
結論:LLMアプリ・エージェントの問い合わせは「同じ・似た質問」が想像以上に多く、埋め込み類似度で答えを使い回すセマンティックキャッシュを入れると、ヒットした分のAPI呼び出しがゼロになり、コストとレイテンシを同時に削れます。
- 要点1:完全一致キャッシュは表記ゆれで素通りする。埋め込み類似度でヒット判定する「セマンティックキャッシュ」が効く。
- 要点2:実装はGPTCache(自前ホスト)、RedisVL / Redis LangCache(マネージド寄り)、自前embedding+ベクトル検索の3択。最小10行で動く。
- 要点3:勝負どころは「類似度しきい値の設計」と「誤ヒット・TTL・個人情報のキャッシュ回避」。ここを外すと事故る。
対象読者:LLMアプリ/AIエージェントを設計・運用している開発者・PM。
今日やること:本番ログから「似た質問の繰り返し率」をざっくり数えて、キャッシュ導入の費用対効果を見積もる。
「LLMのAPI課金、思ったより膨らんでるな…」
あるサポート向けエージェントを運用していたとき、月次のトークン課金を眺めていて気づいたことがあります。FAQに近い質問——「料金プランを教えて」「プラン一覧ある?」「いくらかかりますか」——が、表現を変えながら何度も飛んできていました。中身はほぼ同じ。なのに毎回フルでLLMを呼び、毎回トークンを払っていたわけです。
この「似た質問の繰り返し」を吸収できれば、コストもレイテンシも大きく下げられます。それを実現するのがセマンティックキャッシュ。文字列の完全一致ではなく、埋め込み(embedding)の類似度で過去の回答を引き当てる仕組みです。
この記事では、なぜキャッシュが効くのかという原理から、GPTCache・RedisVL・自前実装の最小コード、そして本番でハマりやすい「しきい値設計」「誤ヒット対策」「TTL・個人情報」までを、コピペ可能なコードつきで解説します(2026年6月時点の情報をベースにしています)。
なぜキャッシュが効くのか:問い合わせは「同じ・似た質問」だらけ
LLMアプリの本番トラフィックを観察すると、ユーザーの質問はロングテールに広がっているように見えて、実際は少数の意図に集中します。FAQ・商品問い合わせ・社内ナレッジ検索のようなユースケースでは特に顕著で、「同じ意図だが言い回しが違う」クエリが繰り返し届きます。
ここで2種類のキャッシュを区別しておきましょう。混同すると設計を間違えます。
- プロンプトキャッシュ(プロバイダ側の機能):Anthropic・OpenAIなどLLMプロバイダが提供する、プロンプトの先頭から一致する共通部分(プレフィックス)を再利用してコストとレイテンシを下げる機能。長いシステムプロンプトやツール定義を使い回すときに効く。あくまで「入力の前方一致」が前提。
- セマンティックキャッシュ(アプリ側の実装):あなたのアプリ側で、過去の質問と回答を保存しておき、新しい質問の意味が近ければ回答ごと使い回す仕組み。ヒットすればLLM呼び出し自体が発生しない。
本記事で扱うのは後者の「セマンティックキャッシュ」です。前者のプロンプトキャッシュは別の最適化軸なので、両方を併用するのが現実解になります(詳しくは後述)。
完全一致キャッシュではなぜ足りないのか
最もシンプルなキャッシュは、質問文字列をキーにした完全一致(exact match)です。PythonのdictやRedisのKVで一瞬で作れます。ですが、人間の自然言語では同じ意図でも表記がブレます。
# 完全一致キャッシュ(意図は同じでもキーが違うとヒットしない)
cache = {}
def ask_exact(question, llm_call):
if question in cache: # 文字列が1文字でも違えば素通り
return cache[question]
answer = llm_call(question)
