
結論: マルチテナントAIアプリの設計は「データ分離・設定管理・コスト計測・公平性制御」の4層をテナント単位で一貫させることが核心であり、なかでもベクトルストアとDBの分離方式の選択が漏洩リスクと運用コストを左右します。
この記事の要点:
- 要点1: テナント分離には「行レベル(メタデータフィルタ)」「スキーマ/namespace」「インスタンス分離」の3方式があり、テナント数とコンプライアンス要件でトレードオフが決まる
- 要点2: LLMのコストはテナントごとの入出力トークンを計測してはじめて配賦できる。利用量の記録をアプリ層で必ず残す
- 要点3: 1テナントがリソースを占有しないよう、テナント単位のレート制限とコスト上限(バジェット)を設計段階で組み込む
対象読者: 複数の顧客企業に1つのAIアプリ/RAGを提供する開発者・SaaSアーキテクト
難易度: 中級〜上級
読了時間: 約14分
「自社で作ったRAGチャットボットを、複数の顧客企業に同じ基盤で提供したい。でも、A社のドキュメントがB社の回答に混ざったら一発で信頼を失う——」。マルチテナント化を検討し始めた開発者が最初にぶつかるのが、この「分離をどう保証するか」という問いです。
SaaSとしてAIアプリを提供する以上、テナント(顧客)ごとにデータ・設定・利用量を確実に分けることは機能要件ではなく、事業継続の前提条件です。ところが、シングルテナントで動いていたプロトタイプをそのままマルチテナント化すると、ベクトル検索のフィルタ漏れ、プロンプトの取り違え、特定テナントによるAPI占有といった、シングルテナントでは存在しなかった事故が一気に表面化します。
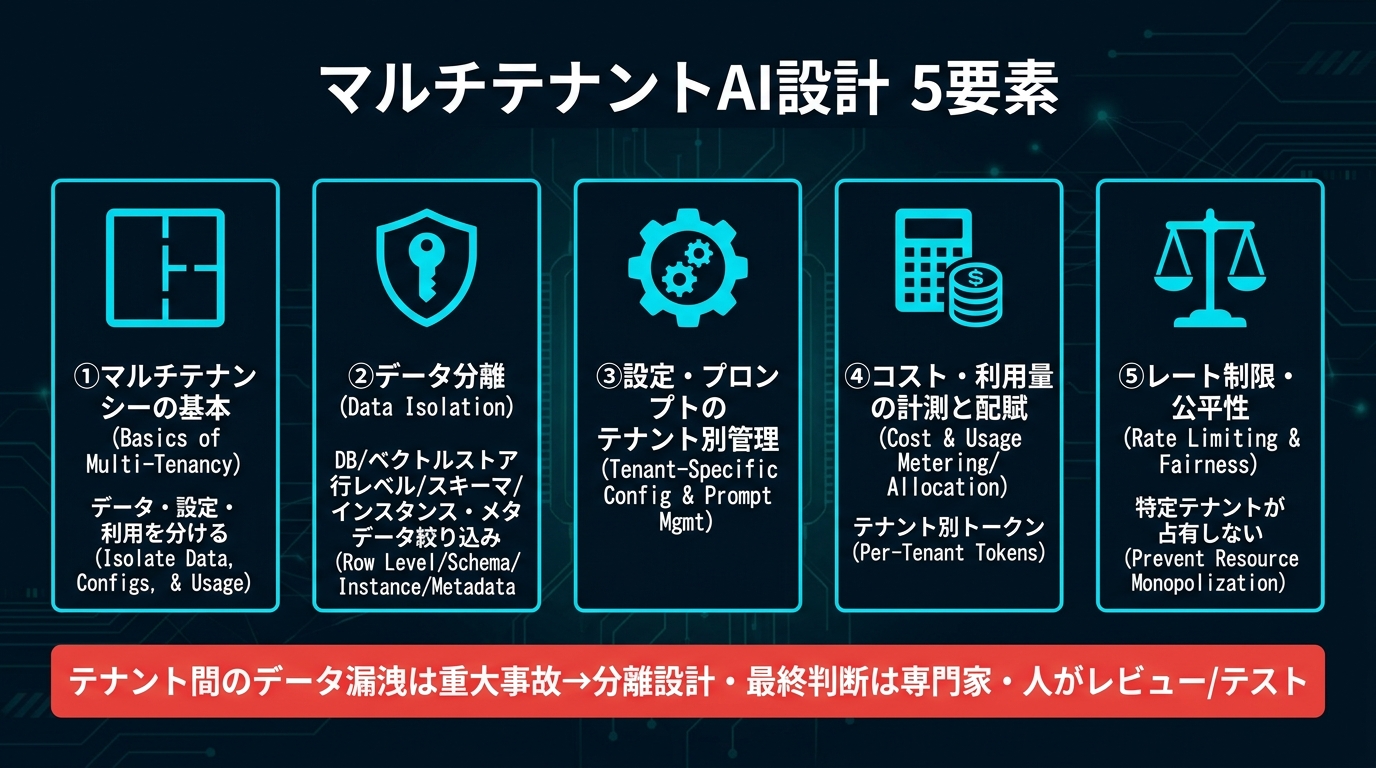
この記事では、マルチテナントAIアプリの設計を「①マルチテナンシーの基本 → ②データ分離 → ③設定・プロンプト管理 → ④コスト計測・配賦 → ⑤レート制限・公平性」の順に、実装イメージ付きで開発者向けに解説します。最後まで読めば、どの分離方式を選ぶべきか、コストをどう配賦するかの判断軸が手に入ります。なお本記事の情報は2026年6月時点のものであり、各サービスの仕様・料金は変わるため、最終的な分離設計とセキュリティ判断は専門家・人によるレビューとテストを前提としてください。
マルチテナンシーの基本 — 何を「分ける」のか
マルチテナンシーとは、1つのアプリケーション・インフラを複数のテナント(顧客)で共有しつつ、各テナントから見ると「自分専用のシステム」に見える状態を作る設計です。AIアプリの場合、分ける対象は大きく次の4つに整理できます。
| 分離の対象 | 具体例 | 漏洩したときの影響 |
|---|---|---|
| データ | RAGのドキュメント、ベクトル、会話履歴 | 他社の機密情報が回答に混入(重大事故) |
| 設定 | システムプロンプト、使用モデル、ツール権限 | 意図しない挙動・ブランド毀損 |
| 利用量 | トークン数、API呼び出し数、コスト | 請求の取り違え・コスト配賦不能 |
| 権限 | テナント内のユーザー・ロール | テナント内での不正アクセス |
この4つを貫く共通ルールが「リクエストのライフサイクル全体でtenant_idを必ず伝搬させる」ことです。認証で確定したテナントIDを、DBクエリ・ベクトル検索・プロンプト構築・利用量記録のすべてに渡し、どこか一箇所でも欠けると分離が崩れます。
まず、リクエスト処理の入り口でtenant_idを確定し、それ以降のすべての処理に文脈として渡す骨格を作ります。アプリ層でtenant_idを引数として明示的に引き回す設計にしておくと、テストでもフィルタ漏れを検知しやすくなります。
# テナント文脈をリクエスト全体で持ち回す(FastAPI の例)
from dataclasses import dataclass
from fastapi import Depends, HTTPException, Request
@dataclass(frozen=True)
class TenantContext:
tenant_id: str
plan: str # "free" / "pro" / "enterprise"
user_id: str
async def resolve_tenant(request: Request) -> TenantContext:
# 実運用では JWT / API キーの検証結果から取得する
claims = request.state.auth_claims
