
「RAGを組んでAIエージェントに自社データを参照させたいけど、どのフレームワークから手をつければいいんだろう…?」
AIエージェントを実務に投入しようとすると、必ずこの壁にぶつかります。LLM単体は賢くても、社内マニュアルやドキュメント、データベースの中身は知りません。そこを埋めるのが LlamaIndex(旧 GPT Index)です。ドキュメントを読み込み、インデックス化し、質問に応じて関連箇所だけをLLMに渡す——いわゆるRAG(Retrieval-Augmented Generation)を最短距離で実装できるデータフレームワークです。
この記事では、2026年6月時点の公式ドキュメント(developers.llamaindex.ai)に基づき、LlamaIndexのコア概念から最小RAG実装、データコネクタ、検索の高度化、エージェント化、本番運用までをコピペ可能なコード付きで通しで解説します。パッケージ分割の関係で import パスは頻繁に変わる領域なので、本記事のコードはすべて現行の公式リファレンスで裏取りした構成にしています。
LlamaIndexとは何か — LangChainとの違いとRAGの位置づけ
LlamaIndexは、外部データとLLMをつなぐことに特化したPython(およびTypeScript)製のデータフレームワークです。ひとことで言えば「LLMに知識を持たせるための配管」を担います。ドキュメントの取り込み(Ingestion)、インデックス化(Indexing)、検索(Retrieval)、回答生成(Querying)という一連のRAGパイプラインを、少ないコードで組めるのが最大の特徴です。
よく比較される LangChain との住み分けは、おおまかに次のように整理できます。
| 観点 | LlamaIndex | LangChain |
|---|---|---|
| 主戦場 | データの取り込み・検索(RAG)に最適化 | ツール連携・チェーン構築など汎用オーケストレーション |
| 抽象化の中心 | Index / Retriever / Query Engine | Chain / Runnable / Agent |
| 得意なこと | 大量ドキュメントに対する検索・質問応答 | 複雑なワークフロー・外部ツール呼び出し |
| 学習コスト | RAGなら立ち上がりが速い | 柔軟だが抽象が多く把握に時間がかかる |
両者は排他ではありません。検索基盤はLlamaIndexで作り、それをLangChainのツールとして組み込む、という併用も一般的です。「自社ドキュメントに賢く答えさせたい」が出発点なら、まずLlamaIndexから入るのが近道です。
なお、RAGを使わずファインチューニングで知識を入れる手もありますが、更新頻度の高い社内情報には不向きです。情報が変わるたびに再学習が必要になるため、ドキュメントを差し替えるだけで反映できるRAGのほうが運用が軽い、というのが実務での定番判断になります。
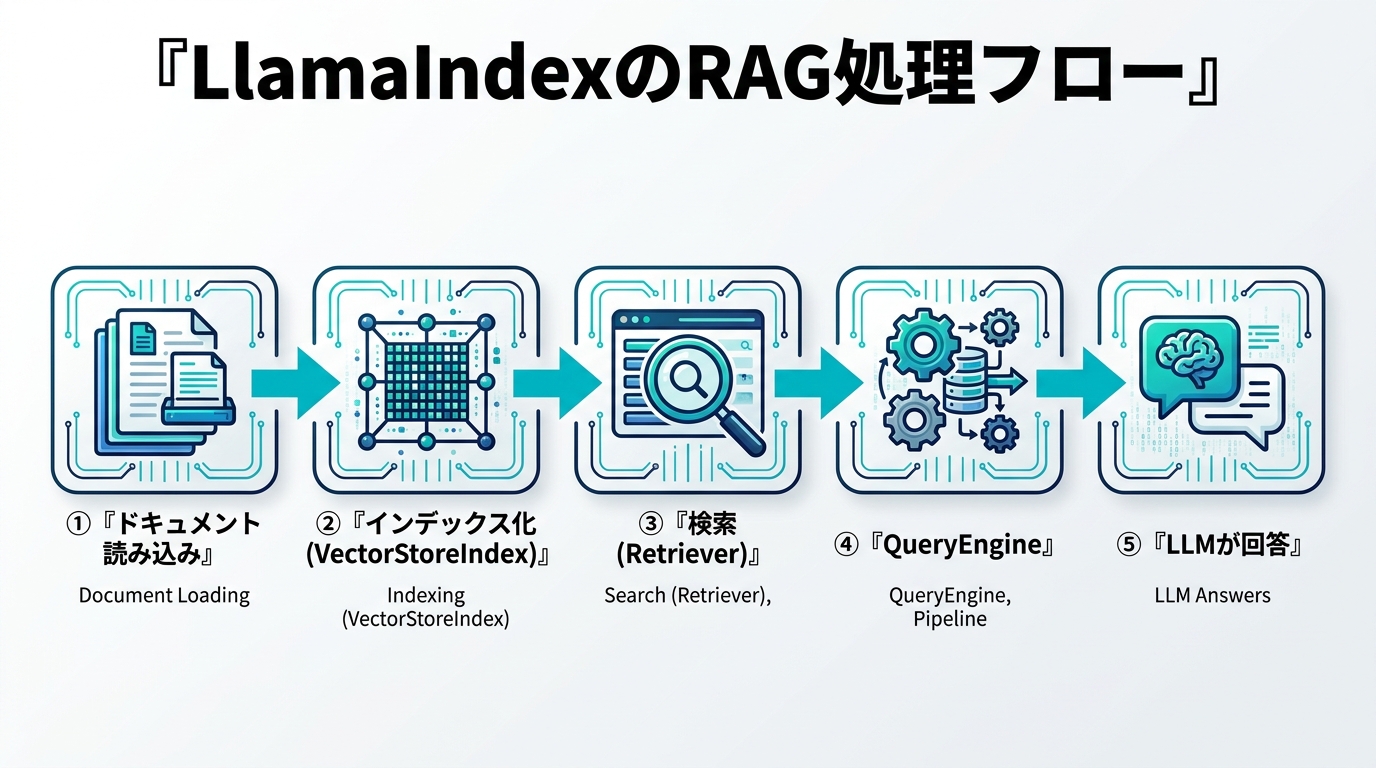
コア概念 — Document / Node / Index / Retriever / Query Engine
LlamaIndexを理解する近道は、データが流れる5つの登場人物を押さえることです。順番に見ていきます。
- Document(ドキュメント):読み込んだ元データ1件を表すコンテナ。PDF1ファイル、Webページ1枚などが1 Documentになります。テキスト本体とメタデータ(出典・更新日など)を持ちます。
- Node(ノード):Documentを検索しやすいサイズに分割したチャンク。実際の検索・埋め込みの単位はこのNodeです。分割を担うのが後述の Node Parser(SentenceSplitter など)です。
- Index(インデックス):Nodeを検索可能な形に整理したもの。最も使われるのがベクトル検索用の
VectorStoreIndexです。 - Retriever(リトリーバー):質問に対して関連Nodeを取り出す検索器。インデックスから
index.as_retriever()で生成します。 - Query Engine(クエリエンジン):Retrieverで取り出したNodeをLLMに渡し、最終回答を生成する高レベルAPI。
index.as_query_engine()で取得します。
データの流れは「Document → (分割)→ Node → (埋め込み・格納)→ Index → (検索)→ Retriever → (生成)→ Query Engine → 回答」という一本道です。この絵が頭に入っていれば、後段のコードはすべてこのどこかを触っているだけだと分かります。
インストールと環境準備
2026年6月時点の公式手順では、まずスターターバンドルを入れるのが最短です。バンドルには llama-index-core に加えて OpenAI用のLLM・埋め込み、ファイルリーダーが含まれます。