cache[question] = answer
return answer
# 下の3つは「意図が同じ」だが、完全一致では全部キャッシュミス
ask_exact("料金プランを教えて", llm) # ミス → LLM呼び出し
ask_exact("プラン一覧ある?", llm) # ミス → LLM呼び出し
ask_exact("いくらかかりますか", llm) # ミス → LLM呼び出し
- ポイント:完全一致は「正規化したキー(小文字化・空白除去)」を使えば多少改善しますが、語順・言い換え・敬語の違いには無力です。FAQのように「意味は同じ」クエリが多い場面では、ヒット率が伸びません。
セマンティックキャッシュの仕組み:埋め込み類似度でヒット判定
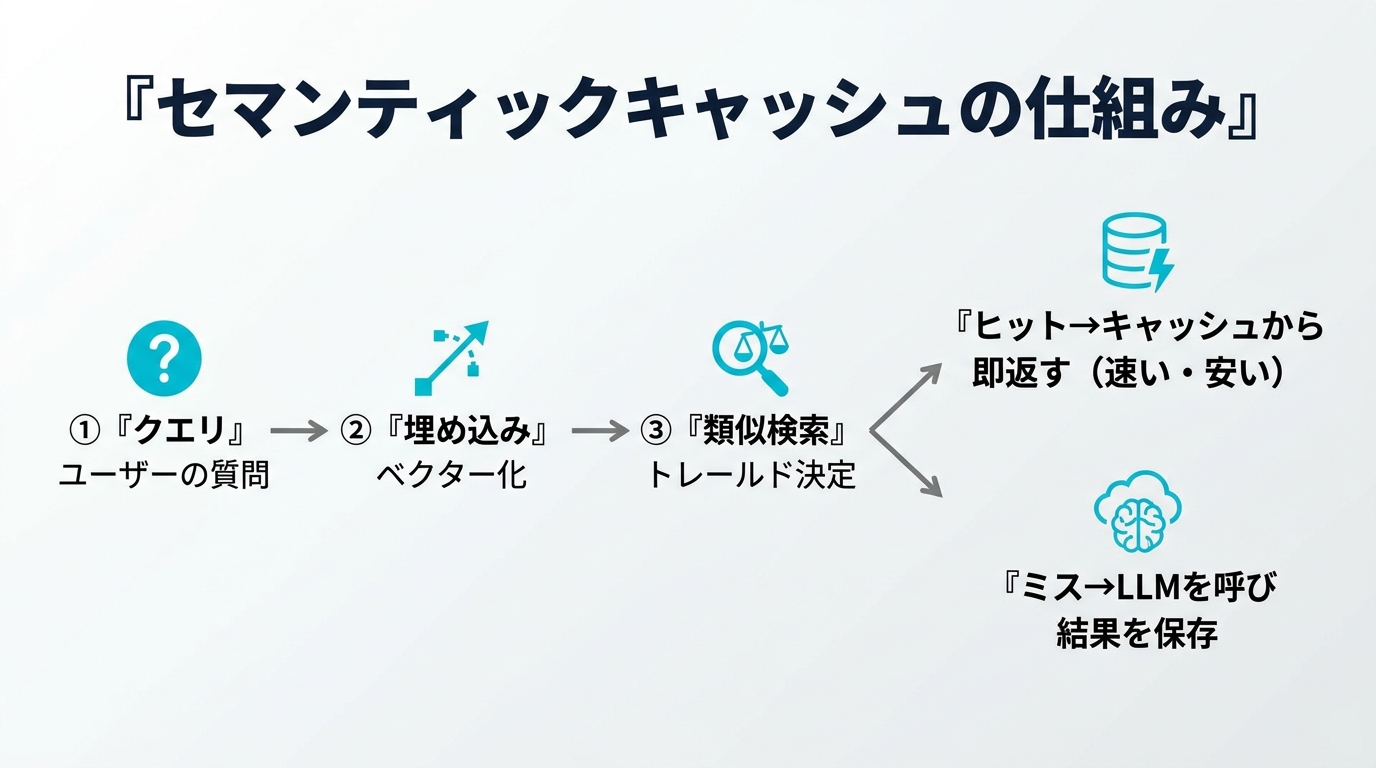
セマンティックキャッシュは、質問を埋め込みベクトルに変換し、過去の質問ベクトルとの類似度(一般的にコサイン類似度)を計算します。最も近い過去クエリが、設定したしきい値(threshold)を超えていれば、その回答をそのまま返す——というのが基本動作です。
処理の流れを整理すると次の通りです。
- 埋め込み化:新しい質問を埋め込みモデルでベクトルに変換する。
- 類似検索:ベクトルストアに対して最近傍検索(ANN)を行い、最も近い過去クエリを取得する。
- しきい値判定:類似度がしきい値以上ならキャッシュヒット → 保存済み回答を返す(LLM呼び出しなし)。
- ミス時の保存:しきい値未満ならキャッシュミス → LLMを呼び、質問ベクトル+回答をストアに保存する。
キャッシュヒット時はLLMを叩かないため、レイテンシは埋め込み計算+ベクトル検索の時間だけになります。複数の公開ベンチマークやライブラリのドキュメントでは、ヒット時の応答が数ミリ秒〜十数ミリ秒オーダーまで短縮される一方、ミス時(=実際のLLM呼び出し)は数百ミリ秒〜数秒かかると報告されています。つまりヒット率がそのまま効果に直結します。
ベクトル検索の基礎やストアの選び方は、ベクトルデータベース比較ガイド、埋め込みモデルの選定は埋め込みモデル選定ガイドも合わせて読むと、キャッシュ層の設計判断がしやすくなります。
実装1:GPTCache(自前ホストで一番リッチ)
GPTCacheは、LLM向けのセマンティックキャッシュをOSSで提供するライブラリです。LangChainやllama_indexと統合でき、埋め込み関数・ベクトルストア・類似度評価をそれぞれ差し替えられる柔軟さが特徴です(公式リポジトリはzilliztech/GPTCache)。
動作環境:Python 3.8+ / gptcache。ローカル埋め込み(ONNX)+FAISS+SQLiteで完結する最小構成を示します。
# pip install gptcache
# 注意: 本番で使う前に、必ずテスト環境で動作確認してください。
from gptcache import cache
from gptcache.adapter import openai
from gptcache.embedding import Onnx
from gptcache.manager import CacheBase, VectorBase, get_data_manager
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluation
# 1) 埋め込み関数(ローカルONNXモデル。APIキー不要)
onnx = Onnx()
# 2) データマネージャ: スカラ保存(SQLite) + ベクトル検索(FAISS)
data_manager = get_data_manager(
CacheBase("sqlite"),
VectorBase("faiss", dimension=onnx.dimension),
)
