
RAGを構築して「検索がうまくヒットしない」「回答が的外れになる」と悩んだことはないでしょうか。実際に複数のRAGパイプラインを検証してきた経験から言うと、精度が出ない原因の多くは埋め込みモデルでもLLMでもなく、その手前の「チャンキング(テキスト分割)」にあります。
ドキュメントをどう切るかで、検索でヒットする単位も、LLMに渡る文脈の質も決まります。切り方が悪ければ、どんなに高性能な埋め込みモデルを使っても「関連チャンクが上位に来ない」状態が続きます。
この記事では、なぜチャンキングが重要なのか、主要な分割手法をどう使い分けるのか、チャンクサイズとオーバーラップをどう決めるのか、そして良し悪しをどう測るのかを、LangChain・LlamaIndexの実装ベースで解説します。本記事は「抽出後のテキストをどう分割するか(チャンキング戦略)」に特化した内容です。PDFやHTMLからテキストを取り出す前段の処理については、ドキュメント抽出・パース(RAGのingestion)ガイドを参照してください。
なぜチャンキングがRAGの精度を左右するのか
RAGの検索は「チャンク単位」で行われます。ドキュメント全体を一括で埋め込むのではなく、分割したチャンクごとにベクトル化し、クエリとの類似度で上位を取り出します。つまりチャンクが検索のヒット単位そのものであり、ここの設計がそのまま検索精度に直結します。
問題になるのは「大きすぎる分割」と「小さすぎる分割」の両極端です。LangChainの公式ドキュメントでも、チャンクサイズが小さいほど検索コストは下がるが広い文脈を取りこぼしやすく、大きいほど文脈は豊富になるが不要な情報で薄まり回答がぼやける、というトレードオフが明記されています。
大きすぎるチャンクの弊害
- 埋め込みが薄まる:1チャンクに複数のトピックが混在すると、ベクトルが「平均化」され、特定のクエリに対する類似度が下がります。
- ノイズが増える:取り出したチャンクに関係ない情報が多く含まれ、LLMが正しい部分を見つけにくくなります。
- コンテキスト枠を圧迫する:1チャンクが長いと、上位N件を渡すだけでコンテキストウィンドウを消費し、件数を絞らざるを得なくなります。
小さすぎるチャンクの弊害
- 文脈が断片化する:文の途中や、主語と述語が別チャンクに分かれると、検索にヒットしても意味が通らなくなります。
- 指示語が迷子になる:「これは」「同社は」といった指示語が、何を指すか分からないチャンクが量産されます。
- 回答に必要な情報が分散する:1つの問いに答えるのに複数チャンクが必要になり、検索の取りこぼしが起きやすくなります。
正直に言うと、この「ちょうどいい大きさ」は固定値で決まりません。後述するように、コンテンツの性質・埋め込みモデル・タスクによって最適点が変わるため、最終的には計測して決めるのが原則です。それでも、手法の特性を理解しておくと初期値の当たりを大きく外さずに済みます。
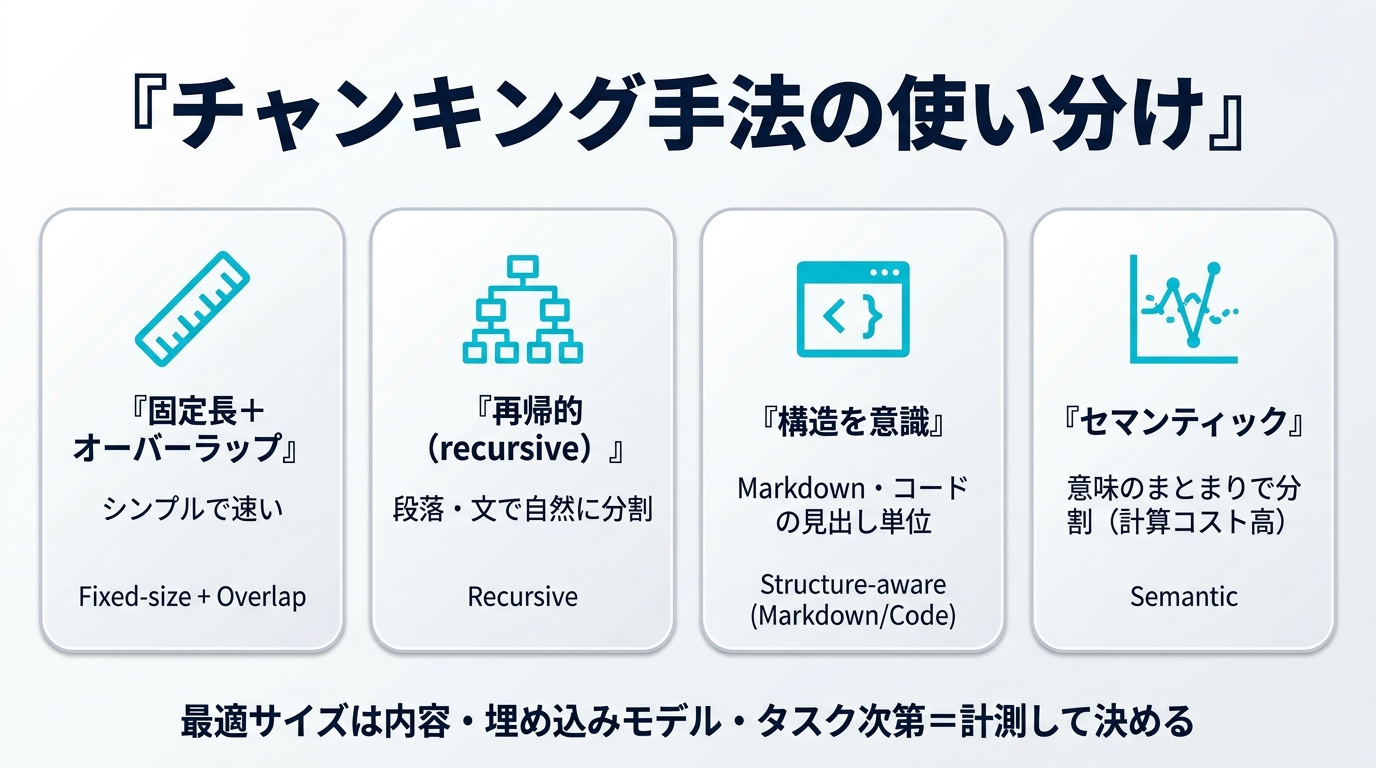
主要なチャンキング手法6種を整理する
チャンキング手法は大きく「構造を見ない方法」と「構造・意味を見る方法」に分かれます。まず全体像を表で整理します。
| 手法 | 分割の基準 | 構造保持 | 計算コスト | 向いている用途 |
|---|---|---|---|---|
| 固定長分割 | 文字数・トークン数 | 低 | 低 | とりあえず動かす検証段階 |
| オーバーラップ付き | 固定長+重複 | 低〜中 | 低 | 境界またぎの取りこぼし対策 |
| 再帰的(recursive) | 段落→行→単語の優先順位 | 中 | 低 | 汎用テキスト全般(既定の第一選択) |
| 文・段落単位 | 文の切れ目 | 中〜高 | 低 | 意味の単位を保ちたいとき |
| 構造を意識(Markdown/コード) | 見出し・関数などの構文 | 高 | 低 | 技術文書・ソースコード |
| セマンティック分割 | 埋め込み類似度の変化点 | 高 | 高 | トピックが切り替わる長文 |
1. 固定長分割(Fixed-size chunking)
最もシンプルな方法です。文字数やトークン数で機械的に切るだけなので高速で、最初の検証には十分です。ただし文の途中や単語の途中で切れてしまうため、本番品質ではほぼそのまま使いません。あくまで「ベースライン」として押さえておくものです。
2. オーバーラップ付き分割(Overlapping chunks)
固定長分割の弱点である「境界またぎの取りこぼし」を緩和するのがオーバーラップです。隣り合うチャンク同士を一定量だけ重複させることで、ちょうど境界に来てしまった重要な文が、どちらかのチャンクには丸ごと含まれるようにします。LangChainの公式ドキュメントでも、オーバーラップは「文脈が分割されたときの情報損失を緩和する」ものと説明されています。これは固定長だけでなく、次の再帰的分割でも標準的に併用します。
