
「評価データセットがない」「本番想定のエッジケースを集められない」「fine-tuning用のデータが足りない」——AIエージェントやLLMアプリを本番投入する前に、誰もが一度はこの壁にぶつかります。そこで2026年6月時点で実務に定着しつつあるのが、LLMを使って評価・テスト・学習データを合成する(synthetic data generation)というアプローチです。
本記事は、RAGの検索精度を上げる話とは別の畑——「データを作る・評価する層」に焦点を当てます。実データが手に入らない場面でテスト/評価データセットをLLMで生成する基本設計、最小実装コード、品質担保の方法、そしてモデル崩壊(model collapse)やライセンスといった落とし穴まで、開発者・PMが押さえるべき論点を一気通貫で整理します。
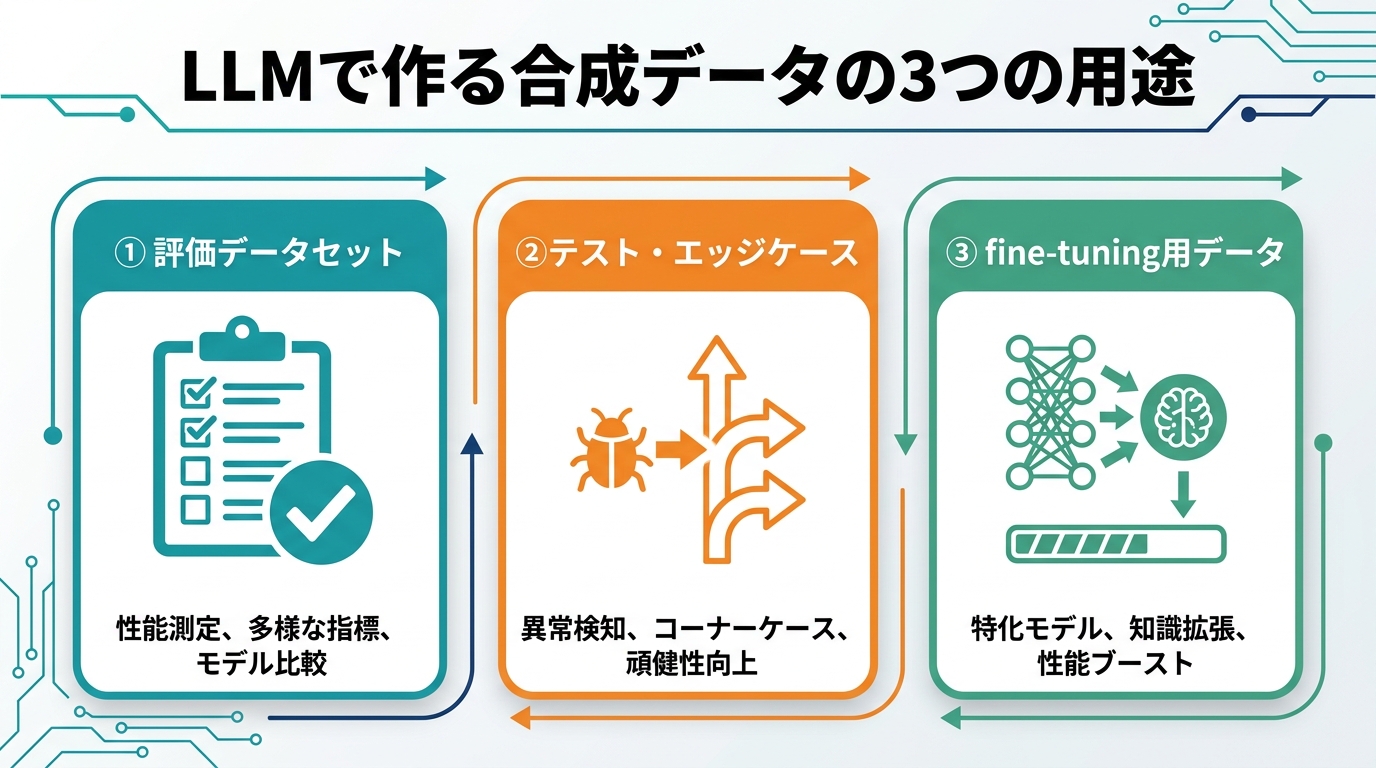
なぜAIエージェント開発で合成データが必要なのか
LLMアプリを評価・テストしようとすると、ほぼ確実に「正解データ(ground truth)が足りない」問題に直面します。合成データが求められる典型的な理由は次の4つです。
- 実データ不足:新規プロダクトには過去ログがありません。「100件の評価用QAペア」を人手で書くと数日かかります。
- プライバシー・コンプライアンス:本番ログには個人情報や顧客機密が含まれ、そのままテストや外部評価には回せません。実データの構造だけを模した合成データなら扱いやすくなります。
- エッジケースの網羅:本番で稀にしか起きない入力(曖昧な質問、矛盾する指示、極端に長い文脈など)は、自然に集めようとすると時間がかかります。LLMなら「こういう難しいケースを20個作って」と指定して短時間で揃えられます。
- 評価セット・学習データの量産:fine-tuningには数百〜数万件の指示データが要ります。人手だけでこの規模を賄うのは現実的ではありません。
実際、Argilla(distilabelの開発元)は、合成データを「fine-tuningとアライメント(alignment)のための実用的な手段」として位置づけ、人手アノテーションのボトルネックを解消する用途を公式ブログで解説しています。合成データは「人手データの完全な代替」ではなく、人手で作るコストが見合わない部分を埋める補完手段と捉えるのが正しい理解です。
合成データの3つの用途を分けて考える
合成データと一括りに言っても、用途によって求められる品質も生成の作り方もまったく違います。混同すると「評価データのつもりが評価にならない」事故が起きます。2026年6月時点で実務的に整理すると、用途は次の3つに分かれます。
| 用途 | 目的 | 重視する品質 | 典型的な規模 |
|---|---|---|---|
| 評価(eval set) | 本番品質を測る物差しを作る | 正確さ・代表性。少数でも質が命 | 数十〜数百件 |
| テスト(edge case) | 壊れる入力を事前に見つける | 多様性・難易度の高さ | 数十〜数百件 |
| 学習(fine-tuning) | モデルの挙動を改善する | 量とバランス。重複・偏りの排除 | 数百〜数万件 |
ここで最も注意したいのが、評価セットだけは「生成に使ったモデルと評価対象モデルを混同しない」という原則です。評価対象と同じモデルで正解を作ると、そのモデルが得意な範囲に物差しが寄り、甘い評価になります。評価セットの正解は別モデルで作る、あるいは人手で最終確認する——この切り分けが品質の分かれ目になります。LLMを審査役(LLM-as-a-Judge)として使う評価設計と組み合わせる場合は、生成と評価でモデルや役割を分離する考え方が前提になります。
LLMで合成データを生成する基本設計
合成データ生成の質は、ランタイムのモデル性能よりもプロンプト設計と多様性の出し方で決まります。雑に「QAを100個作って」と頼むと、似たような質問が量産され、評価にもテストにも使えないデータになります。多様性を意図的に作り込むための基本要素は次の3つです。
- seed(種)を変える:トピック・難易度・ユーザー像・質問タイプ(事実確認/手順/比較/反例)といった「軸」をseedとして与え、組み合わせを変えながら生成します。seedを固定しないことが多様性の源泉です。
