
「プロンプトを工夫したのに、複雑なタスクになると途端に破綻する」——AIエージェントを実装している開発者なら、一度は突き当たる壁です。原因の多くは、モデルの性能ではなく思考ループの設計にあります。1つのエージェントが「考えて・行動して・観察して・振り返る」サイクルをどう回すか。ReAct、Plan-and-Execute、Reflexion、Tree of Thoughts——これらは複数エージェントの分担ではなく、単一エージェントの推論パターンです。本記事では各パターンの出典(論文)を一次情報で確認しながら、設計の勘所と使い分けを2026年6月時点の知見で整理します。
なぜ「思考ループ」の設計が重要なのか
LLMに1回だけプロンプトを投げて答えを得る「ワンショット応答」は、単純な質問には十分です。しかし「複数のWeb検索結果を突き合わせて結論を出す」「ファイルを調べてバグを特定し修正する」といった多段階タスクになると、ワンショットでは破綻します。理由は明確です。
- 情報が事前に揃っていない:途中で得た観察結果に応じて次の行動を変える必要がある
- 推論の連鎖が長い:一気に出力すると途中の誤りが伝播し、最終回答まで汚染される
- 外部世界との相互作用が必要:検索・計算・API呼び出しの結果をフィードバックしないと前に進めない
そこで登場するのが「思考ループ(reasoning loop)」です。モデルに考える→行動する→結果を観察する→また考えるという反復を許すことで、タスクを動的に分解しながら解いていく。Chain-of-Thought(Wei et al., 2022)が「考える過程を出力させる」ことの有効性を示して以降、この発想を「行動」や「振り返り」と組み合わせる研究が一気に進みました。以下、代表的な4パターンを順に見ていきます。
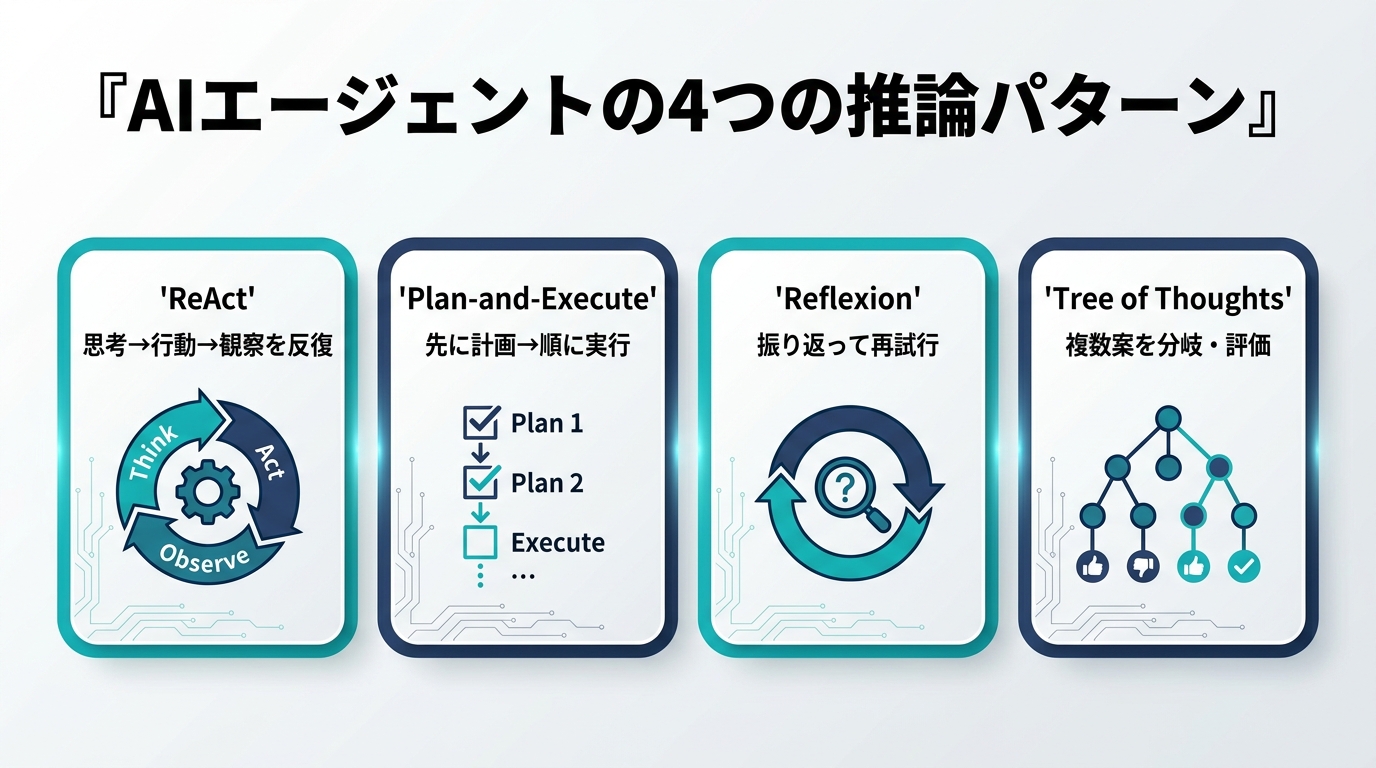
ReAct:Reasoning + Acting(思考と行動の交互反復)
ReActは、Yao et al. が2022年10月にarXivで発表したパターンです(”ReAct: Synergizing Reasoning and Acting in Language Models”)。その名の通り Reasoning(推論) と Acting(行動) を交互に行います。エージェントは1ステップごとに次の3要素を生成します。
- Thought(思考):「次に何を調べるべきか」を言語で推論する
- Action(行動):検索・計算・API呼び出しなどのツールを選んで実行する
- Observation(観察):ツールから返ってきた結果。これを次のThoughtの入力にする
論文の主張は「推論だけ(Chain-of-Thought)では事実に基づかない幻覚(ハルシネーション)に陥りやすく、行動だけでは推論の柔軟性を欠く。両者を組み合わせると、外部知識で推論を裏付けながら、推論で行動計画を立てられる」というものです。HotpotQA(マルチホップQA)やALFWorld(テキストゲーム)でCoT単体や行動単体を上回る結果を示しました。
実装は驚くほどシンプルです。Thought/Action/Observationを1ターンとし、最終解(Finish)が出るまでループを回すだけ。最小実装はこうなります。
def react_loop(question, tools, llm, max_steps=8):
scratchpad = "" # Thought/Action/Observation の履歴
for step in range(max_steps):
prompt = build_prompt(question, scratchpad)
out = llm(prompt, stop=["nObservation:"])
scratchpad += out
if "Finish[" in out:
# Finish[答え] を抽出して返す
return parse_finish(out)
action, arg = parse_action(out) # 例: Search["..."]
observation = tools[action](arg)
scratchpad += f"nObservation: {observation}n"
return "最大ステップ数に到達。途中までの推論: " + scratchpadReActの強みは「汎用性」と「デバッグのしやすさ」です。Thoughtが言語で残るので、エージェントが「なぜその行動を選んだか」を後から追える。一方の弱みはトークン消費とレイテンシ。1ステップごとにLLMを呼ぶため、ステップ数が増えるほどコストが積み上がります。観察結果(Observation)が長文だとコンテキストを圧迫するため、後述の通り要約や圧縮の工夫が要ります。
Plan-and-Execute:先に計画、順に実行
ReActが「1ステップずつその場で考える」のに対し、Plan-and-Execute(計画してから実行)は「最初にタスク全体の計画を立て、その後はステップを順に実行する」という二段構えです。発想のルーツの1つは Wang et al. の “Plan-and-Solve Prompting”(arXiv 2023年5月)で、「まず計画を立てよ、次に各ステップを実行せよ」とモデルに促すだけでゼロショットCoTの精度が上がることを示しました。実装パターンとしての「Plan-and-Execute」はLangChainやBabyAGI系のエージェント実装で広く普及し、Plannerが立てた計画をExecutorが1つずつ消化する構成を指すことが多くなっています。
典型的な流れは次の通りです。
- Planner:タスクをサブステップのリストに分解する(例:「①競合A社の価格を調べる ②B社を調べる ③表にまとめる」)
- Executor:各サブステップを順に実行する。ここで個々のステップにReActループを使うこともある
- 結果の集約:全ステップの出力を統合して最終回答を作る
- (任意)再計画:実行中に前提が崩れたらPlannerに戻り、残りの計画を更新する
このパターンの利点はトークン効率と一貫性です。計画を最初に固めるため、各ステップの実行時に「全体で何をやっているか」を毎回長文で推論し直す必要が減ります。複雑なタスクでも全体像がブレにくい。一方の弱みは柔軟性。最初の計画が間違っていたり、途中で想定外の観察が出たりすると、硬直した計画のまま突き進んでしまうリスクがあります。そのため「再計画(re-planning)」のフックを必ず入れておくのが実務上の定石です。なお、長い計画やステップ間の文脈を引き回すと履歴が膨らむため、コンテキストエンジニアリングによる管理・圧縮と組み合わせると安定します。
Reflexion:自己批判と振り返りで再試行する
Reflexionは Shinn et al. が2023年3月にarXivで発表したパターンです(”Reflexion: Language Agents with Verbal Reinforcement Learning”)。ReActやPlan-and-Executeが「1回のタスク試行の中での反復」であるのに対し、Reflexionは試行をまたいだ学習を扱います。
核となるアイデアは「言語による強化学習(verbal reinforcement learning)」です。エージェントがタスクに失敗したら、その失敗を言語で振り返り(self-reflection)、「次はこう変えるべき」という教訓を生成してメモリに保存する。次の試行ではその教訓を入力に加えて再挑戦する——重みの更新を一切行わず、言語的なフィードバックだけで自己改善するのが特徴です。論文ではコーディングベンチHumanEvalで、当時の素のGPT-4を上回る成績を報告しています。
Reflexionの基本構成は3つのコンポーネントに分かれます。
