
RAGの精度が出ない――その原因の多くは「検索(retrieval)」より手前の「取り込み(ingestion)」にあります。汚いPDFや複雑な表をそのままテキスト化すると、どんなに優れたembeddingやリランクを積んでも回収できません。本ガイドは2026年6月時点の現行ツール(Docling・Unstructured・LlamaParse・MarkItDown・PyMuPDF)を比較し、PDF→Markdown→チャンクの最小実装まで、取り込み層の設計を体系的に整理します。
なぜ「取り込み(パース)」がRAG精度の出発点なのか
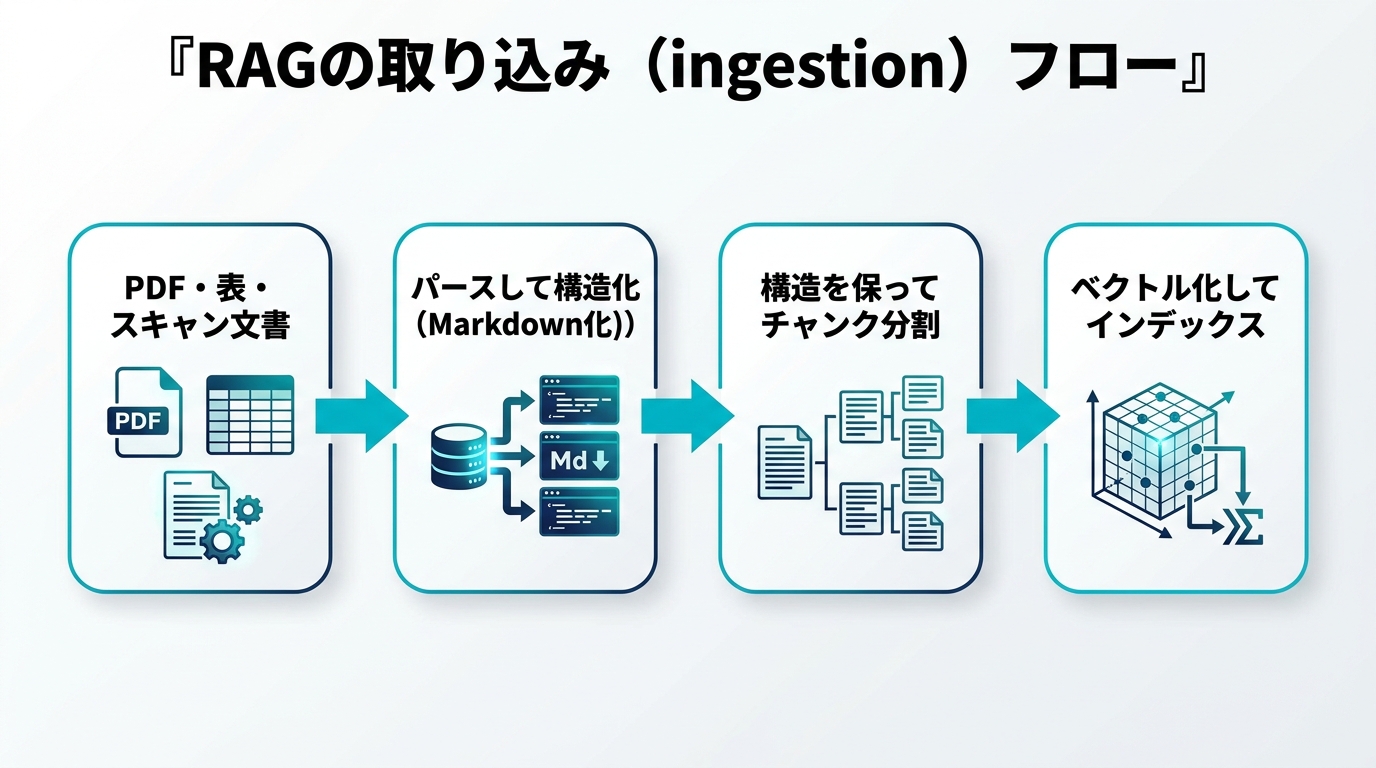
RAGパイプラインは大きく「取り込み(ingestion/parsing)」→「分割(chunking)」→「埋め込み(embedding)」→「検索(retrieval)」→「生成(generation)」という流れで構成されます。このうち多くの開発者は検索やリランクのチューニングに時間を割きますが、実は最初の取り込みが最も支配的なボトルネックになりがちです。
理由はシンプルで、取り込み層で失われた情報は後段で復元できないからです。PDFの表が崩れてセルがバラバラのテキストになれば、embeddingモデルがどれだけ高性能でも「行と列の関係」は復元できません。これがいわゆる「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」です。取り込みは、後段すべての品質の上限を決める天井になります。
具体的に何が崩れるかというと、(1) 表のセル構造、(2) 段組み(2カラム)の読み順、(3) 見出し階層、(4) 図表のキャプションとの対応、(5) スキャン文書の文字そのもの、といった「レイアウトに埋め込まれた意味」です。これらを構造を保ったままMarkdownやJSONに落とし込めるかどうかが、取り込みツール選定の核心になります。
Embeddingモデルの選定や検索精度の改善は重要ですが、その効果を引き出す前提として、まず取り込み品質を整えることが先決です。
取り込みの難所:複雑PDF・表・段組み・スキャン・図表
「PDFをテキスト化するだけ」と侮ると痛い目を見ます。実務で頻出する難所を整理しておきます。
- 複雑なレイアウトのPDF:2カラムの論文や、サイドバー・脚注が混在する資料。単純な左上から右下への読み取りでは読み順が壊れます。
- 表(テーブル):結合セル・ネストした表・罫線のない表など。セル境界を正しく検出できないと、行と列の対応が消えます。表抽出は取り込みで最も難易度が高い領域です。
- スキャン文書・画像PDF:テキストレイヤーを持たないため、OCR(光学文字認識)が必須になります。
- 図表・グラフ:棒グラフや円グラフの数値、フローチャートの構造。テキスト抽出だけでは中身が落ちます。
- 数式・コード:LaTeX数式やソースコードのブロック。プレーンテキスト化で記号が壊れがちです。
これらを「どこまで構造化したいか」が、OSSライブラリで十分か、クラウドのDocument AIまで必要かの分岐になります。次章で主要ツールを比較します。
主要ツール比較:Docling/Unstructured/LlamaParse/MarkItDown/PyMuPDF
2026年6月時点の現行ツールを、OSSとAPI(クラウド)の軸で整理します。価格や仕様は変動するため、導入前に必ず各公式で最新値を確認してください。
| ツール | 提供形態 | 強み | ライセンス/料金(要公式確認) |
|---|---|---|---|
| Docling(IBM Research) | OSSライブラリ | レイアウト・表構造・OCR・VLMを統合。Markdown/HTML/JSON出力 | MIT(無料) |