- 制約を明示する:出力形式(JSON)、1件あたりの長さ、含めるべき要素・含めてはいけない要素を具体的に指定します。曖昧な指示は曖昧なデータを生みます。
- 難易度を段階化する:易しい/普通/難しい/意地悪(adversarial)の4段階で生成量を割り当て、テストでは難しい側を厚くします。
専用ツールとして実績があるのが、Argillaのdistilabelです。distilabelは、LLMによる生成と評価(AI feedback)をパイプラインとして組み、再現性・監査性を担保できるオープンソースフレームワークで、検索・リランキング用の合成データ生成チュートリアルも公式に提供されています。Meta(Llamaチーム)が公開するsynthetic-data-kitも、PDFやWebページから「ingest → create(QAペア/CoT生成)→ curate(LLM審査でフィルタ)→ save-as(Alpaca/OpenAI/ChatML形式で出力)」という4コマンドのCLIワークフローを提供しており、ドキュメントから学習データを起こす用途に向いています。まずは既存の正解がある領域で小さく試し、品質を確認してから規模を広げるのが安全です。
実装:評価用QAペアとエッジケースを生成する最小コード
ここでは外部ツールに依存せず、各社LLMのAPI(Claude / GPT / Geminiのいずれでも考え方は同じ)で評価用QAペアを生成する最小実装を示します。ポイントは「seedを回して多様性を出す」「JSON固定で機械処理できる形にする」「生成直後に最低限の検証をかける」の3点です。次の手順で組み立てます。
- seed軸を定義する:トピックと質問タイプの組み合わせを用意し、多様性の骨格を先に決めます。
- 生成プロンプトを組む:seedを差し込み、出力をJSON配列に固定します。
- LLMを呼び出し、JSONをパースする:パース失敗はその場で捨てて再生成します(壊れたデータを後段に流さない)。
- 最低限の検証をかける:必須フィールドの有無、空文字、極端に短い/長い出力を弾きます。
- 重複排除して保存する:問題文の正規化で近い重複を落とします。
import json
import anthropic # 例: Claude。GPT/Gemini でも構造は同じ
client = anthropic.Anthropic()
# 1. seed軸(トピック × 質問タイプ)で多様性の骨格を作る
TOPICS = ["返品ポリシー", "配送料", "アカウント設定", "支払い方法"]
QTYPES = ["事実確認", "手順", "比較", "反例(意地悪な質問)"]
def build_prompt(topic: str, qtype: str, n: int = 3) -> str:
return f"""あなたはECサポートのQA評価データを作る担当です。
トピック「{topic}」について、質問タイプ「{qtype}」のQAペアを{n}件作ってください。
制約:
- 出力はJSON配列のみ。前後に説明文を付けない
- 各要素は {{"question": ..., "answer": ..., "difficulty": "easy|medium|hard"}}
- 質問は実際のユーザーが書きそうな自然な日本語にする
- 回答は事実ベースで簡潔に
"""
def generate(topic: str, qtype: str):
msg = client.messages.create(
model="claude-sonnet-4-5", # 利用可能な最新モデルに置き換える
max_tokens=1024,
messages=[{"role": "user", "content": build_prompt(topic, qtype)}],
)
text = msg.content[0].text.strip()
try:
return json.loads(text) # 3. パース失敗はその場で捨てる
except json.JSONDecodeError:
return []
# 1〜3. seedを回して生成
raw = []