3. 再帰的分割(RecursiveCharacterTextSplitter)— まず使うべき既定手法
実務で「とりあえずどれを使えばいいか」と聞かれたら、まずこれです。LangChainのRecursiveCharacterTextSplitterは、区切り文字に優先順位を付けて分割します。既定では["nn", "n", " ", ""]の順で、まず段落(二重改行)で切ろうとし、それでもチャンクサイズを超える場合は改行、それでも超えるなら空白、最後に文字単位、と段階的にフォールバックします。
これにより「できるだけ段落・文の意味のまとまりを保ったまま、指定サイズに収める」という挙動になります。最小実装は以下のとおりです。
# 動作環境: Python 3.11+, langchain-text-splitters>=0.3
# 必要パッケージ: pip install langchain-text-splitters
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # チャンクの最大サイズ(length_functionの単位)
chunk_overlap=50, # 隣接チャンクの重複量
length_function=len, # 既定は文字数。トークン数で測りたい場合は別途指定
is_separator_regex=False,
)
chunks = splitter.split_text(long_text)
print(f"chunk count: {len(chunks)}")
ポイント:
chunk_sizeはlength_functionの単位で測られます。既定は文字数なので、トークン上限を厳密に守りたい場合はfrom_tiktoken_encoder()などトークンベースの計測に切り替えます。chunk_overlapはchunk_sizeの10〜20%程度から始めるのが扱いやすい初期値です。- 日本語は二重改行や句点での区切りが効きにくいことがあるため、
separatorsに"。"などを追加して調整する余地があります。
4. 文・段落単位の分割(SentenceSplitter)
LlamaIndexのSentenceSplitterは、文や段落をできるだけ壊さないように分割します。公式ドキュメントの説明でも、トークン単位の分割に比べて「文の途中で途切れたチャンクが生まれにくい」とされています。既定のchunk_sizeは1024トークンです。意味の単位として「文」は非常に自然な粒度であり、後述するベンチマークでも、凝った手法に対して堅実に戦える基準になります。
# 動作環境: Python 3.11+, llama-index-core>=0.11
# 必要パッケージ: pip install llama-index-core
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(
chunk_size=512, # トークン単位
chunk_overlap=50,
)
nodes = splitter.get_nodes_from_documents(documents)
5. 構造を意識した分割(Markdown・コード)
技術文書やソースコードを固定長で切ると、見出しと本文が分断されたり、関数が途中で切れたりします。これを避けるため、構文を意識した分割が用意されています。LangChainのRecursiveCharacterTextSplitter.from_language()は、言語ごとの区切り文字セットを使って分割します。公式に対応する言語にはMarkdown・Python・JavaScript・HTMLなどが含まれます(2026年6月時点)。
# Markdownを見出し構造を意識して分割する例
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from langchain_text_splitters import RecursiveCharacterTextSplitter, Language
md_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.MARKDOWN,
chunk_size=500,
chunk_overlap=0,
)
md_chunks = md_splitter.split_text(markdown_text)
# ソースコード(Python)を関数・クラス単位を意識して分割する例
py_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=400,
