
「埋め込みモデルもベクトルDBもちゃんと選んだのに、なぜか肝心の答えが出てこない」——RAGを運用していると、必ずこの壁にぶつかります。
先日、社内のナレッジ検索を構築したとき、まさにこれが起きました。質問と意味的には近いのに、本当に欲しい1件が top-k の5位以下に埋もれ、生成モデルがそれを拾わない。embedding を上位モデルに替えても、改善幅は数パーセント程度でした。
この経験から分かったのは、retrieval(検索)の精度には、埋め込みモデルの選定だけでは越えられない頭打ちがあるということです。そこを押し上げるのが リランク(rerank) と ハイブリッド検索 という、2段階で精度を稼ぐ設計です。本記事では、retrieval が頭打ちになる原理から、リランカー主要モデルの比較(Cohere / Jina / Voyage / OSS)、ハイブリッド検索とRRFの仕組み、最小実装コード、評価、コストのトレードオフまで、検索精度を上げる実装に絞って解説します。情報はすべて2026年6月時点で公式ドキュメントを確認したものです。
なぜ retrieval だけでは精度が頭打ちになるのか
典型的なRAGの検索は、クエリと文書を同じ埋め込みモデルでベクトル化し、コサイン類似度で近い順に top-k 件を取ってくる——いわゆるバイエンコーダ(bi-encoder)方式です。速くてスケールしますが、構造上どうしても取りこぼしが出ます。
原因は大きく3つあります。
- top-k の打ち切り問題:top-5 や top-10 で切ると、本当に必要な1件が k+1 位にあったとき生成モデルに届きません。k を大きくすればコンテキストがノイズで膨らみ、かえって回答品質が落ちます。
- 「意味は近いが無関係」の混入:埋め込みはクエリと文書を別々にベクトル化するため、相互作用を見ていません。「Pythonの非同期処理」と「Pythonの型ヒント」は意味空間では近いですが、答えとしては別物です。
- 固有名詞・レアワードの弱さ:型番・社内用語・エラーコードのような低頻度語は密ベクトルだと薄まりやすく、完全一致してほしい場面で取りこぼします。
これらは埋め込みモデルを上位機種に替えても根本的には解けません(埋め込み選定そのものは埋め込みモデル選定ガイドで扱っています)。本記事は「埋め込みは適切に選んだ前提で、その先をどう詰めるか」がテーマです。解決の方向性は2つ——①取ってきた候補を後から賢く並べ替える(リランク)、②違う原理の検索を足し合わせて取りこぼしを減らす(ハイブリッド検索)。順に見ていきます。
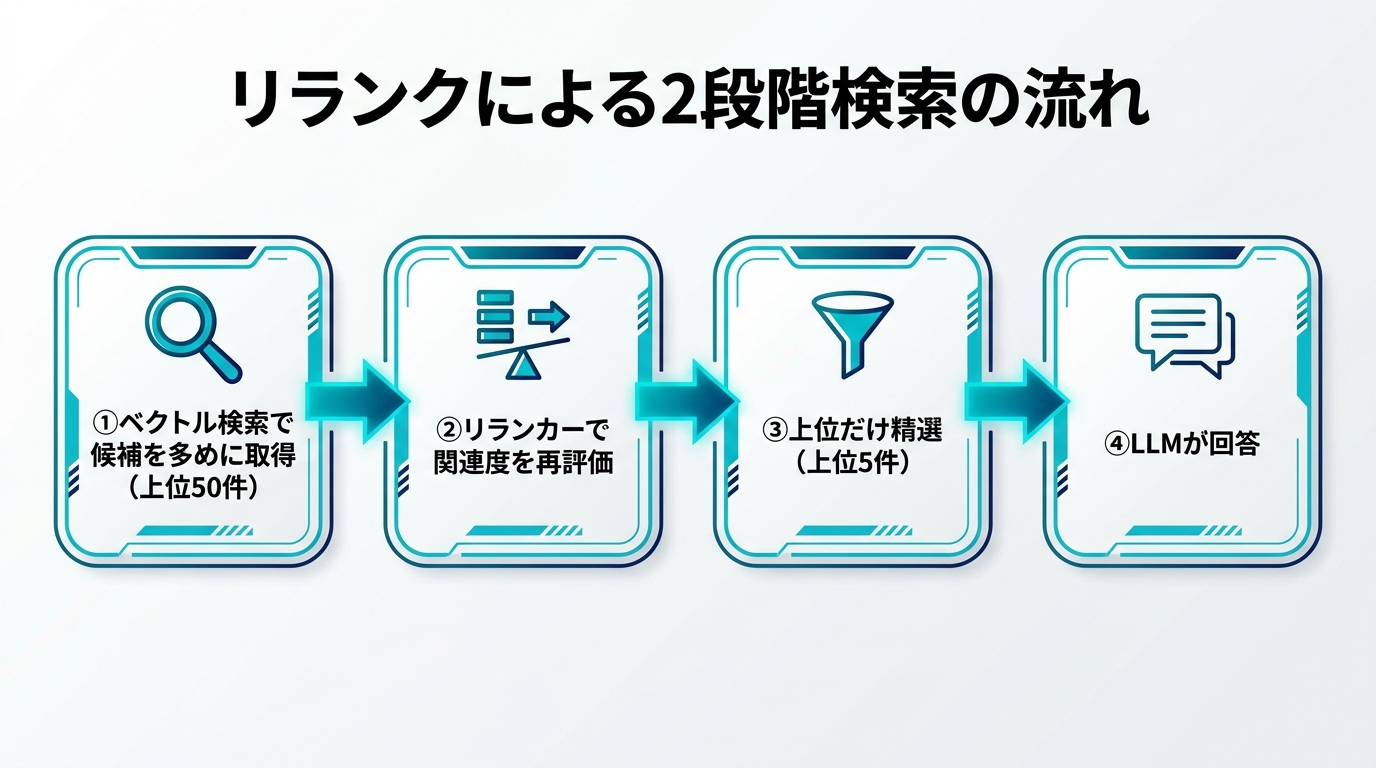
リランク(rerank)とは — 2段階検索で精度を稼ぐ
リランクは、「粗く多く取る → 精密に並べ替える」という2段階構成です。
- 1段目(retrieval):ベクトル検索やキーワード検索で、候補を多めに(例:top-50〜100件)ざっくり取る。ここは速度重視。
- 2段目(rerank):取った候補をクロスエンコーダ(cross-encoder)で1件ずつクエリと突き合わせ、関連度スコアを付け直す。ここは精度重視。
- 絞り込み:付け直したスコアの上位 N 件(例:top-5)だけを生成モデルに渡す。