# 動作環境: Python 3.9+ / 2026年6月時点の公式手順
# スターターバンドル(core + OpenAI LLM + OpenAI埋め込み + ファイルリーダー)
pip install llama-index
# OpenAI APIキーを環境変数に設定
export OPENAI_API_KEY="sk-..."必要なコンポーネントだけを選びたい場合は、コアと統合パッケージを個別に入れます。統合パッケージは llama-index-{カテゴリ}-{プロバイダ} という命名規則です。
# 動作環境: Python 3.9+
# 必要なものだけを個別インストールする例
pip install llama-index-core
llama-index-llms-openai
llama-index-embeddings-openai
llama-index-readers-fileここで覚えておきたいのが、llama-index(バンドル)と llama-index-core(基盤ライブラリ)の違いです。core は抽象クラスとユーティリティの土台で、LLMや埋め込みモデル、各種データコネクタは別パッケージとして切り出されています。「ModuleNotFoundError: No module named ‘llama_index.readers.web’」のようなエラーは、たいてい統合パッケージの入れ忘れです。import パスとパッケージ名が対応しているので、足りないものを pip install で追加すれば解決します。
最小RAGを動かす — 読み込み・インデックス化・クエリ
まずは公式スターターと同じ「データを読んで質問する」最小構成を作ります。data/ フォルダにテキストやPDFを置いておく前提です。
実装は次の3ステップ(読み込み → インデックス化 → クエリ)で完結します。
-
ドキュメントを読み込む。
SimpleDirectoryReaderでフォルダ内のファイルをまとめてDocumentに変換します。# 動作環境: Python 3.9+, llama-index(バンドル) # 2026年6月時点の公式スターター構成に準拠 from llama_index.core import VectorStoreIndex, SimpleDirectoryReader # data/ 配下のファイルを読み込む documents = SimpleDirectoryReader("data").load_data() -
インデックスを構築する。
VectorStoreIndex.from_documents()がDocumentの分割・埋め込み・格納をまとめて行います。埋め込みモデルはデフォルトでOpenAIが使われます。from llama_index.core import VectorStoreIndex index = VectorStoreIndex.from_documents(documents) -
クエリエンジンで質問する。 インデックスからQuery Engineを作り、自然言語で問い合わせます。内部で関連Nodeを検索し、LLMが回答を生成します。
query_engine = index.as_query_engine() response = query_engine.query("このドキュメントの要点を3つ教えて") print(response)
たったこれだけで、ローカルのドキュメントに対する質問応答が動きます。本番環境で使用する前に、必ずテスト環境でAPIキーと出力内容を確認してください。
毎回インデックスを作り直さない(永続化)
埋め込み計算はAPIコストがかかるため、一度作ったインデックスは保存して再利用します。
from llama_index.core import StorageContext, load_index_from_storage
# 保存
index.storage_context.persist(persist_dir="storage")
# 読み込み(次回以降はこちら)
storage_context = StorageContext.from_defaults(persist_dir="storage")
index = load_index_from_storage(storage_context)LLM・埋め込みモデルをまとめて指定する(Settings)
使うモデルやチャンクサイズはグローバルな Settings で一括設定できます。コンポーネントごとに渡す手間が省けます。
# 動作環境: Python 3.9+
# 必要パッケージ: llama-index-llms-openai, llama-index-embeddings-openai
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
