、レート制限に当たった、といった場合に、最後のチェックポイントから処理をやり直します。
どちらも「状態を永続化しておく」ことが前提です。途中状態がメモリにしかなければ、停止した瞬間に進捗が消えてしまい、再開できません。チェックポイントがあれば、止まったところから状態を復元して続きを実行できます。
# 擬似コード: 承認を挟んで再開する流れ
state = run_until_checkpoint(input) # 危険な操作の直前で停止
save_checkpoint(thread_id, state) # 途中状態を永続化
# ── ここで処理は一旦終了。人の承認を待つ ──
if user_approved(thread_id):
state = load_checkpoint(thread_id) # 保存した状態を復元
resume_from_checkpoint(state) # 続きを実行
else:
rollback(thread_id) # 拒否されたら巻き戻し
LangGraphでは、この停止・再開を interrupt と checkpointer の組み合わせで実現します。承認ゲートをどこに置くか、承認疲れをどう避けるかといった設計の勘どころは、AIエージェントのHuman-in-the-loop設計ガイドでより詳しく解説しています。
割り込み・再開を設計するときは、再開時に「どの時点の状態に戻すか」を明確にしておくことが大切です。直前のチェックポイントに戻すのか、特定の安全な地点まで巻き戻すのかで、ユーザー体験もデータ整合性も変わります。たとえば外部APIへの書き込みが途中で失敗した場合、単純に最後のチェックポイントから再実行すると、同じ書き込みを二重に行ってしまう恐れがあります。再開処理には冪等性(同じ操作を複数回行っても結果が変わらない性質)を持たせるか、すでに完了した副作用をスキップする仕組みを用意しておくと安全です。状態の永続化は「止めて再開できる」だけでなく「正しく再開できる」ところまで設計して、はじめて本番で使えるものになります。
【注意】状態管理でハマりやすいポイント
最後に、実装でつまずきやすい落とし穴を4つ挙げます。
失敗1: インメモリのまま本番投入
❌ InMemorySaver / インメモリの SQLiteSession のまま本番に出す
⭕ 本番は必ずDB/Redisバックエンドに切り替える。再起動・スケールアウトで履歴が消える事故を防ぐ
失敗2: 履歴を全部渡し続ける
❌ 毎ターン全履歴を渡し、長い会話でトークン上限・高額課金に直面する
⭕ 直近N件+要約のハイブリッドで、トークン量を一定範囲に抑える
失敗3: セッションIDの設計が後付け
❌ あとからユーザー単位の分離が必要になり、混ざった履歴を分割する羽目になる
⭕ 最初からユーザーID×スレッドIDでセッションを区切る前提で設計する
失敗4: 状態を無期限に保持
❌ すべての会話を永久に残し、ストレージ肥大とプライバシーリスクを抱える
⭕ タイムアウト・アーカイブ・削除のポリシーを先に決める。個人情報の保持期間にも配慮する
まとめ: 今日から始める3つのアクション
AIエージェントの状態管理は、「状態を寿命で3分類する → 履歴の渡し方を決める → セッションで分離する → 永続化する → 割り込み・再開を設計する」という順で組み立てると見通しがよくなります。LLMがステートレスである以上、ここは開発者が責任を持って設計する領域です。
- 今日: 自分のエージェントで「会話履歴・ツールの途中状態・ユーザー文脈」をどこに、いつまで保存しているかを書き出して棚卸しする。
- 今週中: 履歴の渡し方を「直近N件+要約」のハイブリッドに切り替え、トークン量がセッション長に依存しないようにする。
- 今月中: checkpointer/セッションを本番向けにDB(PostgreSQL等)バックエンドへ移行し、再起動しても会話が継続することを確認する。
あわせて読みたい:
- AIエージェント実装ロードマップ|RAG・実行・運用の必須技術 — 状態管理を含む実装全体の地図
- ストリーミング応答 実装ガイド|SSE・トークン逐次表示 — マルチターンUXのもう一つの要
AIエージェント・ツールの最新情報をキャッチアップしたい方へ
Agent Labでは、週1回のニュースレターでAIツールの最新比較・活用事例をお届けしています。
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』(SBクリエイティブ)。
ご質問・ご相談は お問い合わせフォーム からお気軽にどうぞ。
参考・出典
- Add and manage memory(Memory) — LangChain 公式ドキュメント(参照日: 2026-06-05)
- LangGraph Persistence(Checkpointers / Threads / Store) — LangGraph 公式ドキュメント(参照日: 2026-06-05)
- Sessions(SQLiteSession / RedisSession) — OpenAI Agents SDK 公式ドキュメント(参照日: 2026-06-05)
- Managing conversation state(previous_response_id) — OpenAI 公式ドキュメント(参照日: 2026-06-05)