chunk_overlap=0,
)
py_chunks = py_splitter.split_text(source_code)
ポイント:Markdownの場合は見出し(# 〜 ######)を優先的な区切りとして扱うため、「どの見出しの下の内容か」というまとまりが保たれやすくなります。技術メディアやドキュメント検索では、ここを変えるだけで体感の精度が変わることがあります。
6. セマンティックチャンキング(SemanticSplitterNodeParser)
セマンティックチャンキングは、固定サイズではなく「意味の切れ目」で分割します。LlamaIndexのSemanticSplitterNodeParserは、連続する文を埋め込みベクトル化し、隣接する文同士のコサイン類似度を計算して、類似度が大きく落ちる地点(=トピックが切り替わる地点)を分割点に選びます。結果として、1チャンク内が意味的にまとまりやすくなります。
# 動作環境: Python 3.11+, llama-index-core>=0.11
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
splitter = SemanticSplitterNodeParser(
buffer_size=1, # 類似度評価時に前後何文まとめるか
breakpoint_percentile_threshold=95, # 分割点とみなす類似度低下の閾値
embed_model=embed_model,
)
nodes = splitter.get_nodes_from_documents(documents)
ただし注意が必要です。各文を埋め込む必要があるため計算コストが高く、常に固定長より精度が高いとは限りません。NAACL 2025 Findingsの論文「Is Semantic Chunking Worth the Computational Cost?」では、文書検索・根拠検索・回答生成の3タスクで評価した結果、固定の200ワードチャンクがセマンティックチャンキングに匹敵またはそれを上回るケースが多く、計算コストに見合う一貫した改善は確認されなかった、と報告されています。つまり「賢そうだから採用する」のではなく、自分のデータで効果を計測してから判断すべき手法です。
チャンクサイズとオーバーラップの決め方
最初に身も蓋もない結論を書くと、最適なチャンクサイズに普遍的な正解はありません。内容・埋め込みモデル・タスクで変わるため、計測して決めるのが原則です。とはいえ「何から始めればいいか」の当たりは付けられます。
初期値の当たりの付け方
- チャンクサイズ:汎用的な文章なら300〜800トークン程度を起点にします。FAQや短い定義中心なら小さめ、契約書や技術仕様のように文脈依存が強いなら大きめが目安です。
- オーバーラップ:チャンクサイズの10〜20%が扱いやすい範囲です。0にすると境界の取りこぼしが増え、50%まで上げると重複が増えてインデックスが膨らみ検索の重複ヒットが起きやすくなります。
- 埋め込みモデルの上限を確認:モデルには入力トークン上限があり、それを超えると切り捨てられます。チャンクサイズはモデルの上限内に必ず収めます。どの埋め込みモデルを選ぶかは埋め込みモデル選定ガイドで扱っています。
計測して詰める手順
- 候補を3〜4パターン用意する:例として(256/0)(512/50)(800/100)(1024/150)のように、サイズ×オーバーラップの組み合わせを並べます。
- 同じ評価セットで横並び比較する:後述の評価指標で、各パターンの検索精度を測ります。条件を揃えることが重要です。
- 検索コストとインデックスサイズも見る:精度がほぼ同じなら、チャンク数が少なく軽い方を選びます。
- 勝ったパターンを起点に微調整する:勝った構成の前後をさらに振って、頭打ちになる点を探します。
メタデータ付与と親子チャンク(small-to-big)
チャンクの「切り方」だけでなく、「何を付けて」「どう取り出すか」も精度を大きく左右します。ここが中級者と上級者の差が出るところです。
メタデータ付与
各チャンクには、本文だけでなく出典・見出し・日付などのメタデータを付与しておきます。これにより、検索後に「どの文書のどのセクションか」でフィルタリングしたり、回答に出典を添えたりできます。LangChainでもLlamaIndexでも、チャンク(Document/Node)は本文とmetadataを一緒に持てます。
# メタデータ付きでチャンクを作る例(LangChain)
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = splitter.create_documents(