# 3) キャッシュ初期化(埋め込み・ストア・類似度評価をひも付け)
cache.init(
embedding_func=onnx.to_embeddings,
data_manager=data_manager,
similarity_evaluation=SearchDistanceEvaluation(),
)
cache.set_openai_key() # ミス時のLLM呼び出し用
# 4) いつものOpenAI呼び出しに見えるが、裏でキャッシュが効く
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": "料金プランを教えて"}],
)
- ポイント1:
adapter経由でOpenAI呼び出しをラップするため、アプリ側のコードはほぼそのままでキャッシュを差し込めます。 - ポイント2:埋め込みは
Onnx(ローカル)以外にOpenAI埋め込みなどに差し替え可能。ベクトルストアもFAISS以外を選べます。 - ポイント3:類似度評価の
SearchDistanceEvaluationは距離ベース。後述のしきい値(一致と判定する境界)の調整がコスト/品質に直結します。
実装2:RedisVL / Redis LangCache(運用に乗せやすい)
すでにRedisを使っているチームなら、RedisVLのSemanticCacheが手早く導入できます。Redisのベクトル検索を使い、意味が近い過去質問の回答を返します。
動作環境:Python / redisvl + 稼働中のRedis(Redis Stack等)。
# pip install redisvl
from redisvl.extensions.cache.llm import SemanticCache
llmcache = SemanticCache(
name="llmcache",
redis_url="redis://localhost:6379",
distance_threshold=0.1, # COSINE距離[0-2]: 0=完全一致, 2=完全に別物。小さいほど厳しい
)
# 保存(質問と回答をペアで)
llmcache.store(
prompt="フランスの首都はどこ?",
response="パリです。",
)
# 取得: 意味が近い質問ならヒットする
hit = llmcache.check(prompt="フランスの首都を教えて")
if hit:
answer = hit[0]["response"] # キャッシュ命中 → LLM呼び出し不要
else:
answer = call_llm("フランスの首都を教えて") # ミス → LLMへ
llmcache.store(prompt="フランスの首都を教えて", response=answer)
- ポイント1:RedisVLは
distance_thresholdが「距離」基準(COSINE距離 0〜2)である点に注意。値が小さいほど厳しい判定で、類似度しきい値(大きいほど厳しい)とは向きが逆です。混同すると誤ヒットが激増します。 - ポイント2:自分でRedisを運用したくない場合は、埋め込み生成・類似検索・キャッシュ管理をAPI側で巻き取るRedis LangCache(マネージドサービス)という選択肢もあります。インフラ運用を減らせる代わりに、外部サービスにクエリが渡る点はプライバシー設計で要考慮です。
実装3:自前embedding+ベクトル検索(中身を全部握る)
「ライブラリのブラックボックスは嫌だ」「既存のベクトルDBに相乗りしたい」というケースでは、埋め込みAPIとベクトル検索を直接組んで、最小限のセマンティックキャッシュを自作できます。コサイン類似度を自前で計算する例です。
import numpy as np
class SimpleSemanticCache:
def __init__(self, embed_fn, threshold=0.90):
self.embed_fn = embed_fn # 質問 -> ベクトル(np.array) を返す関数
self.threshold = threshold # コサイン類似度の下限(大きいほど厳しい)
self.vectors = [] # 保存した質問ベクトル
self.answers = [] # 対応する回答
def _cosine(self, a, b):
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))
def check(self, question):
if not self.vectors:
return None
q = self.embed_fn(question)
sims = [self._cosine(q, v) for v in self.vectors]
best = int(np.argmax(sims))
if sims[best] >= self.threshold: # しきい値以上ならヒット
return self.answers[best]
return None
def store(self, question, answer):
self.vectors.append(self.embed_fn(question))
self.answers.append(answer)
# 使い方
sc = SimpleSemanticCache(embed_fn=my_embed, threshold=0.90)
def ask(question, llm_call):
cached = sc.check(question)
if cached is not None:
return cached # キャッシュヒット → LLM不要
answer = llm_call(question)
sc.store(question, answer) # ミス → LLMを呼んで保存
return answer
- ポイント1:このリスト走査は学習用です。本番でクエリ数が増えたら、必ずANN(近似最近傍)対応のベクトルストアに置き換えてください。線形探索はクエリ数に比例して遅くなります。
- ポイント2:埋め込みモデルを途中で変えると、ベクトル空間が変わって既存キャッシュと整合しなくなります。モデルを変えたらキャッシュは作り直す前提で。
類似度しきい値の設計と誤ヒット(false hit)対策
セマンティックキャッシュで最も重要かつ唯一の正解がないのが、しきい値の設計です。緩すぎれば「意味の違う質問に古い回答を返す」誤ヒット(false hit)が起き、厳しすぎればヒット率が伸びずコスト削減効果が薄れます。
各種ドキュメントやベンチマークでは、コサイン類似度でおおむね0.85〜0.95あたりを起点に、自分のデータで調整するという指針が共通して挙げられています(一例として、まず0.88前後から始めて調整する、という推奨もあります)。ただしこれはあくまで出発点で、扱うドメインの語彙のばらつきによって最適値は変わります。
| 設定 | 挙動 | 主なリスク |
|---|---|---|
| しきい値が緩い(例: 類似度0.80) | ヒット率が上がる | 誤ヒット増。別意図に間違った回答を返す |
| しきい値が厳しい(例: 類似度0.95) | 誤ヒットが減る | ヒット率が下がり、コスト削減効果が小さい |
| 距離基準(RedisVL等) | 値が小さいほど厳しい | 類似度基準と向きが逆。設定ミスで事故る |
【要注意】よくある失敗パターンと回避策
- 失敗1:しきい値を勘で決めて本番投入する。
❌「とりあえず0.8でいいだろう」→ 誤ヒットでサポート品質が落ちる。