from llama_index.embeddings.openai import OpenAIEmbedding
Settings.llm = OpenAI(model="gpt-4o-mini", temperature=0.1)
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small")
Settings.chunk_size = 512
Settings.chunk_overlap = 20データコネクタ — LlamaHubで多様なソースを取り込む
RAGの価値は、つなげるデータソースの幅で決まります。ローカルファイルだけでなく、Webページ、データベース、Notion、Slack、Google Driveなど、多数のコネクタが LlamaHub(公式の統合カタログ)で公開されています。コネクタは統合パッケージとして配布され、import パスはパッケージ名と対応します。
例として、Webページを読み込む SimpleWebPageReader を使ってみます。専用パッケージのインストールが必要です。
# 動作環境: Python 3.9+
# 必要パッケージ: llama-index-readers-web, html2text
# pip install llama-index-readers-web html2text
from llama_index.readers.web import SimpleWebPageReader
from llama_index.core import VectorStoreIndex
# HTMLをテキストに変換して読み込む
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://example.com"]
)
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
print(query_engine.query("このページの主題は?"))ポイントは、どのコネクタでも出力は同じ Document のリストになることです。つまりソースが変わっても、後段のインデックス化・検索・生成のコードは一切変えずに使い回せます。WebもDBもファイルも「Documentに揃える」という入口だけ差し替えればよい、というのがLlamaIndexの設計思想です。
各コネクタの正確なパッケージ名と引数はLlamaHubで公開されているため、新しいソースをつなぐ際はまずカタログでパッケージ名を確認するのが確実です。
検索の高度化 — チャンク調整・リランク・top_kチューニング
最小構成のRAGは動きますが、回答精度を上げるには「何を、どれだけ、どの順でLLMに渡すか」を作り込む必要があります。ここがRAGの腕の見せどころです。
チャンク分割を制御する(Node Parser)
分割が大きすぎるとノイズが増え、小さすぎると文脈が切れます。SentenceSplitter は文の境界を尊重しつつ分割するので、文の途中で切れる事故を減らせます。
# 動作環境: Python 3.9+, llama-index-core
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
nodes = splitter.get_nodes_from_documents(documents)
# 分割済みNodeからインデックスを作る
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex(nodes)取得件数を絞る・並べ替える(Retriever と リランク)
検索段階では多めに取り(similarity_top_k)、リランクで本当に関連する数件に絞り込む、という二段構えが定石です。リランクには SentenceTransformerRerank を使い、Query Engine の node_postprocessors に渡します。
# 動作環境: Python 3.9+
# 必要パッケージ: llama-index-core, sentence-transformers, torch
from llama_index.core.postprocessor import SentenceTransformerRerank
# 上位10件を取得 → クロスエンコーダで上位3件に絞り込む
rerank = SentenceTransformerRerank(
model="cross-encoder/ms-marco-MiniLM-L-2-v2",
top_n=3,
)
query_engine = index.as_query_engine(
similarity_top_k=10,
node_postprocessors=[rerank],
)