tenant_id = claims.get("tenant_id")
if not tenant_id:
raise HTTPException(status_code=401, detail="tenant_id missing")
return TenantContext(
tenant_id=tenant_id,
plan=claims.get("plan", "free"),
user_id=claims.get("sub"),
)
@app.post("/chat")
async def chat(body: ChatRequest, tenant: TenantContext = Depends(resolve_tenant)):
# 以降の DB / ベクトル検索 / 利用量記録に必ず tenant を渡す
docs = retrieve(query=body.message, tenant=tenant)
answer = generate(query=body.message, docs=docs, tenant=tenant)
return {"answer": answer}
AIエージェントを多顧客に提供する全体像と必須技術の地図は、AIエージェント実装ロードマップ|RAG・実行・運用の必須技術でも整理しています。本記事はその「運用」レイヤーをマルチテナント観点で深掘りするものです。
データ分離 — DBとベクトルストアの3つの方式
データ分離の方式選択が、マルチテナントAIアプリ設計で最も重い意思決定です。Microsoftのマルチテナント設計ガイドでも、テナンシーモデルは「分離度・コスト・運用負荷」のトレードオフとして整理されています。AIアプリでは「リレーショナルDB側」と「ベクトルストア側」の両方で方式を決める必要があります。
3つの分離方式
| 方式 | 分離単位 | 分離強度 | 運用コスト | 向くケース |
|---|---|---|---|---|
行レベル分離(共有テーブル + tenant_id列) |
1行ごと | 低〜中 | 低 | テナント数が多い・小〜中規模 |
| スキーマ/namespace分離 | スキーマ・名前空間 | 中 | 中 | 中規模・テナントごとに構造を変えたい |
| インスタンス分離(DB/インデックスを物理分離) | DB・インデックス丸ごと | 高 | 高 | 少数の大口・厳格なコンプライアンス要件 |
方式1: 行レベル分離(RLS)
共有テーブルにtenant_id列を持たせ、すべてのクエリでこの列を条件に絞ります。アプリ側のWHERE tenant_id = ?だけに頼るとコードのどこか一箇所のミスで漏洩するため、PostgreSQLのRow Level Security(RLS)でデータベース層に分離を強制するのが定石です。RLSはテーブルにポリシーを設定し、セッション変数で渡したテナントIDに一致する行だけを返すようにできます。
-- ドキュメントテーブルに RLS を設定(PostgreSQL)
ALTER TABLE documents ENABLE ROW LEVEL SECURITY;
ALTER TABLE documents FORCE ROW LEVEL SECURITY; -- テーブル所有者にも適用
-- セッション変数 app.tenant_id と一致する行だけ可視にする
CREATE POLICY tenant_isolation ON documents
USING (tenant_id = current_setting('app.tenant_id')::uuid);
-- アプリ側: 各トランザクションの冒頭でテナントを宣言
-- SET LOCAL app.tenant_id = '...'; → 以降のクエリは自動で絞られる
RLSを使うと、アプリのクエリにWHERE tenant_idを書き忘れても、DBが自動で他テナントの行を除外します。「アプリ層フィルタ + DB層RLS」の二重防御がマルチテナントの基本姿勢です。
方式2・3: ベクトルストアの分離
RAGのベクトルストアは、製品ごとに推奨される分離手段が異なります。たとえばPineconeはマルチテナンシーの実装手段としてnamespace(インデックス内の論理区画)を推奨しており、テナントごとにnamespaceを分けると、検索が常にそのnamespace内に閉じます。Qdrantは単一コレクションにテナントを識別するペイロードキー(例: group_id)を持たせ、メタデータフィルタで絞る方式を案内しています。