⭕ 本番ログから「意味が同じ質問ペア/違う質問ペア」を各50件ほど人手でラベル付けし、しきい値を振って誤ヒット率とヒット率のトレードオフを実測してから決める。 - 失敗2:否定・数値・固有名詞を含むクエリで素通り誤ヒット。
❌「返金できますか」と「返金できませんか」が高類似度で同じ回答にヒット。
⭕ 否定・日付・金額・IDなど「1語で意味が反転する」要素を含むクエリはキャッシュ対象外にする、または別キーで分離する。 - 失敗3:パーソナライズされた回答をキャッシュして他人に出す。
❌「私の注文状況は?」のようにユーザー固有の回答を共有キャッシュに保存。
⭕ ユーザー文脈に依存する回答はキャッシュしない。汎用FAQ・一般知識クエリだけをキャッシュ対象にする。
しきい値だけでは誤ヒットを完全には潰せません。実務では「キャッシュ対象クエリの絞り込み(汎用質問だけ)」と「しきい値調整」を組み合わせるのが現実的です。エージェントの文脈管理・前処理の考え方はコンテキストエンジニアリング・ガイドも参考になります。
TTL・無効化・プライバシー:本番で必須の運用設計
キャッシュは「入れたら終わり」ではありません。古い回答を返し続けないための運用設計が要ります。
- TTL(有効期限)を設定する:料金・在庫・仕様など変わる情報はTTLを短く(数分〜数時間)、普遍的なFAQは長めに。ストア側のTTL機能やキー単位の期限で管理する。
- 明示的な無効化(invalidation):料金改定・FAQ更新など「答えが変わるイベント」が起きたら、該当範囲のキャッシュを能動的にパージできる導線を用意する。タグ付け(例:
plan関連キャッシュ)して一括削除できると運用が楽。 - 個人情報をキャッシュしない:氏名・メール・注文番号・住所などPIIを含むクエリや回答は、そもそもキャッシュ対象から除外する。共有キャッシュにPIIを入れると、別ユーザーへの漏えいや保持期間違反のリスクが直結する。前段でPII検出フィルタを噛ませる。
- ポイント:「キャッシュしてよいクエリかどうか」を判定するゲートを、類似検索の前段に置くのが安全です。PII・ユーザー固有・時間依存のクエリはここで弾く。
プロンプトキャッシュとの併用:別レイヤーとして両取りする
冒頭で触れた通り、プロバイダ側のプロンプトキャッシュとアプリ側のセマンティックキャッシュは競合せず、併用できます。
| 項目 | プロンプトキャッシュ(プロバイダ側) | セマンティックキャッシュ(アプリ側) |
|---|---|---|
| ヒット条件 | プロンプト先頭のプレフィックス一致 | 質問の意味の近さ(埋め込み類似度) |
| LLM呼び出し | 発生する(入力処理が安くなる) | ヒット時は発生しない |
| 代表例 | Anthropic cache_control(ephemeral)、OpenAIの自動プロンプトキャッシュ |
GPTCache、RedisVL/LangCache、自前実装 |
| 主な効果 | 長い共通プロンプトの入力コスト・初動レイテンシ削減 | 繰り返し質問の呼び出しそのものを削減 |
2026年6月時点で、Anthropicのプロンプトキャッシュはcache_controlで明示的にキャッシュ範囲を指定する方式(デフォルト約5分、追加コストで1時間TTLも選択可、キャッシュ読み取りは入力トークン価格の0.1倍)です。一方OpenAIは一定長以上(1,024トークン以上)のプロンプトで自動的に効き、数分の無操作で失効する仕組みです(いずれも公式ドキュメント基準)。長い共通システムプロンプト=プロンプトキャッシュ、繰り返しFAQ=セマンティックキャッシュ、と役割分担して両方使うのが効率的です。
効果測定:ヒット率とコスト削減を数字で追う
導入したら、感覚ではなく数字で効果を見ます。最低限とるべき指標は次の3つです。
- キャッシュヒット率:ヒット数 ÷ 全リクエスト数。これが効果の主指標。
- 誤ヒット率:サンプリングで人手チェック。ヒットした回答が本当に正しかったかを定期監査する。