カギは2段目のクロスエンコーダです。バイエンコーダがクエリと文書を別々にベクトル化するのに対し、クロスエンコーダはクエリと文書を1つの入力として同時にモデルに通し、フルアテンションで相互作用を見ます。BAAIの公式説明でも「cross-encoder will perform full-attention over the input pair, which is more accurate than embedding model(bi-encoder)but more time-consuming」とされ、精度は高いが遅いというトレードオフが明記されています(2026年6月時点)。だから全文書をクロスエンコーダで採点するのは非現実的で、1段目で候補を絞ってから2段目に渡す役割分担が2段階検索の本質です。
リランクで何が改善するのか
- 1段目で k+1 位以降に沈んでいた正解を、多めに取った候補プールから拾い直せる
- 「意味は近いが無関係」をクロスアテンションで弾ける
- 生成モデルに渡すコンテキストを少数の高関連文書に絞れるため、ノイズとトークン消費が減る
ただしリランカーは魔法ではありません。1段目の候補プールに正解がそもそも入っていなければ、リランクで上位に持ち上げることは原理的に不可能です。だから「1段目で取りこぼしを減らす」ハイブリッド検索と併用する価値が出てきます(後述)。
主要リランカー比較(Cohere / Jina / Voyage / OSS)
リランカーは「APIで使うマネージド型」と「自前でホストするOSS型」に大別できます。2026年6月時点で公式に確認できた主要どころを整理します。価格・モデル名は変動が速いため、導入前に必ず各公式ページで最新を確認してください。
API型(マネージド)
| 提供元 | 主なモデル(2026年6月時点) | 課金単位 | 多言語 | ホスティング |
|---|---|---|---|---|
| Cohere | Rerank 4.0(fast / pro)、Rerank 3.5 | 検索回数ベース(Rerank 3.5 は $2.00 / 1,000 searches。1 search = 1クエリ+最大100文書) | 100言語以上 | API / Azure / AWS / Oracle 等 |
| Jina AI | jina-reranker-v3(0.6Bパラメータ)、jina-reranker-m0、v2-base-multilingual | トークンベース(料金は公式要確認) | 100言語以上 | API / Elastic / AWS / Azure / GCP / Hugging Face |
| Voyage AI | rerank-2.5、rerank-2.5-lite、rerank-2 | 入力トークンベース(rerank-2.5 は $0.05 / 1M input tokens、rerank-2-lite は $0.02 / 1M) | 多言語対応 | API(MongoDB傘下) |
ポイントを補足します。いずれも2026年6月時点で各公式ページを確認した値です。
- Cohere Rerank 4.0:2025年12月にリリースされた最新世代で、fast と pro の2変種があります。Rerank 3.5 は $2.00 / 1,000 searches という検索回数課金で、1 search はクエリ+最大100文書まで。文書が500トークンを超えるとチャンク分割され、それぞれが1文書としてカウントされる点に注意。Rerank 4.0 の価格は提供プラットフォームにより異なるため公式で要確認。