texts=[long_text],
metadatas=[{
"source": "handbook_2026.pdf",
"section": "経費精算",
"updated_at": "2026-04-01",
}],
)
# 各チャンクが metadata を保持する → 検索後のフィルタや出典表示に使える
親子チャンク(small-to-big / Parent Document Retriever)
「検索は小さく、生成は大きく」という発想が親子チャンク(small-to-big retrieval)です。小さいチャンクは余計な情報が少なく検索の精度が上がりますが、LLMに渡すには文脈が足りません。そこで、検索には小さい子チャンクを使い、ヒットしたら対応する大きい親チャンク(または元の段落・文書)を取り出してLLMに渡すという分離を行います。
LangChainではParentDocumentRetrieverがこれを実装しています。LlamaIndexのSentenceWindowNodeParserも同じ系統で、文単位で索引しつつ、検索後に前後の文(ウィンドウ)をメタデータから展開して文脈を補います。
# 親子チャンク(small-to-big)の最小例(LangChain)
# 注意: 本番環境で使用する前に、必ずテスト環境で動作確認してください。
from langchain.retrievers import ParentDocumentRetriever
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 検索用の小さい子チャンク
child_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
# 生成用の大きい親チャンク
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
retriever = ParentDocumentRetriever(
vectorstore=vectorstore, # 子チャンクを埋め込んで格納
docstore=docstore, # 親チャンクを保持
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(documents)
# 検索は子チャンク、返却は親チャンク
results = retriever.invoke("経費精算の上限はいくらですか?")
コンテキスト付与(contextual retrieval)
もう一段進んだ方法として、Anthropicが提唱した「Contextual Retrieval」があります。各チャンクを埋め込む前に、「このチャンクは〜という文書の〜についての記述です」といったチャンク固有の説明文をLLMで生成して先頭に付ける手法です。指示語や文脈が補完されるため、孤立したチャンクでも検索でヒットしやすくなります。
Anthropicの公開データでは、ベースの検索失敗率5.7%に対し、Contextual Embeddings単体で失敗率を35%削減、Contextual BM25と組み合わせると49%削減、さらにリランクを加えると67%削減(失敗率1.9%)と報告されています(Anthropic公式、2026年6月時点)。チャンキングそのものではありませんが、「分割の弱点を後付けで補う」発想として知っておく価値があります。ハイブリッド検索やリランクについてはリランク・ハイブリッド検索ガイドで詳しく扱っています。
チャンキングの良し悪しをどう評価するか
チャンキングは「なんとなく良さそう」で決めると後で必ず詰まります。手法を変えたときに精度が上がったか下がったかを、数字で比較できる状態を作るのが鉄則です。
検索段階の評価指標
- Recall@k:正解を含むチャンクが上位k件に入っている割合。チャンキングの良し悪しが最も直接出る指標です。
- Precision@k / MRR:上位の正解密度、正解が何位に来たか。ノイズの多さを見るのに有効です。
- Context Recall:回答に必要な情報が、取り出したチャンク群にどれだけ含まれているか。RAG評価ツール(Ragas等)で測れます。
回答段階の評価指標
- Faithfulness(忠実性):生成された回答が、取り出したチャンクに裏付けられているか。チャンクが断片的だとここが落ちます。
- Answer Relevancy:回答が質問に対して的を射ているか。
評価の実務的なコツ:
- 自分のドメインの「質問→正解箇所」のペアを20〜50件で良いので作り、これを固定の評価セットにします。少なくても、ある方が圧倒的に判断が速くなります。
