
「ローカルでは完璧に動いていたAIエージェントが、本番に出した途端に落ちる」。これは多くの開発チームが通る道です。原因の大半は、エージェントのロジックそのものではなく、外部依存(LLM API・ツール・データソース)の不安定さに対する設計が甘いことにあります。LLMはレート制限・過負荷・タイムアウトを日常的に返し、ツール呼び出しは部分的に失敗し、同じ入力でも出力がぶれます。この記事では、監視やSLAの話ではなく、コードレベルで「落ちにくいエージェント」を作るための実装パターンに絞って解説します。エラー分類・リトライ・冪等性・タイムアウト・フォールバック・エスカレーションまで、2026年6月時点で実務に使える設計を、Pythonの実装例とともに整理しました。
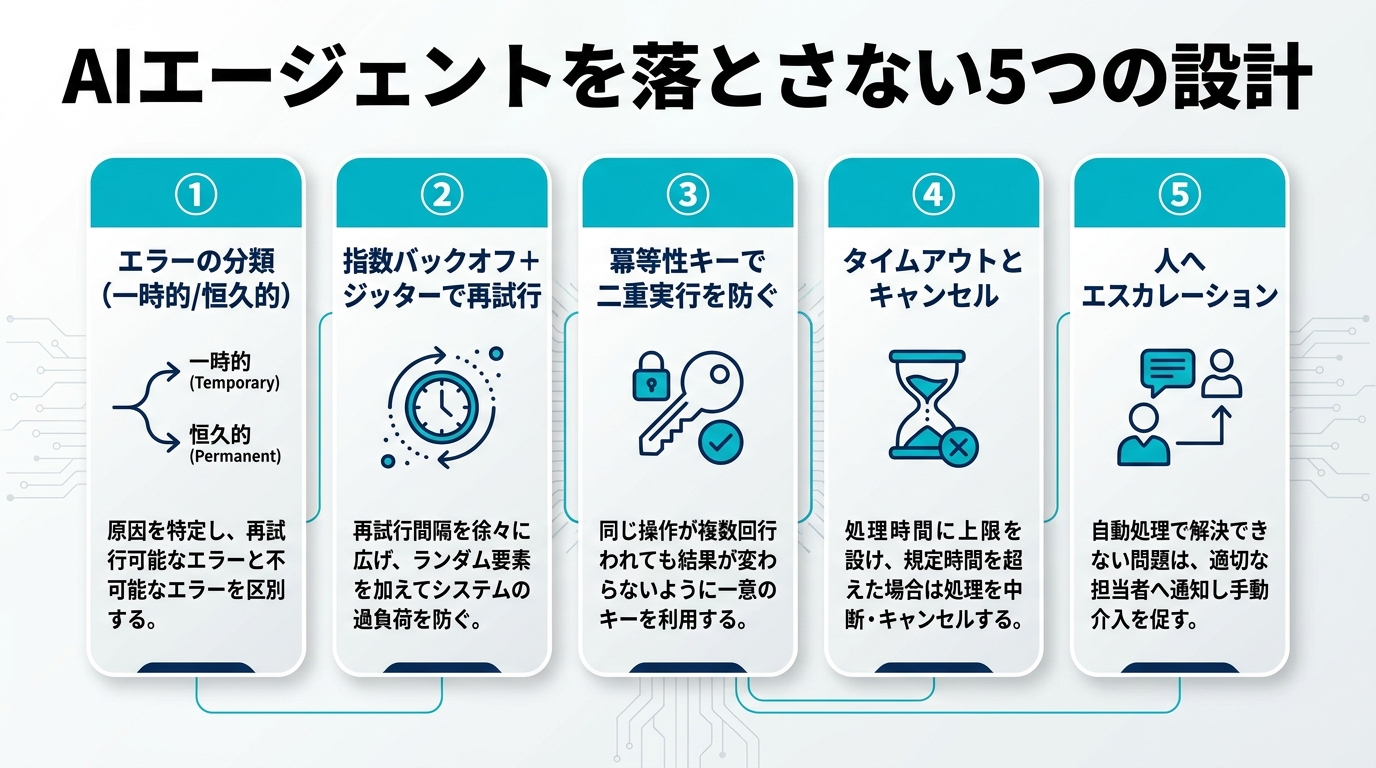
なぜAIエージェントは本番で「だけ」落ちるのか
従来のWebアプリと違い、AIエージェントは1リクエストの内部でLLM呼び出しとツール呼び出しを何度も繰り返す長時間処理になりがちです。1回のエージェント実行で10回以上のAPI呼び出しが走ることも珍しくありません。各呼び出しの失敗率がわずか1%でも、10回連なれば「1回も失敗しない確率」は約90%まで下がります。つまり、個々のAPIが十分に安定していても、素朴に直列でつなぐだけで全体の成功率は崩れるのです。
AIエージェント特有の失敗要因は、おおむね次の5つに整理できます。
- レート制限:LLM APIはリクエスト数・トークン数の両方に上限を持ちます。Anthropic APIは上限超過時に「429
rate_limit_error」を返し、OpenAI APIも429系のレート制限エラーを返します(出典は記事末)。エージェントがバーストすると即座に当たります。 - 過負荷(一時的サーバー側障害):Anthropic APIは全ユーザー横断で高トラフィックのとき「529
overloaded_error」、内部エラーで「500api_error」を返します。これは自分のコードが正しくても発生します。 - タイムアウト:長文生成やツール実行が長引くと処理が完了しません。Anthropic APIは処理中のタイムアウトに「504
timeout_error」を定義しており、長時間リクエストにはストリーミングやバッチの利用を推奨しています。 - 部分失敗:複数ツール・複数モデルを呼ぶエージェントでは、一部だけ失敗するのが普通です。「全部成功か全部失敗か」の二択で設計すると、現実に合いません。
- 非決定性:同じプロンプトでも出力が変わります。JSON形式を期待したのにテキストが返る、存在しないツール名を呼ぶ、といった「形式エラー」もLLM特有です。
これらは「いつか起きる例外」ではなく「定常的に起きる通常イベント」です。だからこそ、例外処理を後付けするのではなく、最初から設計に織り込む必要があります。
エラーの分類:リトライ可否で扱いを変える
堅牢化の第一歩は、すべてのエラーを「一時的(transient)」か「恒久的(permanent)」かで分けることです。一時的エラーは時間をおけば解消する可能性があるためリトライ対象、恒久的エラーはリトライしても無駄なので即座に失敗させて上位に通知します。
主要LLM APIのHTTPステータスコードを基準に分類すると、次のようになります(Anthropic APIのエラーコード定義に基づく。2026年6月時点)。
- リトライすべき(一時的):429(レート制限)、500(内部エラー)、503(利用不可)、529(過負荷)、504(タイムアウト)、およびネットワーク層の接続エラー・読み取りタイムアウト。
- リトライしてはいけない(恒久的):400(リクエスト不正
invalid_request_error)、401(認証エラー)、403(権限エラー)、404(リソースなし)、413(リクエスト過大request_too_large)。これらは入力やキーを直さない限り、何度投げても同じ結果です。
この分類を判定する関数を1つ用意し、リトライ層から呼ぶようにします。リトライ可否の判断ロジックを一箇所に集約することで、誤って恒久的エラーを延々とリトライしてコストとレイテンシを溶かす事故を防げます。
from dataclasses import dataclass
# リトライ対象とする一時的エラーのHTTPコード(2026年6月時点の主要LLM API基準)
TRANSIENT_STATUS = {429, 500, 502, 503, 504, 529}