- Jina Reranker v3:Qwen3-0.6Bベースの listwise アーキテクチャで、131Kトークンの長文脈に対応し、最大64文書を同時処理。公称で BEIR の nDCG@10 = 61.94、v2 比 4.88% 改善とされています。Hugging Face 配布の重みは CC-BY-NC 4.0(非商用)ライセンスのため、商用利用はAPI経由が基本です。
- Voyage rerank-2.5:入力トークン単価 $0.05 / 1M、最大32Kトークン入力に対応。同価格の rerank-2 を 1.85% 上回るとされ、無料枠は最新リランカーで2億トークン。
OSS型(自前ホスト)
レイテンシやデータ持ち出しを自分で握りたい場合、OSSのクロスエンコーダを自前GPUで動かす選択肢があります。代表格が BAAI/bge-reranker-v2-m3 です。
- bge-m3 をベースにした多言語リランカーで、クエリ+文書ペアを入力し、関連度スコア(logits → sigmoid で0〜1に正規化)を直接出力します。
- 最大512トークン、FP16 / BF16 推論に対応し軽量。Hugging Face の
sentence-transformers/FlagEmbeddingから読み込めます(2026年6月時点)。 - API課金が発生しない代わりに、GPUコストと運用(バッチング、スケーリング)を自分で負担します。
使い分けの目安:まず精度と立ち上げ速度を優先するならAPI型(Cohere / Voyage / Jina)。データを外に出せない、または大量リクエストでトークン課金が重くなるならOSS型を自前ホスト、という分岐が基本です。
リランク導入の最小実装
ここでは「すでにベクトル検索で候補を取れている」前提で、その候補をリランクで並べ替える最小コードを示します。OSSの bge-reranker-v2-m3 を使うパターンと、Cohere API を使うパターンの2つです。
OSSクロスエンコーダで並べ替える
1段目で取った候補(クエリと文書のペア)をクロスエンコーダに渡し、スコア順に並べ替えます。手順は次の通りです。
- 必要パッケージをインストールする(
pip install sentence-transformers)。 - bge-reranker-v2-m3 を CrossEncoder として読み込む。
- 1段目で取得済みの候補文書リストを用意する(ここでは固定値で例示)。
- クエリと各文書のペアを作り、まとめて採点する。
- スコアの降順に並べ替え、上位 N 件だけ生成モデルに渡す。
# 動作環境: Python 3.11+, sentence-transformers>=3.0.0, torch
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from sentence_transformers import CrossEncoder
# bge-reranker-v2-m3 はクロスエンコーダ(query-document ペアを採点)
reranker = CrossEncoder("BAAI/bge-reranker-v2-m3", max_length=512)
query = "RAGの検索精度を上げる方法は?"