print(query_engine.query("契約解除の条件は?"))Retriever を低レベルで直接使い、検索結果だけを確認したい場合は次のようにします。デバッグ時に「どのNodeが引っかかっているか」を見るのに便利です。
retriever = index.as_retriever(similarity_top_k=5)
nodes = retriever.retrieve("契約解除の条件は?")
for n in nodes:
print(round(n.score, 3), n.node.get_content()[:80])Retriever と LLM を明示的に組み合わせて Query Engine を作りたい場合は RetrieverQueryEngine を使います。検索ロジックと生成ロジックを分離でき、カスタマイズの自由度が上がります。
from llama_index.core.query_engine import RetrieverQueryEngine
retriever = index.as_retriever(similarity_top_k=10)
query_engine = RetrieverQueryEngine.from_args(
retriever,
node_postprocessors=[rerank],
)エージェント化 — Query EngineをツールにしてAIエージェントに知識を持たせる
ここまでで「検索して答える」仕組みはできました。次は、その検索をエージェントの道具(ツール)の1つとして持たせ、状況に応じて自律的に使い分けさせます。これがLlamaIndexで「AIエージェントに知識を持たせる」核心です。
2026年6月時点の公式では、llama_index.core.agent.workflow の FunctionAgent が中心です。ツールは「説明文(docstring)と型ヒント付きの普通のPython関数」として渡せます。エージェントは関数名・引数・docstringを見て、どのツールを使うかを判断します。
# 動作環境: Python 3.9+
# 必要パッケージ: llama-index-core, llama-index-llms-openai
import asyncio
from llama_index.core.agent.workflow import FunctionAgent
from llama_index.llms.openai import OpenAI
# 普通の関数がそのままツールになる(docstringが重要)
def multiply(a: float, b: float) -> float:
"""2つの数値を掛け算して積を返す"""
return a * b
agent = FunctionAgent(
tools=[multiply],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="あなたは計算を手伝うアシスタントです。",
)
async def main():
response = await agent.run(user_msg="23かける17は?")
print(response)
asyncio.run(main())そして、先ほど作ったRAGの Query Engine を QueryEngineTool でラップすれば、エージェントは「社内ドキュメントを検索するツール」を手に入れます。name と description がエージェントの判断材料になるので、ここを丁寧に書くのが精度のコツです。
# 動作環境: Python 3.9+
# 必要パッケージ: llama-index-core, llama-index-llms-openai
from llama_index.core.tools import QueryEngineTool
from llama_index.core.agent.workflow import FunctionAgent
from llama_index.llms.openai import OpenAI
# RAGの query_engine をツール化
doc_tool = QueryEngineTool.from_defaults(
query_engine=query_engine,
name="company_docs",
description=(
"自社の社内規程・マニュアルに関する質問に答えるツール。"
"具体的な質問文を入力として渡すこと。"
),
)
agent = FunctionAgent(
tools=[doc_tool],
llm=OpenAI(model="gpt-4o-mini"),
system_prompt="ユーザーの質問に、必要なら社内ドキュメントを検索して答えてください。",
)
async def main():
response = await agent.run(user_msg="経費精算の締め日はいつ?")