# 即座に失敗させる恒久的エラー
PERMANENT_STATUS = {400, 401, 403, 404, 413, 422}
@dataclass
class APIError(Exception):
status_code: int | None
message: str
request_id: str | None = None # 障害調査に必須(Anthropic は request-id ヘッダを返す)
def is_retryable(err: Exception) -> bool:
"""このエラーをリトライしてよいかを一元判定する。"""
if isinstance(err, APIError):
if err.status_code in PERMANENT_STATUS:
return False
if err.status_code in TRANSIENT_STATUS:
return True
# 不明なステータスは安全側に倒し、リトライしない
return False
# ネットワーク層の例外(接続失敗・読み取りタイムアウト)は一時的とみなす
return isinstance(err, (ConnectionError, TimeoutError))ポイントは、不明なエラーをデフォルトでリトライしないことです。判断がつかないものを「とりあえずリトライ」にすると、恒久的エラーを延々と叩いてしまうリスクがあります。明示的に一時的だと分かったものだけをリトライ対象にする「ホワイトリスト方式」が安全です。なお、ストリーミング応答では200を返した後にエラーが発生し得る点にも注意が必要です(Anthropic APIのエラーガイドにも明記)。ストリーム途中のエラーは、HTTPステータスとは別経路で受け取る必要があります。
リトライ戦略:指数バックオフ+ジッター+サーキットブレーカー
一時的エラーに対しては「待ってから再実行」しますが、待ち方が雑だと逆効果です。固定間隔で全クライアントが一斉に再試行すると、復旧しかけたサーバーを再び落とす「サンダリングハード(thundering herd)」を引き起こします。これを避ける標準が指数バックオフ+ジッターです。OpenAIのレート制限ドキュメントでも、レート制限エラー時に短いスリープを挟んで再試行し、さらに「ランダムなジッターを加えることで、すべての再試行が同時に集中するのを防ぐ」よう明確に推奨しています。AWSのbuilders’ libraryも、タイムアウト・リトライ・ジッター付きバックオフを信頼性設計の基本として解説しています(出典は記事末)。
リトライ層を実装する手順は次のとおりです。
- 最大試行回数を決める(例:3回)。無限リトライは絶対に避け、上限に達したら失敗を上位へ返す。
- 基本待機時間を指数で増やす。
base * 2 ** attemptで 1秒 → 2秒 → 4秒と広げる。 - ジッターを加える。待機時間にランダムな揺らぎ(例:±50%)を入れ、再試行のタイミングを分散させる。
- 上限キャップを設ける。待機が長くなりすぎないよう最大値(例:30秒)で頭打ちにする。
- Retry-After / レート制限ヘッダを尊重する。サーバーが残量・リセット時刻(OpenAIの
x-ratelimit-remaining-*/x-ratelimit-reset-*等)を返す場合は、計算値より優先して従う。 - リトライ可否を判定してから再試行する。前章の
is_retryableを通し、恒久的エラーなら即座に脱出する。
import random
import time
import logging
logger = logging.getLogger("agent.retry")
def call_with_retry(func, *, max_attempts=3, base=1.0, cap=30.0):
"""指数バックオフ+フルジッターでリトライするラッパ。"""
for attempt in range(max_attempts):
try:
return func()
except Exception as err:
# 恒久的エラー、または最終試行なら諦めて上位へ送出
if not is_retryable(err) or attempt == max_attempts - 1:
raise
# 指数バックオフ。base * 2^attempt を上限 cap でキャップ
backoff = min(cap, base * (2 ** attempt))
# フルジッター:0〜backoff の一様乱数で同時再試行を分散
delay = random.uniform(0, backoff)
rid = getattr(err, "request_id", None)
logger.warning(
"retrying attempt=%d delay=%.2fs request_id=%s err=%s",
attempt + 1, delay, rid, err,
)
time.sleep(delay)ここで使っているのは「フルジッター」(0からbackoffまでの一様乱数)です。AWSの検証では、固定間隔や単純な指数バックオフよりも、フルジッターのほうが競合を大きく減らせることが示されています。実装はわずかですが効果は大きいパターンです。
サーキットブレーカーで「壊れた先」を叩き続けない
リトライは「一時的な失敗」には有効ですが、外部サービスが本格的にダウンしている間はリトライ自体が有害です。落ちている相手に全リクエストが3回ずつ再試行すれば、待ち時間でスレッドが枯渇し、自分のサービスまで連鎖的に落ちます。これを防ぐのがサーキットブレーカーです。Microsoftのアーキテクチャパターン集でも、失敗が続く下流への呼び出しを一定期間遮断する設計として標準化されています(出典は記事末)。
サーキットブレーカーは3つの状態を持ちます。
- Closed(閉):通常運転。呼び出しを通すが、連続失敗回数をカウントする。
- Open(開):失敗がしきい値を超えたら回路を開く。一定時間、呼び出しを即座に拒否(fail fast)し、下流を休ませる。
- Half-Open(半開):クールダウン後、試験的に1件だけ通す。成功すればClosedへ復帰、失敗すれば再びOpenへ。
import time
class CircuitBreaker:
def __init__(self, fail_threshold=5, reset_timeout=30.0):
self.fail_threshold = fail_threshold
self.reset_timeout = reset_timeout
self.failures = 0
self.opened_at = None # Open になった時刻
def allow(self) -> bool:
if self.opened_at is None:
return True # Closed
# クールダウン経過後は Half-Open として1件だけ試させる
if time.monotonic() - self.opened_at >= self.reset_timeout:
return True
return False # Open:即拒否
def record_success(self):
self.failures = 0
self.opened_at = None
def record_failure(self):
self.failures += 1
if self.failures >= self.fail_threshold:
self.opened_at = time.monotonic()リトライとサーキットブレーカーは併用します。個々の呼び出しはリトライで救い、繰り返しの全体的な失敗はブレーカーで遮断する、という二層構えが本番では効きます。
冪等性の設計:2回実行しても安全にする
リトライを入れると必ず付いて回るのが「二重実行」の問題です。1回目のリクエストが実はサーバー側で成功していたのに、レスポンスがネットワークで失われ、クライアントは失敗とみなして再送する——このとき、エージェントが「メール送信」「課金」「DB書き込み」「外部発注」のような副作用を持つツールを叩いていたら、同じ操作が2回実行されて取り返しがつきません。
解決策は冪等性(idempotency)です。「同じ操作を何回実行しても、結果が1回実行したときと同じになる」よう設計します。中心になるのが冪等性キー(idempotency key)です。Google Cloudのリトライ戦略ガイドでも、リトライ安全性を担保する手段として冪等性が重視されています(出典は記事末)。
冪等性キーを使った副作用ツールの実装手順は次のとおりです。