| Unstructured | OSS + Serverless API | 30以上のフォーマット対応・チャンク戦略内蔵・エンタープライズ運用 | OSS無料。API: Fast 1,000ページ1.25ドル相当〜(公式確認) |
| LlamaParse(LlamaIndex) | API(LlamaCloud) | 視覚的に複雑な文書から綺麗なMarkdown。LlamaIndex連携が容易 | クレジット制。無料枠あり(公式確認) |
| MarkItDown(Microsoft) | OSSライブラリ | 軽量・15以上のフォーマットを1関数でMarkdown化。Office系に強い | MIT(無料) |
| PyMuPDF / pymupdf4llm | OSSライブラリ | 高速・軽量。Markdown/JSON出力。RAG向け拡張あり | AGPL または商用ライセンス(要注意) |
OSS:Docling・MarkItDown・PyMuPDF
DoclingはIBM Researchが開発するOSSで、2026年6月時点の最新版はv2.96.1(リリース2026-06-01)、ライセンスはMITです。PDF・DOCX・PPTX・XLSX・HTML・画像などを入力に取り、ページレイアウト・読み順・表構造の解析、スキャンPDFのOCR、さらにVisual Language Model(Granite-Docling 258M、Apache 2.0で2026年1月公開)による一括処理に対応します。出力はMarkdown/HTML/JSON/DocTagsです。表抽出の精度評価でもLlamaParseと並んで上位に位置づけられる報告があり(具体スコアは出典の評価条件に依存するため公式・原典で確認推奨)、「完全OSSで高精度」を狙うなら有力候補です。
MarkItDownはMicrosoftのOSSで、ライセンスはMIT。15以上のフォーマットを1つのPython関数でLLM向けMarkdownに変換することに特化した軽量ツールです。見出し・リスト・表・リンクなどの構造を保ちつつMarkdown化します。複雑なPDFやスキャン文書は、Azure Document Intelligenceと連携させることで抽出品質を高められます(連携時はAzure側の料金が発生)。Office文書中心のパイプラインで「とにかく速く軽くMarkdown化したい」用途に向きます。
PyMuPDF(および拡張のpymupdf4llm)は、MuPDFのCエンジンを土台にした高速・軽量なライブラリです。pymupdf4llmはPDFをMarkdown/JSON/テキストに整形し、LlamaIndex・LangChain連携にも対応します。ライセンスに注意が必要で、PyMuPDF/pymupdf4llmはGNU AGPL または Artifexの商用ライセンスのいずれかです。RAGの取り込みに組み込む商用プロダクトでもAGPLの義務が及ぶため、クローズドソース製品で使う場合は商用ライセンスの要否を法務確認してください。
API:Unstructured・LlamaParse
UnstructuredはOSS版に加え、Serverless APIを提供します。30以上のフォーマット対応と複数のチャンク戦略を内蔵し、SOC 2やHIPAA対応・VPC内デプロイなどエンタープライズ要件に強いのが特徴です。Serverless APIの料金は、Fastパイプラインが1,000ページあたり1.25ドル相当、Hi-Res(高精度)パイプラインが1,000ページあたり10ドル前後で、無料トライアル枠(15,000ページ規模)が用意されています(最新の単価・無料枠は公式の料金ページで要確認)。