# 1段目(ベクトル検索)で取得済みの候補。実際はベクトルDBから top-50 等を渡す
candidates = [
"リランクは候補を取り直して並べ替える2段階検索の手法です。",
"Pythonの型ヒントは静的解析に役立ちます。",
"ハイブリッド検索は密ベクトルと疎ベクトル(BM25)を組み合わせます。",
]
# クエリ × 各文書のペアをまとめて採点
pairs = [[query, doc] for doc in candidates]
scores = reranker.predict(pairs) # 各ペアの関連度スコア
# スコア降順に並べ替えて上位を採用
ranked = sorted(zip(candidates, scores), key=lambda x: x[1], reverse=True)
top_n = ranked[:2] # 上位2件だけ生成モデルに渡す
for doc, score in top_n:
print(f"{score:.4f} {doc}")
- ポイント:
predict()はペアごとのスコアを返すだけで、並べ替えは自前で行います。上位 N(top_n)を絞ることで、生成モデルに渡すノイズを減らせます。 max_lengthは512が上限。長文はチャンク分割してから渡してください。- GPUが使えるなら自動で利用されます。CPUのみだと候補数が増えるほど遅くなるので、1段目で取る候補数(top-k)とのバランスが重要です。
Cohere Rerank API で並べ替える
マネージドAPIなら自前GPUは不要です。Cohereの場合の手順は次の通りです。
pip install cohereでSDKを入れる。- APIキーを環境変数(
CO_API_KEY)から読み込む(ハードコード禁止)。 - クライアントを初期化する。
- クエリと候補文書リストを
rerankに渡し、上位件数(top_n)を指定する。 - 返ってきた
indexを使って元の文書を並べ替える。
# 動作環境: Python 3.11+, cohere>=5.0.0
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
import os
import cohere
# APIキーは環境変数から(コードにハードコードしない)
co = cohere.ClientV2(api_key=os.environ["CO_API_KEY"])
query = "RAGの検索精度を上げる方法は?"
candidates = [
"リランクは候補を取り直して並べ替える2段階検索の手法です。",
"Pythonの型ヒントは静的解析に役立ちます。",
"ハイブリッド検索は密ベクトルと疎ベクトル(BM25)を組み合わせます。",
]
# モデル名は2026年6月時点。最新は公式ドキュメントで要確認
resp = co.rerank(
model="rerank-v3.5",
query=query,
documents=candidates,
top_n=2, # 上位2件だけ返してもらう
)
for r in resp.results:
print(f"{r.relevance_score:.4f} {candidates[r.index]}")
- ポイント:APIは並べ替え済みの結果を
index(元配列での位置)とrelevance_scoreで返します。top_nで返却件数を絞れます。 - 課金は「検索回数」ベース(Rerank 3.5 は $2.00 / 1,000 searches)。1リクエストで最大100文書までが1 searchなので、1段目で取る候補数を100以内に収めるとコスト予測がしやすくなります。
- 500トークン超の文書はチャンク分割されカウントが増えるため、長文書を多数渡すと想定よりコストが膨らみます。
ハイブリッド検索とは — 密ベクトル+疎ベクトル(BM25)とRRF
リランクが「並べ替え」で精度を稼ぐのに対し、ハイブリッド検索は「1段目の取りこぼしそのものを減らす」アプローチです。
仕組みはシンプルで、原理の異なる2種類の検索を並列に走らせて結果を統合します。
- 密ベクトル検索(dense):埋め込みによる意味検索。言い換え・概念的な近さに強い。
- 疎ベクトル検索(sparse):BM25 や SPLADE のような語彙ベースの検索。型番・固有名詞・レアワードの完全一致に強い。
密だけだと固有名詞を、疎だけだと言い換えを取りこぼす。両方走らせて足せば互いの弱点を補える、という発想です。