- Actor:実際にタスクを試行する(ReActなどをベースに使える)
- Evaluator:試行結果が成功か失敗かを評価する(テスト実行・スコア・ヒューリスティックなど)
- Self-Reflection:失敗の原因を言語化し、改善策をメモリに蓄積する
実務での効きどころは「成否を機械的に判定できるタスク」です。コード生成(テストが通るか)、SQL生成(結果が正しいか)など、明確な評価シグナルがある領域で威力を発揮します。逆に評価が曖昧なタスクでは、誤った振り返りがメモリに溜まって悪化することもあるため、Evaluatorの設計が成否を分けます。この評価器の作り込みはLLM-as-a-Judgeを含む評価設計と密接に関わります。
Tree of Thoughts:複数案を分岐させて探索する
ここまでの3パターンは基本的に「1本の推論パス」を進めます。これに対し Tree of Thoughts(ToT)は Yao et al. が2023年5月にarXivで発表したパターンで(”Tree of Thoughts: Deliberate Problem Solving with Large Language Models”)、複数の思考案を木構造で分岐・評価・探索します。
仕組みはこうです。各ステップで「次の一手(thought)」を1つではなく複数生成し、それぞれを評価関数でスコアリング。有望なノードを選んで深掘りし、行き詰まったらバックトラックして別の枝に戻る。幅優先(BFS)や深さ優先(DFS)といった探索アルゴリズムを思考プロセスに持ち込むイメージです。論文では「24点ゲーム(Game of 24)」で、Chain-of-Thoughtが成功率4%だったのに対しToTが74%に達したと報告されており、探索が効くタスクでの伸びが顕著です。
ToTの利点は「試行錯誤が前提の問題」に強いこと。パズル、計画立案、数学的探索など、一本道では正解にたどり着きにくいタスクに向きます。一方で代償は大きく、複数案の生成と評価を繰り返すためLLM呼び出し回数が爆発的に増える。コストとレイテンシは他パターンの数倍〜十数倍になることも珍しくありません。「精度のためにコストをいくら払えるか」を見極めて採用する、ハイコスト・ハイリターンな選択肢です。
4パターンの使い分け:タスクの性質・コスト・レイテンシで選ぶ
「どれが一番優れているか」という問いは成立しません。タスクの性質で最適解が変わるからです。2026年6月時点で実務的に整理すると、おおよそ次のように判断できます。
- ReAct:ツールを使いながら未知の情報を集めて答える汎用タスク(リサーチ、Q&A、軽いエージェント全般)。まず最初に試すべき基本形
- Plan-and-Execute:ステップ数が多く全体像が事前に見える定型的な多段階タスク(データ収集→整形→出力など)。トークン効率と一貫性を重視する場合
- Reflexion:成否を機械的に評価でき、再試行で改善する余地があるタスク(コード生成、SQL、自動テスト駆動の処理)
- Tree of Thoughts:一本道では解けず探索が必要で、かつコストを許容できる高難度タスク(パズル、複雑な計画、数学的推論)
重要なのは、これらは排他ではなく組み合わせられること。たとえば「Plan-and-ExecuteのExecutor内部で各ステップをReActで回し、ステップ失敗時にReflexionで振り返る」といったハイブリッド構成が実務では普通です。Anthropicの「Building Effective Agents」も、まず単純な構成から始め、必要に応じてのみ複雑さを足すことを推奨しています。最初からToTのような重い探索を選ばない——これが事故を減らす第一歩です。
実装の勘所:ループの停止条件と無限ループ防止
どのパターンを採っても、思考ループを安全に回すための実装上の必須項目はほぼ共通です。本番でエージェントを動かす前に、次のガードレールを必ず仕込んでください。