- 操作ごとに一意なキーを生成する。エージェントの実行ID+ツール名+引数のハッシュなど、「同じ意図の操作なら同じキー、違う操作なら違うキー」になるよう作る。
- 実行前にキーをストアで確認する。すでに完了済みなら、副作用を再実行せず保存済みの結果を返す。
- 未処理なら実行し、結果をキーに紐づけて保存する。保存は副作用と同一トランザクションにできれば理想(atコミット境界を揃える)。
- 進行中(in-flight)状態も記録する。同時に同じキーが来たら待たせるかエラーにし、並行二重実行を防ぐ。
- TTLを設定する。キーは永久に保持せず、安全なリトライ猶予(例:24時間)で失効させ、ストアの肥大を防ぐ。
import hashlib
import json
def idempotency_key(run_id: str, tool: str, args: dict) -> str:
"""同じ意図の操作には同じキー、違う操作には違うキーを割り当てる。"""
payload = json.dumps(args, sort_keys=True, ensure_ascii=False)
raw = f"{run_id}:{tool}:{payload}"
return hashlib.sha256(raw.encode("utf-8")).hexdigest()
def execute_side_effect(store, run_id, tool_name, args, do_action):
"""副作用ツールを冪等に実行する。store は get/set 可能なKVを想定。"""
key = idempotency_key(run_id, tool_name, args)
cached = store.get(key)
if cached is not None:
# すでに実行済み:副作用を再実行せず結果だけ返す
return cached["result"]
# 未処理:実行して結果を保存(TTL付き)
result = do_action(args)
store.set(key, {"result": result, "status": "done"}, ttl=86_400)
return result注意点として、「読み取り系ツール(検索・取得)は本来冪等」だが「書き込み系ツール(送信・登録・課金)は冪等性キーが必須」と整理しておくと、どのツールに冪等化のコストをかけるべきか判断しやすくなります。外部API側がidempotency keyに対応している場合(多くの決済・通信APIが対応)は、自前で作らずそのヘッダに乗せるのが最も堅実です。
タイムアウトとキャンセル:止め時を必ず決める
タイムアウトを設定しない呼び出しは、いつか必ずシステムを固めます。下流が無応答のまま接続を握り続けると、スレッドや接続プールが枯渇し、無関係なリクエストまで詰まります。すべての外部呼び出しに上限時間を設定するのが鉄則です。
AIエージェントではタイムアウトを階層で考えます。
- 呼び出し単位のタイムアウト:1回のLLM/ツール呼び出しの上限(例:60秒)。長文生成では、Anthropic APIが推奨するようにストリーミングを使い、最初のトークンまでの時間とトークン間の間隔で監視する。
- ステップ単位のタイムアウト:リトライを含めた1ステップ全体の上限。リトライのバックオフ待ちで膨らみすぎないよう「予算(budget)」を持たせる。
- エージェント全体のタイムアウト:1実行の総時間(例:10分)。これを超えたら安全に中断し、途中結果+エスカレーションを返す。Anthropicも10分超の長時間処理にはバッチAPIやポーリングを推奨している。
長時間ツールには「タイムアウトしたら中断する」だけでなく「中断できるように作る」ことが重要です。Pythonのasyncioならtimeoutコンテキストで上位からキャンセルを伝播できます。ストリーミング中のLLM応答も、途中で打ち切れる構造にしておきます。
import asyncio
async def call_tool_with_budget(tool_coro, *, per_call=60.0, total_budget=180.0):
"""呼び出し単位と総予算の二段でタイムアウトをかける。"""
deadline = asyncio.get_event_loop().time() + total_budget
try:
# per_call と「残り予算」の小さい方を実効タイムアウトにする
remaining = deadline - asyncio.get_event_loop().time()
timeout = min(per_call, max(0.0, remaining))
async with asyncio.timeout(timeout):
return await tool_coro
except asyncio.TimeoutError:
# タイムアウトは一時的エラー扱い:上位のリトライ層に判断を委ねる
raise APIError(status_code=504, message="tool call timed out")ストリーミング中断を扱う際は、「すでに生成された部分トークンをどうするか」を決めておきます。途中までの出力を破棄するのか、部分結果として活用するのかで、ユーザー体験が変わります。
部分失敗とフォールバック:degradeして生き延びる
複数のモデルやツールを使うエージェントでは、「全部が完璧に動く」ことを前提にしてはいけません。一部が落ちても機能を縮退(degrade)させて動き続けるのが本番品質です。代表的なフォールバック設計は次の3つです。
- モデルのフォールバック:主モデルが529や429で応答しないとき、別プロバイダや軽量モデルに切り替える。OpenRouterのようなゲートウェイ層を挟むと、この切り替えを設定で扱いやすくなります。
- ツールのフォールバック:外部検索APIが落ちたら、キャッシュ済みデータや簡易な内蔵関数で代替する。精度は落ちても「何も返せない」よりは良い。
- 機能の縮退:高度な機能(リアルタイム連携など)が使えないとき、その機能を無効化した上で基本応答だけ返し、「一部機能が一時的に利用できない」と明示する。
フォールバックを設計するときの原則は「静かに精度を落とさない」ことです。代替手段に切り替えたら、必ずその事実をログとレスポンスのメタデータに記録します。利用者やオペレーターが「いま縮退運転中である」と分かるようにしておかないと、品質劣化に誰も気づかないまま放置されます。
def generate_with_fallback(prompt, primary, secondary):
"""主モデル→代替モデルへフォールバックし、使ったモデルを記録する。"""
try:
text = call_with_retry(lambda: primary(prompt))
return {"text": text, "model": "primary", "degraded": False}
except Exception as err:
if not is_retryable(err):
raise # 入力不正など、代替に投げても無駄なものは即失敗
logger.warning("primary failed, falling back. err=%s", err)
text = call_with_retry(lambda: secondary(prompt))
# degraded=True を必ず明示し、下流が縮退を検知できるようにする
return {"text": text, "model": "secondary", "degraded": True}ヒューマン・イン・ザ・ループへのエスカレーション
すべてを自動で救おうとするのは危険です。リトライもフォールバックも尽きた、あるいは機械が勝手に判断すると損害が大きい操作に当たったときは、人間に判断を委ねる「ヒューマン・イン・ザ・ループ(HITL)」へ確実にエスカレーションします。これも堅牢性設計の一部です。エスカレーションを設計する観点は次のとおりです。
- エスカレーション条件を明文化する:リトライ枯渇・サーキットブレーカーOpen継続・低い確信度・高リスク操作(高額課金・不可逆な削除など)を引き金にする。
- 状態を保存して中断する:エージェントの実行状態(途中までの結果・残タスク)を保存し、人間の判断後に再開できるようにする。冪等性キーがここでも効く。
- 人間に十分な文脈を渡す:何を試して何が失敗したか、
request_idを含む失敗ログを添えて通知する。判断材料がなければ人間も詰まる。
権限設計と組み合わせると、より安全になります。「この操作はエージェント単独で実行可、あの操作は人間承認が必須」といった境界をあらかじめ引いておくと、エスカレーションの判断が自動化できます。権限・承認フローの設計は、AIエージェントのガバナンスと権限設計の記事も併せて参照してください。