LlamaParseはLlamaIndexのGenAIネイティブなパース用APIで、LlamaCloud上で動作します。視覚的に複雑な文書から綺麗なMarkdownを生成でき、LlamaIndexを既に使っているなら最小の設定で導入できます。v2でモード選択がシンプルなティア制(Fast / Cost Effective / Agentic / Agentic Plus)に整理され、クレジット制(無料枠は月10,000クレジット規模)で課金されます。ページあたりの消費クレジットはティアによって大きく変わるため、コスト試算は公式の料金ページで最新値を確認してください。
最小実装:PDF→Markdown→チャンク
まずはOSSのDoclingで、PDFをMarkdown化してチャンクに分割するところまでを最小構成で組みます。2026年6月時点のAPIに基づきますが、import pathやAPIは変わりやすいので公式ドキュメントで最新を確認してください。手順は次のとおりです。
- 環境を用意する:Python 3.10以上を準備し、依存をインストールします。
- Doclingをインストールする:
pip install doclingを実行します。 - PDFをDoclingDocumentに変換する:
DocumentConverterで対象PDFを読み込みます。 - Markdownへエクスポートする:
export_to_markdown()で構造を保ったMarkdownを得ます。 - Markdownをチャンクに分割する:見出し境界を尊重して分割します(後述)。
- 各チャンクにメタデータを付与する:出典ファイル名・ページ・見出しパスを残します。
from docling.document_converter import DocumentConverter
# 1. PDF を DoclingDocument に変換
converter = DocumentConverter()
result = converter.convert("report.pdf")
# 2. 構造を保ったまま Markdown 化
markdown = result.document.export_to_markdown()
# 3. ファイルに保存(確認用)
with open("report.md", "w", encoding="utf-8") as f:
f.write(markdown)
print(markdown[:500])
続いて、得られたMarkdownを見出し境界でチャンク分割します。ここではLangChainのMarkdownHeaderTextSplitterを使い、構造を壊さずに分けます。
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "h1"),
("##", "h2"),
("###", "h3"),
]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
chunks = splitter.split_text(markdown)
for c in chunks[:3]:
# metadata に見出しパスが入る(出典トレースに使える)
print(c.metadata, "->", c.page_content[:80])
この時点で、各チャンクには「どの見出しの下にある内容か」というメタデータが付きます。後段の検索で出典を提示したり、フィルタリングに使ったりできるため、構造情報を捨てないことが重要です。
表・レイアウトの扱い
取り込みで最も差が出るのが表です。RAGで表を扱うときの基本方針は「表をフラットなテキストに潰さず、構造を保つ」ことです。