# パターンA: Pinecone — namespace でテナントを分離
index.query(
namespace=tenant.tenant_id, # ← テナントごとに名前空間を分ける
vector=embedding,
top_k=5,
)
# パターンB: Qdrant — 共有コレクション + ペイロードフィルタ
from qdrant_client import models
client.query_points(
collection_name="documents",
query=embedding,
query_filter=models.Filter(
must=[models.FieldCondition(
key="tenant_id",
match=models.MatchValue(value=tenant.tenant_id),
)]
),
limit=5,
)
メタデータフィルタ方式(行レベルに相当)は安価でテナント数を増やしやすい一方、フィルタの付け忘れが即漏洩につながります。namespace/インデックス分離はより強固ですが、テナント数が数万を超えると管理オブジェクトが膨らみます。ベクトルストアの製品選定そのものは、ベクトルデータベース比較ガイドで各製品の特性を確認してください。RAG全体のPII・アクセス制御の考え方はRAGのデータセキュリティ実装ガイドと合わせて読むと、テナント分離と権限設計の両面を押さえられます。
設定・プロンプトのテナント別管理
多くのSaaS型AIアプリは、テナントごとに「システムプロンプト」「使えるツール」「使用モデル」「ブランドの口調」を変えたいという要件を持ちます。これらをコードにハードコードすると、テナント追加のたびにデプロイが必要になり、取り違えの温床にもなります。設定はデータとして外部化し、tenant_idで引けるようにするのが基本です。
| 設定項目 | 例 | テナント差分の理由 |
|---|---|---|
| システムプロンプト | 口調・禁止事項・FAQ | 顧客ブランド・業種で変える |
| 使用モデル | 上位モデル / 軽量モデル | プラン(料金)による出し分け |
| ツール権限 | 外部API・社内DB接続の可否 | 契約・セキュリティ要件 |
| RAG対象 | 参照するnamespace | テナントのドキュメント空間 |
設定はバージョン管理し、プロンプトの変更履歴を追えるようにしておくと、回答品質が劣化したときに原因を特定しやすくなります。プロンプトを本番で管理する運用の詳細は別途PromptOpsの観点で設計するとよいでしょう。実装としては、テナント設定をストアから取得し、プロンプト構築・モデル選択・ツール選択に反映させます。
# テナント設定をストアから取得し、生成処理に反映
def load_tenant_config(tenant_id: str) -> dict:
# DB / 設定サービスから取得(キャッシュ推奨)
return config_store.get(tenant_id)
def build_messages(query: str, docs: list[str], tenant: TenantContext) -> list[dict]:
cfg = load_tenant_config(tenant.tenant_id)
system_prompt = cfg["system_prompt"] # テナント固有の口調・禁止事項
context = "nn".join(docs)
return [
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"参考情報:n{context}nn質問: {query}"},
]
def pick_model(tenant: TenantContext) -> str:
cfg = load_tenant_config(tenant.tenant_id)
# プランに応じて使用モデルを出し分け(コスト最適化)
return cfg.get("model", "default-small-model")
会話履歴やセッション状態もテナント単位で分離する必要があります。マルチターン会話のメモリ設計はAIエージェントの状態・会話履歴・セッション管理ガイドを参照し、履歴の保存キーに必ずtenant_idを含めてください。
コスト・利用量の計測と配賦