BM25 と SPLADE の違い
- BM25:古典的なキーワード検索アルゴリズム。語の出現頻度とレア度で重み付けする。完全一致に強いが、言い換えや表記揺れには弱い。
- SPLADE:BERTベースで「学習された疎ベクトル」を作る手法。元の語に加えて関連語へ重みを展開(expansion)するため、純粋なBM25より語彙の取りこぼしが減ります。Pineconeの解説では、キーワード認識が重要な検索で密モデルを上回る場面があるとされています(2026年6月時点)。
RRF(Reciprocal Rank Fusion)で統合する
密と疎、2つの検索結果をどう1本にまとめるか。ここで広く使われるのが RRF(Reciprocal Rank Fusion) です。
RRFはスコアの絶対値ではなく順位(rank)だけを使って融合します。各検索結果の順位 r に対して 1 / (k + r)(k は定数、よく60が使われる)を足し合わせ、合計が大きい順に並べ替えます。なぜスコアでなく順位なのか——密検索のコサイン類似度(0〜1)とBM25スコア(青天井)はスケールが全く違うため、そのまま足すと一方に引っ張られます。RRFは順位だけ見るので、このスケール不一致を構造的に回避できます。2026年時点で RRF は Elasticsearch(rrf retriever)、OpenSearch、Weaviate(デフォルト融合)、Qdrant(Fusion.RRF)にネイティブ実装されています。
ハイブリッド検索の実装(Qdrant Query API)
主要ベクトルDBはハイブリッド検索を標準機能として持っています。ここでは Qdrant の Query API で、密ベクトルと疎ベクトル(BM25)を RRF で融合する最小構成を示します。手順は次の通りです。
pip install qdrant-clientでクライアントを入れる。- 密ベクトルと疎ベクトルの両方でクエリを表現する(密は埋め込みモデル、疎はBM25/SPLADE)。
- 密・疎それぞれの
Prefetch(候補取得)を定義する。 - 2つの Prefetch を
FusionQuery(fusion=RRF)でまとめて投げる。 - 融合済みの上位結果を受け取り、必要なら2段目のリランクに渡す。
# 動作環境: Python 3.11+, qdrant-client>=1.10.0
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from qdrant_client import QdrantClient
from qdrant_client import models
client = QdrantClient(url="http://localhost:6333")
# 密ベクトルは埋め込みモデルで、疎ベクトルはBM25/SPLADEで生成しておく
dense_query = [0.12, 0.85] # 例: 埋め込みベクトル(実際は数百〜数千次元)
sparse_query = models.SparseVector( # 例: 疎ベクトル(indices と values)
indices=[7, 42, 130],
values=[0.9, 0.4, 0.7],
)
# 密・疎をそれぞれ Prefetch で候補取得し、RRF で融合
results = client.query_points(
collection_name="docs",
prefetch=[
models.Prefetch(query=dense_query, using="dense", limit=50),
models.Prefetch(query=sparse_query, using="sparse", limit=50),
],
# RRF 融合: 個別の query vector は不要(順位ベースで統合される)
query=models.FusionQuery(fusion=models.Fusion.RRF),
limit=10, # 融合後の上位10件
)
for point in results.points:
print(point.id, point.score)
- ポイント:
Prefetchが1段目の候補取得(密・疎それぞれ top-50)、FusionQuery(fusion=RRF)が統合にあたります。融合は順位ベースなので、トップレベルで query vector を指定する必要はありません。 - Weaviate なら