- 最大ステップ数を設ける:
max_steps(例:8〜15)を必ず上限にする。これがないと、答えが出ないタスクでエージェントが延々とループしAPIコストを焼き続ける - 進捗ゼロを検知する:直近N回のActionが同一、または同じObservationが繰り返されたら「行き詰まり」と判定して打ち切る(無限ループの典型パターン)
- 明確な終了条件(Finish)を定義する:エージェントが「もう答えが出た」と宣言する明示的なアクションを持たせ、それ以外はループ継続とする
- タイムアウトを各ツール呼び出しに設定する:外部APIが固まるとループ全体が止まる。1呼び出しごとにタイムアウトを切る
- ツール実行を冪等・安全にする:再試行で副作用が二重に起きないよう、書き込み系ツールは冪等性を担保する
- コンテキスト肥大を管理する:Observationが積み上がるパターン(特にReAct)では、古い観察を要約・圧縮してプロンプトに収める
- 各ステップを構造化ログに残す:Thought/Action/Observationを記録し、後から推論の流れを追えるようにする(デバッグと評価の生命線)
特に「最大ステップ数」「タイムアウト」「冪等性」の3点は、外部世界と相互作用するエージェントの信頼性の土台です。再試行・冪等性・タイムアウトの実装パターンは奥が深いため、AIエージェントのリトライ・冪等性・タイムアウト設計を合わせて参照してください。
評価とまとめ
思考ループのパターンは「導入して終わり」ではありません。本当に効いているかを評価する仕組みを併走させてはじめて改善が回ります。最低限、次の指標を計測してください。
- タスク成功率:最終回答がタスク要件を満たした割合
- 平均ステップ数 / トークン消費:1タスクあたりのコスト。パターン変更の効果はここに表れる
- レイテンシ:ユーザー体験に直結。ToTのような重いパターンは特に監視
- 無限ループ / 最大ステップ到達率:高いほどループ設計に問題がある
本記事を振り返ると、4つのパターンはすべて「1つのエージェントが考えて・行動して・振り返る」という同じ問いへの異なる回答でした。ReActは思考と行動の交互反復で汎用性を、Plan-and-Executeは事前計画で効率と一貫性を、Reflexionは振り返りで自己改善を、Tree of Thoughtsは探索で高難度問題を攻略します。まずReActで基本形を作り、タスクの性質に応じて他パターンを足していく。そして停止条件・タイムアウト・評価という土台を必ず先に固める——これが、破綻しないエージェント設計の現実的な道筋です。
この記事を読んで導入イメージが固まってきた方へ
UravationではAIエージェント導入の研修・コンサルを行っています。
参考・出典
- Shunyu Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models”, arXiv, 2022年10月
- Noah Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning”, arXiv, 2023年3月
- Shunyu Yao et al., “Tree of Thoughts: Deliberate Problem Solving with Large Language Models”, arXiv, 2023年5月
- Lei Wang et al., “Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models”, arXiv, 2023年5月
- Jason Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models”, arXiv, 2022年
- Anthropic, “Building Effective Agents”