- チャンキング条件以外(埋め込みモデル・検索件数・プロンプト)は固定して、1つずつ変えます。同時に複数変えると何が効いたか分からなくなります。
- NAACLの論文が示すように、凝った手法が単純な手法に負けることは普通に起きます。新手法を入れる前に、必ず固定長・再帰的分割のベースラインと比較してください。
【要注意】よくある失敗パターンと回避策
失敗1:いきなりセマンティックチャンキングから始める
❌「賢い手法だから」と最初からセマンティックチャンキングを採用
⭕ まず再帰的分割(RecursiveCharacterTextSplitter)でベースラインを作り、評価セットで物足りなければ高度な手法を試す
なぜ重要か:前述の通り、計算コストの高いセマンティックチャンキングが固定長に負けることは珍しくありません。コストをかけた分だけ精度が上がる保証はないので、安い手法から始めるのが鉄則です。
失敗2:オーバーラップ0で運用して取りこぼす
❌ チャンクサイズだけ設定し、オーバーラップを0のまま本番投入
⭕ チャンクサイズの10〜20%のオーバーラップを設定し、境界またぎの情報損失を抑える
なぜ重要か:ちょうど境界に来た重要な一文が、どちらのチャンクにも完全には含まれず、検索で取りこぼされる事故が起きます。
失敗3:埋め込みモデルのトークン上限を無視する
❌ 文字数ベースのチャンクサイズだけ見て、モデルのトークン上限を確認しない
⭕ 使う埋め込みモデルの入力トークン上限を確認し、チャンクが上限を超えないようにトークンベースで計測する
なぜ重要か:上限を超えたチャンクは末尾が黙って切り捨てられ、「埋め込んだはずの情報が一部消える」状態になります。気づきにくく、原因究明に時間を取られます。
失敗4:評価セットなしで主観で良し悪しを判断する
❌「なんとなく良くなった気がする」で手法を確定する
⭕ 質問→正解箇所のペアを固定の評価セットにし、Recall@kなどで数値比較する
なぜ重要か:チャンキングの変更は他の要素と絡んで効果が見えにくく、主観だと逆効果の変更を「改善」と誤認します。
まとめ:今日から始める3つのアクション
- 今日やること:
RecursiveCharacterTextSplitter(chunk_size=500 / overlap=50)でベースラインのチャンキングを動かす。 - 今週中:自分のドメインで「質問→正解箇所」のペアを20件作り、固定の評価セットにする。チャンクサイズを3パターン振ってRecall@kを比較する。
- 今月中:技術文書なら構造を意識した分割(Markdown/コード)、文脈不足が課題なら親子チャンク(small-to-big)を導入し、評価セットで効果を確認してから本番反映する。
あわせて読みたい:
- ドキュメント抽出・パース(RAGのingestion)完全ガイド — チャンキングの前段、PDF/HTMLからのテキスト抽出を扱う
- 埋め込みモデル選定ガイド — チャンクサイズの上限を決める埋め込みモデルの選び方
- リランク・ハイブリッド検索ガイド — チャンキング後の検索精度をさらに引き上げる
- AIエージェント実装 完全ロードマップ — RAGを含むエージェント構築の全体像
この記事を読んでRAGの精度改善イメージが固まってきた方へ
UravationではAIエージェント・RAG導入の研修・コンサルティングを行っています。お問い合わせフォームからお気軽にご相談ください。
著者:佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』。
参考・出典
- Splitting recursively — Text splitter integration guide — LangChain公式ドキュメント(参照日: 2026-06-04)
- Splitting code — Text splitter integration guide — LangChain公式ドキュメント(参照日: 2026-06-04)
- How to use the Parent Document Retriever — LangChain公式ドキュメント(参照日: 2026-06-04)
- Node Parser Modules — LlamaIndex公式ドキュメント(参照日: 2026-06-04)
- Introducing Contextual Retrieval — Anthropic公式(参照日: 2026-06-04)
- Is Semantic Chunking Worth the Computational Cost? — Findings of NAACL 2025, Qu, Tu & Bao(参照日: 2026-06-04)