for topic in TOPICS:
for qtype in QTYPES:
raw.extend(generate(topic, qtype))
# 4. 最低限の検証
def is_valid(item: dict) -> bool:
q = item.get("question", "").strip()
a = item.get("answer", "").strip()
return bool(q) and bool(a) and 5 <= len(q) <= 300
clean = [x for x in raw if is_valid(x)]
# 5. 問題文の正規化で重複排除
seen, deduped = set(), []
for x in clean:
key = "".join(x["question"].split()).lower()
if key not in seen:
seen.add(key)
deduped.append(x)
with open("eval_qa.jsonl", "w", encoding="utf-8") as f:
for x in deduped:
f.write(json.dumps(x, ensure_ascii=False) + "n")
print(f"生成 {len(raw)} → 検証通過 {len(clean)} → 重複排除後 {len(deduped)}")
エッジケース生成も同じ骨格です。プロンプトの質問タイプを「文脈が矛盾する指示」「極端に長い入力」「想定外フォーマット」「インジェクションを誘う入力」に差し替えれば、テスト用の難しいデータが作れます。生成段階でdifficultyを付けておくと、後段でテストの難易度バランスを調整しやすくなります。
品質担保:検証・フィルタ・人手レビュー・重複排除
合成データは「生成して終わり」ではありません。むしろ生成後のキュレーション(curation)こそが品質を決めます。上のコードでは最小限の検証だけを入れましたが、実務では次の多層フィルタを組み合わせます。
- 構造検証:必須フィールド、型、長さ、JSON妥当性を機械的にチェックして弾く。
- 多様性チェック:埋め込みベクトルの類似度や問題文の正規化で近い重複を排除する。多様性が低いデータは評価・学習の両方で価値が下がります。
- LLM審査(curate):「この回答は質問に答えているか」「事実として妥当か」を別モデルにスコアリングさせ、閾値未満を落とす。distilabelやsynthetic-data-kitはこの工程を標準で備えています。
- 人手レビュー(サンプリング):全件は無理でも、各seedから数件を抽出して人が目視する。特に評価セットは最終的に人手で正解を確認するのが原則です。
重要なのは、用途ごとにフィルタの厳しさを変えることです。fine-tuning用なら量を確保しつつ偏りを均す方向、評価セットなら少数でも全件を人手確認する方向、と切り分けます。生成元のドキュメントが整理されていると合成データの質も上がるため、元データの抽出・構造化の段階から品質を意識すると効果的です。文書からデータを起こす場合の前処理は、ドキュメント解析・抽出のガイドも参考になります。また多様性チェックで使う埋め込みモデルの選び方は埋め込みモデル選定ガイドで詳しく解説しています。
落とし穴:モデル崩壊・バイアス増幅・ハルシネーション混入・ライセンス
合成データには固有のリスクがあります。これらを知らずに大量生成すると、データが「使えない」どころか「有害」になります。
モデル崩壊(model collapse)が最大の論点です。Shumailovらが2024年にNatureで発表した研究は、モデルが自身や類似モデルの出力で再帰的に学習すると、生成の多様性と品質が回復不能なほど劣化する現象を、言語モデルを含む複数の生成モデルで実証しました。後続研究では、わずか1%程度の合成データ混入でも崩壊が起こりうること、モデルやデータセットを大きくしても確実には防げないことが指摘されています。合成データを学習に使うなら、実データと必ず混ぜる・世代を再帰させない・人手で品質ゲートをかけるのが鉄則です。