具体的には、表をMarkdownのテーブル記法(パイプ区切り)として残す方法と、表だけを別チャンクとして切り出してHTMLやJSONで保持する方法があります。Doclingは表構造を解析してMarkdown/HTML/JSONに出力できるため、表を独立したチャンクとして扱いやすい設計です。表が大きい場合は、ヘッダー行を各サブチャンクに繰り返し付与すると、分割後も「何の列か」が失われません。
段組み(2カラム)のPDFでは、読み順の検出がカギです。レイアウト解析を持つDoclingやUnstructured(Hi-Res)、LlamaParseのようなレイアウト対応パーサーを使うと、左カラムを上から下まで読んでから右カラムに移る、という正しい順序を再現しやすくなります。逆に、レイアウト解析を持たない単純抽出だと、左右の行が交互に混ざってテキストが意味をなさなくなることがあります。
図表については、(1) キャプションを近接テキストとして紐付ける、(2) 図そのものをVLMで説明文に変換してテキスト化する、という2方針があります。DoclingのVLMパイプラインやLlamaParseのマルチモーダル機能はこの用途に対応しますが、コストと精度のトレードオフがあるため、図が検索対象として重要な文書だけ適用するのが現実的です。
スキャン文書とOCR
テキストレイヤーを持たないスキャンPDFや画像は、OCRなしでは1文字も取り出せません。判定の目安は単純で、抽出結果が空または極端に短い場合はスキャン文書を疑うです。
OSSではDoclingがスキャンPDF・画像のOCRに対応しており、追加サービスなしで取り込めます。MarkItDownはAzure Document Intelligenceと連携することで、スキャン文書のフルページOCRや画像内テキスト抽出を強化できます。より高精度・大規模が必要なら、クラウドのDocument AIが選択肢になります。
| クラウドDocument AI | 提供元 | 料金の目安(要公式確認) |
|---|---|---|
| Document AI | Google Cloud | プロセッサ種別ごとにページ単価。公式の料金ページで確認 |
| Amazon Textract | AWS | DetectDocumentText 約1.50ドル/1,000ページ、AnalyzeDocumentのForms 50ドル+Tables 15ドル/1,000ページ等 |
| Azure Document Intelligence | Microsoft Azure | モデル種別ごとにページ単価。公式の料金ページで確認 |
クラウドのDocument AIは、帳票・請求書・本人確認書類のような定型フォームの構造化(キーバリュー抽出)に強い反面、ページ課金が積み上がります。大量処理ではOSS(Docling等)でまず処理し、難所だけクラウドにフォールバックさせるハイブリッド構成がコスト効率に優れます。なお上記の単価は2026年6月時点の参考値で、リージョン・機能組み合わせ・ボリュームで変動するため、必ず各クラウドの公式料金ページで最新値を確認してください。
チャンク分割との接続:構造を保ったまま分割する
取り込みの出力は、そのままチャンク分割の入力になります。ここで設計を誤ると、せっかく綺麗に構造化したMarkdownを台無しにします。原則は「意味的境界(見出し・段落・表)を尊重し、文の途中で切らない」です。手順は次のとおりです。
- まず構造境界で大きく分ける:H2/H3などの見出しで一次分割し、セクション単位の塊にします。
- サイズ上限を決める:多くのembeddingモデルでは1チャンク200〜500トークン程度が扱いやすい目安です(モデルの最大入力で要調整)。
- 上限を超えるセクションを再分割する:段落境界でさらに分け、文の途中では切りません。
- オーバーラップを少し持たせる:隣接チャンクで数十トークン重ねると、境界をまたぐ文脈の取りこぼしが減ります。
- 表は別チャンクにする:表は本文と混ぜず、ヘッダー付きで独立させます。