マルチテナントAIアプリ最大の運用課題が「どのテナントがいくら使ったか」を正確に把握することです。LLMのコストは入力・出力トークン数で決まりますが、LLMプロバイダー側の請求はアカウント単位の合算であり、テナント別には分かれていません。そのため、テナント別配賦はアプリ層で利用量を記録するしかありません。
計測の手順
- 各LLM呼び出しのレスポンスから
usage(入力・出力トークン数)を取得する tenant_id・モデル名・トークン数・タイムスタンプをイベントとして記録する- モデル別の単価表とトークン数を掛けてコストに換算する
- テナント・期間で集計し、請求や利用ダッシュボードに反映する
OpenAIやAnthropicのAPIはレスポンスにトークン使用量を含めて返すため、これを取りこぼさず記録します。プロンプトキャッシュを使う場合、キャッシュ読み込み分のトークンは通常より割安に課金されるため、配賦の精度を上げるならキャッシュヒット分も区別して記録します。
# LLM 呼び出しごとに利用量を記録する
def generate(query: str, docs: list[str], tenant: TenantContext) -> str:
model = pick_model(tenant)
messages = build_messages(query, docs, tenant)
resp = llm_client.create(model=model, messages=messages)
usage = resp.usage # 入力・出力トークン数
record_usage_event(
tenant_id=tenant.tenant_id,
model=model,
input_tokens=usage.input_tokens,
output_tokens=usage.output_tokens,
cached_input_tokens=getattr(usage, "cached_input_tokens", 0),
)
return resp.text
# モデル別単価でコスト換算(単価は2026年6月時点・要最新確認)
PRICE = { # USD / 1M tokens
"model-small": {"in": 0.15, "out": 0.60},
"model-large": {"in": 3.00, "out": 15.00},
}
def to_cost_usd(model: str, in_tok: int, out_tok: int) -> float:
p = PRICE[model]
return in_tok / 1_000_000 * p["in"] + out_tok / 1_000_000 * p["out"]
埋め込み(Embedding)生成やベクトル検索の従量課金もテナント別に記録しておくと、RAGの利用が重いテナントを特定でき、プラン設計の根拠になります。配賦のための単価はモデル更新で変わるため、コードに直書きせず単価表をデータ化し、参照日とともに管理してください。
レート制限と公平性 — 1テナントに占有させない
共有インフラの最大の弱点は「1テナントの暴走が全テナントに波及する」ことです。あるテナントが大量リクエストを送ると、LLMプロバイダー側のアカウント全体のレート上限に達し、他テナントまで応答できなくなる——いわゆる「ノイジーネイバー(騒がしい隣人)」問題です。OpenAIなどのプロバイダーは1分あたりのリクエスト数(RPM)やトークン数(TPM)に上限を設けているため、その上限をテナント間で公平に配分する制御が要ります。
2層のレート制限
| 層 | 目的 | 実装例 |
|---|---|---|
| テナント別レート制限 | 1テナントの占有を防ぐ | プラン別のRPM/TPM上限(トークンバケット) |
| テナント別コスト上限(バジェット) | 請求の暴発・濫用を防ぐ | 月次/日次のコスト累計でしきい値超過時にブロック |
レート制限はトークンバケット方式が扱いやすく、テナントごとにプランに応じた補充レートを設定します。コスト上限は前述の利用量記録を使い、累計が予算を超えたら新規リクエストを拒否(またはキューイング)します。
# テナント別レート制限(Redis トークンバケットの概念例)
PLAN_LIMITS = { # 1分あたり許可リクエスト数
"free": 20,
"pro": 200,
"enterprise": 2000,
}
async def allow_request(tenant: TenantContext) -> bool:
limit = PLAN_LIMITS[tenant.plan]