可観測性との接続:失敗を「記録」し「再現」できるようにする
堅牢化の最後のピースは可観測性です。失敗を握りつぶさず、後から原因を特定して再現できる状態にしておかなければ、リトライやフォールバックがいつ・なぜ発動したのか誰も分かりません。最低限、次の情報を構造化ログに残します。
- 失敗のたびに記録すべき項目:ステータスコード、エラータイプ、
request_id(Anthropic APIはrequest-idヘッダを返し、サポート問い合わせ時の追跡に使える)、試行回数、待機時間、使ったモデル/ツール、degradeの有無。 - 相関ID(trace ID)を全呼び出しに伝播する:1回のエージェント実行に紐づくすべてのLLM・ツール呼び出しを横断で追えるようにする。これがないと「どのステップで何回リトライしたか」が再構成できない。
- 入力スナップショットを残す:非決定性で再現が難しいLLMでも、プロンプト・パラメータ・シード(対応モデルなら)を記録しておけば、事後に近い形で再現できる。
リトライ・フォールバック・エスカレーションのイベントは、いずれも「正常系では起きないこと」です。これらをメトリクス化して監視すれば、本番品質の劣化を早期に検知できます。リトライ率の急上昇は下流障害の前兆ですし、degrade率の上昇は特定プロバイダの不調を示します。具体的な計装・トレーシングの実装はOpenTelemetryによるAIエージェントの可観測性設計、本番運用の監視体制全般はAIエージェントのSRE・本番監視を参照してください。リトライ回数とフォールバックはコストにも直結するため、AIエージェントのコスト最適化の観点とも合わせて設計するのが実務的です。
まとめ:本番堅牢化チェックリスト
「本番で落ちないAIエージェント」は、特別な魔法ではなく、地道な実装パターンの積み重ねで作れます。最後に、本番投入前のチェックリストとして整理します。
- エラー分類:すべての失敗を一時的/恒久的に分類し、リトライ可否を一元判定しているか。不明なエラーはデフォルトでリトライしない設計か。
- リトライ:指数バックオフ+ジッター・最大試行回数・上限キャップを実装し、サーバーのRetry-After/レート制限ヘッダを尊重しているか。
- サーキットブレーカー:連続失敗で下流を遮断し、クールダウン後に半開で復旧を試す仕組みがあるか。
- 冪等性:副作用ツール(送信・課金・登録)に冪等性キーを付け、二重実行を防いでいるか。外部APIのidempotency key対応を活用しているか。
- タイムアウト:呼び出し・ステップ・エージェント全体の3階層で上限を設け、中断・キャンセルが伝播するか。長時間処理はストリーミング/バッチを使っているか。
- フォールバック:モデル・ツール・機能の代替経路を用意し、degrade時に必ずその事実を記録しているか。
- エスカレーション:自動で救えない・高リスクな操作を、文脈付きで確実に人間へ渡せるか。状態を保存して再開できるか。
- 可観測性:失敗・リトライ・フォールバック・エスカレーションを構造化ログとメトリクスに残し、
request_idと相関IDで再現・追跡できるか。
これら8項目を満たせば、外部依存が日常的に揺れる環境でも、エージェントは「落ちる」のではなく「縮退して生き延びる」ようになります。完璧な安定性を目指すのではなく、失敗を前提に設計すること——それが本番運用するAIエージェントの第一原則です。
この記事を読んで導入イメージが固まってきた方へ
UravationではAIエージェント導入の研修・コンサルを行っています。
参考・出典
- Anthropic / Claude API — Errors(HTTPエラーコード・429/529/504・request-idヘッダ・長時間リクエスト指針)
- Anthropic / Claude API — Rate limits
- OpenAI API — Rate limits(指数バックオフ+ジッター推奨・x-ratelimitヘッダ)
- Amazon Builders’ Library — Timeouts, retries, and backoff with jitter
- Microsoft — Circuit Breaker pattern
- Microsoft — Retry pattern