- メタデータを付与する:出典・ページ・見出しパスをチャンクに添えます。
この「構造を保ったチャンク」が、後段のリランク・ハイブリッド検索の効きを大きく左右します。検索が取りこぼす多くは、取り込みとチャンク設計の段階で意味の単位が壊れていることに起因します。
品質チェックと運用
取り込みは「動いた」で終わらせず、品質を継続的に検証する運用に乗せます。最低限のチェック観点は以下です。
- 抽出率の監視:1ページあたりの抽出文字数が極端に少ない文書を自動検知し、スキャン文書やパース失敗を洗い出します。
- 表の保全:表を含む文書で、行数・列数がMarkdown出力でも保たれているかをサンプリング確認します。
- 読み順の妥当性:2カラム文書で、見出し→本文の順序が崩れていないか目視で抜き取り検査します。
- 文字化け・記号崩れ:数式・コード・特殊記号が壊れていないかを確認します。
- 回帰テスト:代表的な「難しい文書」を固定セットとして持ち、パーサーやバージョンを変えたときに品質が落ちていないか比較します。
運用面では、文書の種類が増えるほど「1つのパーサーで全部」は難しくなります。テキストPDFはPyMuPDF/MarkItDownで高速処理、レイアウト複雑な文書はDocling、視覚的に難しい文書や定型フォームはLlamaParseやクラウドDocument AI、というように文書タイプ別にパーサーを振り分けるルーティングを持つと、コストと精度のバランスが取りやすくなります。
まとめ:取り込みはRAGの天井を決める
RAGの精度改善というと検索やリランクに目が行きがちですが、その効果の上限を決めているのは取り込み(パース)層です。汚いPDFや表・スキャンをいかに構造を保ったままMarkdown/JSONに落とすかが、後段すべての品質を規定します。
2026年6月時点では、完全OSSで高精度を狙うならDocling、軽量・高速ならPyMuPDF(ライセンス注意)やMarkItDown、視覚的に複雑な文書ならLlamaParse、エンタープライズ要件ならUnstructuredやクラウドDocument AI、という棲み分けが現実的です。まずはDoclingでPDF→Markdown→チャンクの最小構成を組み、難所だけ別ツールにフォールバックさせるハイブリッドから始めるのがおすすめです。ツールのバージョンや料金は変動が速いので、導入前に必ず各公式で最新を確認してください。
この記事を読んでRAGの取り込み設計のイメージが固まってきた方へ
UravationではAIエージェント・RAG導入の研修・コンサルを行っています。取り込みからチャンク・検索まで、自社データに合わせた設計を伴走支援します。
参考・出典
- Docling — GitHub(docling-project/docling)
- Docling 公式ドキュメント
- IBM — Granite-Docling: End-to-end document understanding
- Unstructured — GitHub(Unstructured-IO/unstructured)
- Unstructured 公式ドキュメント
- LlamaIndex — Introducing LlamaParse V2
- LlamaParse 公式ドキュメント
- MarkItDown — GitHub(microsoft/markitdown)
- pymupdf4llm — GitHub(pymupdf/pymupdf4llm)
- PyMuPDF4LLM 公式ドキュメント
- Google Cloud — Document AI ドキュメント
- AWS — Amazon Textract
- Microsoft — Azure AI Document Intelligence 概要