- バイアス増幅:生成元モデルが持つ偏り(特定の言い回し、特定の答え方への偏重)がそのままデータに刻まれ、学習で増幅されます。seedの設計段階で意図的に分散させ、出力分布を監視します。
- ハルシネーション混入:LLMが作る「正解」には事実誤りが紛れます。特に評価セットの正解にハルシネーションが入ると、評価そのものが信用できなくなります。事実性が重要な用途では、出典のあるドキュメントを根拠に生成させる(grounding)か、人手で正解を確認します。
- ライセンス・利用規約:各社LLMの出力を「どう使ってよいか」は規約で定められています。商用利用や再配布の可否、競合モデルの学習への利用制限などは提供元ごとに異なるため、2026年6月時点でも生成元の利用規約を必ず確認してください。「生成できたから自由に使える」ではありません。公式で確認できない範囲は、利用前に法務・提供元へ照会するのが安全です。
評価ループへの組み込み方
合成データは作って保存するだけでは価値が出ません。継続的な評価ループに組み込んで初めて効きます。実務での組み込みは次の流れになります。
- 評価セットを固定する:一度品質確認した評価用QAペアをバージョン管理し、リグレッション測定の基準線にします。
- CI/CDに評価を組み込む:プロンプトやモデルを変えるたびに、固定した評価セットでスコアを自動計測します。
- 失敗ケースをテストに還元する:本番で見つかった失敗入力を匿名化・抽象化し、エッジケースの合成データとして追加します。テスト網が時間とともに厚くなります。
- 定期的に評価セットを更新する:仕様変更や新機能に合わせて評価セットを増補し、古くなった項目を退役させます。
OpenAIやAnthropicは、公式ドキュメントで評価(evals)の仕組みを提供しており、合成生成した評価セットをこうしたeval基盤に流し込むことで、生成→評価→改善のループを回せます。エージェントの挙動を測るLLM-as-a-Judge型の評価と組み合わせると、定量スコアと定性レビューの両輪で品質を追えるようになります。
まとめ:合成データは「補完」と「品質ゲート」がすべて
AIエージェント開発における合成データ生成は、実データ不足・プライバシー・エッジケース網羅・学習データ量産という現実的な課題を解く強力な手段です。2026年6月時点では、distilabelやsynthetic-data-kitといった専用ツール、各社LLMのAPIとクックブックが揃い、最小コードでも評価用QAペアやエッジケースを生成できます。
ただし成否を分けるのは生成そのものより後段の品質担保です。多層フィルタ・LLM審査・人手レビューで「使えるデータ」だけを残し、モデル崩壊・バイアス増幅・ハルシネーション・ライセンスという固有リスクを管理する。そして固定した評価セットを継続的な評価ループに組み込む。ここまでやって初めて、合成データは本番投入の信頼性を底上げします。まずは小さな評価セットから、品質ゲートを伴って始めてみてください。
この記事を読んで導入イメージが固まってきた方へ
UravationではAIエージェント導入の研修・コンサルを行っています。
参考・出典
- AI models collapse when trained on recursively generated data(Nature, Shumailov et al. 2024)
- A Note on Shumailov et al. (2024): AI Models Collapse When Trained on Recursively Generated Data(arXiv)
- distilabel Documentation(Argilla)
- argilla-io/distilabel(GitHub)
- Synthetic data for LLM fine-tuning and alignment(Argilla Blog)
- meta-llama/synthetic-data-kit(GitHub)
- Documentation Chatbot with Meta Synthetic Data Kit(Hugging Face Cookbook)
- openai/openai-cookbook(GitHub)