key = f"ratelimit:{tenant.tenant_id}:{current_minute()}"
count = await redis.incr(key)
if count == 1:
await redis.expire(key, 60)
return count <= limit
# 月次コスト上限(バジェット)チェック
async def within_budget(tenant: TenantContext) -> bool:
cfg = load_tenant_config(tenant.tenant_id)
spent = await get_month_cost(tenant.tenant_id)
return spent < cfg.get("monthly_budget_usd", float("inf"))
さらに公平性を高めるなら、テナントごとにリクエストをキューイングし、優先度付きで処理する設計も有効です。重い処理(大量ドキュメントの一括埋め込みなど)は同期APIではなく非同期ジョブに回し、テナント単位で並列度を制限すると、対話レイテンシへの影響を抑えられます。
【注意】マルチテナント設計でハマりやすいポイント
失敗1: メタデータフィルタの付け忘れ
❌ ベクトル検索でテナントフィルタを書き忘れ、全テナント横断で検索してしまう
⭕ フィルタを必須化したラッパー関数を1箇所だけ用意し、生のクライアントを直接呼ばせない。テストで他テナントのデータがヒットしないことを検証する
失敗2: アプリ層フィルタだけに依存する
❌ WHERE tenant_id = ?のアプリ実装だけで分離した気になる
⭕ DB層のRLS、ベクトルストアのnamespace/フィルタなど、インフラ層でも分離を強制し二重防御にする
失敗3: 利用量を記録せず後から配賦しようとする
❌ コストが膨らんでからテナント別内訳を出そうとしても、過去のトークン数が残っていない
⭕ 最初の1呼び出しからusageイベントを記録する。記録は後付けできない
失敗4: 設定をコードにハードコードする
❌ テナント追加のたびにプロンプトやモデル名をコード変更・デプロイする
⭕ 設定をデータ化しtenant_idで引く。デプロイなしでテナントを追加・変更できる状態にする
失敗5: 分離テストを自動化しない
❌ 手動確認だけで「漏れていないはず」と本番に出す
⭕ 「テナントAの認証でテナントBのデータが取れないこと」を自動テスト化する。テナント間漏洩は重大事故であり、最終的な分離設計とセキュリティ判断は専門家・人によるレビューとテストを必須とする
まとめ: 今日から始める3つのアクション
- 今日: 既存コードでリクエスト処理の入り口から出口まで
tenant_idが伝搬しているかを追跡し、欠けている箇所を洗い出す - 今週中: ベクトルストアとDBの分離方式を決め、アプリ層フィルタに加えてRLSやnamespaceでのインフラ層分離を1つ追加する
- 今月中: LLM呼び出しごとの
usage記録とテナント別レート制限を実装し、テナント間漏洩を検知する自動テストを整備する
AIエージェント・ツールの最新情報をキャッチアップしたい方へ
Agent Labでは、週1回のニュースレターでAIツールの最新比較・活用事例をお届けしています。
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』(SBクリエイティブ)。
ご質問・ご相談は お問い合わせフォーム からお気軽にどうぞ。
参考・出典
- Tenancy models for a multitenant solution — Microsoft Azure Architecture Center(参照日: 2026-06-06)
- Row Security Policies — PostgreSQL 公式ドキュメント(参照日: 2026-06-06)
- Row Level Security — Supabase Docs(参照日: 2026-06-06)
- Implement multitenancy — Pinecone Docs(参照日: 2026-06-06)
- Configure Multitenancy — Qdrant Documentation(参照日: 2026-06-06)
- Rate limits — OpenAI Platform Docs(参照日: 2026-06-06)
- Tenant isolation — AWS SaaS Architecture Fundamentals(参照日: 2026-06-06)