alpha(デフォルト0.75 = 密75% / BM25 25%)で重み付き融合も選べます。RRFと重み付き融合のどちらが良いかはデータ依存なので、後述の評価で比べてください。 - このハイブリッド結果を、さらに前述のリランカーに通す「ハイブリッド+リランク」が、精度を最も詰めやすい構成です。ベクトルDB自体の選定はAIエージェント実装5フェーズ完全ガイドでも触れています。
リランクとハイブリッド検索、どう使い分けるか
2つは「どちらか」ではなく「組み合わせ」が基本です。役割が違うからです。
| 観点 | ハイブリッド検索 | リランク |
|---|---|---|
| 効く工程 | 1段目(候補取得) | 2段目(並べ替え) |
| 主な効果 | 取りこぼしを減らす(再現率を上げる) | 上位の精度を上げる(適合率を上げる) |
| 強み | 固有名詞・言い換えの両取り | 「意味は近いが無関係」を弾く |
| コスト | ストレージ増(疎ベクトル分)・わずかなレイテンシ | クロスエンコーダ推論のレイテンシ・API課金 |
推奨フローはこうです。
- まずハイブリッド検索で、密+疎で候補を多め(top-50〜100)に取り、1段目の取りこぼしを最小化する。
- 次にリランクで、その候補をクロスエンコーダで採点し直し、本当に必要な top-3〜5 に絞る。
- 絞った少数の高関連文書だけを生成モデルに渡す。
ハイブリッドが「正解を候補プールに入れる」役割、リランクが「候補プールから正解を上位に持ち上げる」役割。両方そろって初めて、retrieval だけでは越えられなかった精度に届きます。
精度がどれだけ上がるかをどう測るか
「リランクを入れたら良くなった気がする」では本番に出せません。自前の評価セットで数値で測るのが鉄則です。公称ベンチマーク(BEIRのnDCGなど)はあくまで一般データでの値で、あなたのドメインでの効果とは別物だからです。
最低限そろえる評価指標
- Recall@k:top-k の中に正解文書が含まれている割合。1段目(ハイブリッド検索)の取りこぼし評価に使う。
- nDCG@k / MRR:正解が上位にあるほど高くなる順位考慮の指標。2段目(リランク)の効果評価に使う。
- 最終回答の正確性:retrieval だけでなく、生成まで含めた end-to-end の正答率。実務上はこれが最終判断。
評価の進め方
- 自社の代表的な質問を50〜100問、各質問に「正解文書」をひも付けた評価セットを作る。
- ①ベクトル検索のみ ②ハイブリッドのみ ③ハイブリッド+リランク、の3構成で同じ質問セットを流す。
- 各構成で Recall@k / nDCG@k を計算し、どの段階で何ポイント改善したかを分解して見る。
- 改善幅が小さければ、kを増やす/リランカーを替える/疎ベクトルをBM25からSPLADEに替える等を1つずつ試す。
評価セットの作り方やデータ前処理はLlamaIndex完全ガイドの評価モジュールも参考になります。一度に複数を変えるとどれが効いたか分からなくなるので、変数は1つずつ動かしてください。
コストとレイテンシのトレードオフ
精度を上げる施策には、必ずコストとレイテンシの代償があります。ここを見ずに「とりあえず全部入れる」と、本番で遅くて高いシステムになります。
- ハイブリッド検索:疎ベクトルを持つ分、ストレージが増えます(密のみ比で約1.4倍という報告もあり)。レイテンシ増は実装によりますが、ネイティブ対応のDBでは数ミリ秒オーダーに収まるケースが報告されています(2026年時点)。
- リランク:ここが一番効きます。クロスエンコーダは候補1件ずつ採点するため、1段目で取る候補数(top-k)にレイテンシとコストが比例します。top-100をリランクすればtop-20の5倍の負荷です。
- API型リランカーの課金:Cohere は検索回数ベース、Voyage はトークンベースと課金体系が違います。大量リクエストならトークン課金が読みにくくなる場合があるので、想定トラフィックで概算しておきましょう。
実装の指針はシンプルです。1段目の候補数(k)が、精度・コスト・レイテンシを同時に決める最重要パラメータです。kを大きくすれば取りこぼしは減りますが、リランクの負荷とコストが上がる。まずは top-50 程度から始め、評価セットで Recall が頭打ちになる k を見つけて、そこで止めるのが現実的です。
よくある失敗パターンと回避策
失敗1:1段目の候補を絞りすぎてリランクに渡す
❌ ベクトル検索で top-5 だけ取って、それをリランク
⭕ ベクトル検索で top-50〜100 取って、リランクで top-5 に絞る