- コスト削減額:ヒット数 × ミス時の平均トークン課金。レイテンシ短縮分も合わせて記録。
# ざっくり効果測定のスケルトン
stats = {"total": 0, "hit": 0}
def ask_with_metrics(question, cache, llm_call):
stats["total"] += 1
cached = cache.check(question)
if cached is not None:
stats["hit"] += 1
return cached
return llm_call(question)
def report(avg_cost_per_miss_yen):
hit_rate = stats["hit"] / max(stats["total"], 1)
saved = stats["hit"] * avg_cost_per_miss_yen # ヒット分の呼び出しコスト削減
print(f"ヒット率: {hit_rate:.1%} / 推定削減: ¥{saved:,.0f}")
- ポイント:削減額だけでなく誤ヒット率を必ずセットで監視してください。コストが下がっても、間違った回答を返していたら本末転倒です。ヒット率と誤ヒット率の両にらみで、しきい値を継続的にチューニングするのが正しい運用です。
まとめ:今日から始める3つのアクション
- 今日やること:本番ログから直近1,000件の質問を抜き出し、「意味が同じ質問」がどれくらい繰り返されているかをざっくり数える。繰り返し率が高ければ、セマンティックキャッシュの費用対効果は大きい。
- 今週中:GPTCacheかRedisVLで、汎用FAQクエリだけを対象にした最小キャッシュをテスト環境に立てる。しきい値はまず厳しめ(例: 類似度0.9)から。
- 今月中:ヒット率・誤ヒット率・コスト削減額を計測し、しきい値を実データで調整。TTLとPII除外ゲートを入れて本番投入する。
あわせて読みたい:
- ベクトルデータベース比較ガイド — キャッシュの検索層に何を選ぶかの判断材料
- 埋め込みモデル選定ガイド — 類似度の質を左右する埋め込みモデルの選び方
- AIエージェント実装完全ロードマップ — キャッシュを含む全体設計の中での位置づけ
この記事を読んで導入イメージが固まってきた方へ
UravationではAIエージェント導入の研修・コンサルを行っています。コスト最適化を含めた本番運用設計まで伴走します。
著者:佐藤傑(さとう・すぐる)。株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー10万人超。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』。
参考・出典
- GPTCache(zilliztech/GPTCache) — GitHub公式リポジトリ(参照日: 2026-06-04)
- GPTCache Documentation — 公式ドキュメント(参照日: 2026-06-04)
- Semantic Caching for LLMs — RedisVL — Redis公式ドキュメント(参照日: 2026-06-04)
- Semantic caching with Redis LangCache — Redis公式チュートリアル(参照日: 2026-06-04)
- Prompt caching — Claude API Docs — Anthropic公式(参照日: 2026-06-04)
- Prompt caching — OpenAI Docs — OpenAI公式(参照日: 2026-06-04)
- GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching — arXiv(参照日: 2026-06-04)