print(response)
asyncio.run(main())複数の Query Engine(例:規程用・FAQ用・契約用)をそれぞれツール化して同じエージェントに渡せば、エージェントが質問内容に応じて適切な検索先を選ぶようになります。FunctionAgent のほかに、推論の途中経過を明示する ReActAgent なども選べます。
本番化 — 評価・更新・コストの3点を設計する
PoCが動いたあと、本番運用で必ず詰まるのが「精度を測れない」「データ更新が回らない」「コストが読めない」の3点です。最後に、それぞれの勘所と対策を整理します。
評価 — ハルシネーションを定量化する
RAGの怖さは、検索が外れてもそれっぽい嘘を自信満々に返すことです。LlamaIndexの評価モジュールには、回答が検索コンテキストに忠実か(=ハルシネーションしていないか)を判定する FaithfulnessEvaluator があります。リリース前に代表的な質問セットで自動評価を回す仕組みを入れておきましょう。
# 動作環境: Python 3.9+, llama-index-core
from llama_index.core.evaluation import FaithfulnessEvaluator
from llama_index.llms.openai import OpenAI
evaluator = FaithfulnessEvaluator(llm=OpenAI(model="gpt-4o"))
response = query_engine.query("有給休暇は何日付与される?")
result = evaluator.evaluate_response(response=response)
print("忠実性:", result.passing) # True / False更新 — インデックスの差分反映
ドキュメントは日々増減します。全件を毎回作り直すとコストも時間も無駄なので、変更分だけを反映する運用にします。永続化したインデックスをロードし、追加分のNodeだけを insert する、あるいは更新頻度に応じてバッチ再構築のスケジュールを切る、といった設計が現実的です。メタデータに更新日を持たせておくと、古いNodeの特定・削除がしやすくなります。
コスト — 埋め込みと生成の両面を見る
コストは「埋め込み(インデックス構築時)」と「生成(クエリ時)」の2系統で発生します。次の3つを押さえると読みやすくなります。
- 埋め込みは永続化で使い回す:再構築のたびに全件再埋め込みしない。差分更新を基本にする。
- top_k と リランクで投入トークンを絞る:LLMに渡すNodeが多いほど生成コストが上がる。広く取って絞る二段構えがコスト面でも効く。
- モデルを使い分ける:検索・要約は安価なモデル、最終回答だけ高性能モデル、のように役割分担する。Settings やコンポーネント単位でモデルを差し替えられる。
本番導入では、入力(プロンプトインジェクション対策)、シークレット管理(APIキーは環境変数やシークレットマネージャーで管理し、コードにハードコードしない)、ログとモニタリングの整備も忘れずに行ってください。
参考・出典
- Starter Example (Python) — LlamaIndex 公式ドキュメント(参照日: 2026-06-03)
- Installation — LlamaIndex 公式ドキュメント(参照日: 2026-06-03)
- Building an Agent — LlamaIndex 公式ドキュメント(参照日: 2026-06-03)
- Retriever Module Guide — LlamaIndex 公式ドキュメント(参照日: 2026-06-03)
- Settings — LlamaIndex 公式ドキュメント(参照日: 2026-06-03)
- Node Parser Modules — LlamaIndex 公式ドキュメント(参照日: 2026-06-03)
- run-llama/llama_index — GitHub リポジトリ(参照日: 2026-06-03)
- llama-index-readers-web — PyPI(参照日: 2026-06-03)
まとめ:今日から始める3つのアクション
- 今日やること:
pip install llama-indexで環境を作り、data/にドキュメントを1つ入れて「読み込み→インデックス化→クエリ」の3行RAGを動かす。 - 今週中:
SentenceSplitterでチャンクを調整し、similarity_top_kとリランクで自分のデータに合う検索精度に詰める。 - 今月中:Query Engine を
QueryEngineToolでラップしてFunctionAgentに持たせ、FaithfulnessEvaluatorで評価を回しながら本番導入の判断材料を揃える。
あわせて読みたい:
- AIエージェント向けベクトルDB比較 — RAGの検索基盤に使うベクトルストアの選び方
- LangChain LCEL 完全ガイド — LlamaIndexと併用するオーケストレーション側の知識
- その他の実装ガイドは AIgent Lab 記事一覧 から
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』。
この記事を読んでRAG・AIエージェント導入のイメージが固まってきた方へ
Uravationでは、AIエージェント導入の研修・コンサルティングを行っています。お気軽にお問い合わせください。