なぜ重要か:リランクは候補プールに入っていない文書を上位に持ち上げられません。1段目を絞りすぎると、リランクの効果が出ません。「広く取って、狭く絞る」が鉄則です。
失敗2:スコアをそのまま足してハイブリッド融合する
❌ コサイン類似度とBM25スコアを単純加算
⭕ RRF(順位ベース融合)を使う、または各スコアを正規化してから重み付け
なぜ重要か:密のスコア(0〜1)とBM25スコア(青天井)はスケールが違い、単純加算するとBM25に引っ張られます。RRFは順位だけ見るので、この問題を構造的に回避します。
失敗3:公称ベンチマークだけで導入を決める
❌ 「BEIRのnDCGが一番高いから」でリランカーを選ぶ
⭕ 自社の質問50〜100問で Recall@k / nDCG@k を実測してから選ぶ
なぜ重要か:公称値は一般データでの値です。専門用語の多いドメインや日本語中心の用途では、順位が逆転することがあります。最終確認は必ず自前の評価セットで行ってください。
まとめ:今日から始める3つのアクション
- 今日やること:既存のRAGに、まずリランクだけを追加してみる。bge-reranker-v2-m3 か Cohere Rerank で、1段目 top-50 → 2段目 top-5 の構成を試す。
- 今週中:自社の質問を50問ほど集めて評価セットを作り、「ベクトルのみ」と「+リランク」で Recall@k / nDCG@k を比較する。
- 今月中:取りこぼしが残るなら、密+疎(BM25/SPLADE)のハイブリッド検索をRRFで追加し、「ハイブリッド+リランク」まで構成して end-to-end の正答率で効果を確定させる。
retrieval の精度は、埋め込みモデルの選定だけでは頭打ちになります。「広く取って、賢く並べ替える」——ハイブリッド検索とリランクの2段構えが、RAG精度の天井を一段押し上げる現実的な打ち手です。
この記事を読んでRAGの精度改善イメージが固まってきた方へ
Uravationでは、RAG・AIエージェントの設計から本番運用までの研修・導入支援を行っています。お気軽にご相談ください。
あわせて読みたい
- RAGの埋め込みモデル選定完全ガイド — 検索精度の土台となる埋め込みモデルの選び方
- LlamaIndex完全ガイド — RAGのデータ取り込み・評価フレームワーク
- AIエージェント実装5フェーズ完全ガイド — 設計から本番運用までの全体像
著者:佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。著書『AIエージェント仕事術』。100社以上の企業向けAI研修・導入支援に携わる。
参考・出典
- Cohere’s Rerank Model (Details and Application) — Cohere公式ドキュメント(参照日: 2026-06-03)
- Cohere’s Rerank v4.0 Model is Here! — Cohere公式チェンジログ(参照日: 2026-06-03)
- How Does Cohere’s Pricing Work? — Cohere公式ドキュメント(参照日: 2026-06-03)
- jina-reranker-v3 — Search Foundation Models — Jina AI公式(参照日: 2026-06-03)
- Reranker API — Jina AI公式(参照日: 2026-06-03)
- Rerankers — Voyage AI公式ドキュメント(参照日: 2026-06-03)
- Pricing — Voyage AI公式ドキュメント(参照日: 2026-06-03)
- BAAI/bge-reranker-v2-m3 — Hugging Face(BAAI公式モデルカード、参照日: 2026-06-03)
- Hybrid Search Revamped – Building with Qdrant’s Query API — Qdrant公式(参照日: 2026-06-03)
- Hybrid Search Explained — Weaviate公式(参照日: 2026-06-03)
- What is a Sparse Vector? How to Achieve Vector-based Hybrid Search — Qdrant公式(参照日: 2026-06-03)
- SPLADE for Sparse Vector Search Explained — Pinecone公式(参照日: 2026-06-03)


