
「ベクトルRAGを組んだのに、横断的な質問にまったく答えられない」——RAGを本番運用すると必ずこの壁にぶつかります。「Aさんと関わったプロジェクトを全部挙げて」「この資料群の主要テーマは?」といった、複数文書をまたいで関係性を辿る質問が、ベクトル検索だと致命的に弱いのです。
原因はシンプルで、ベクトルRAGは「質問に意味が近いチャンク」を上位N件取ってくるだけだから。点と点をつなぐ「関係」や、データセット全体を俯瞰する「要約」は、チャンクに書かれていない限り取り出せません。ここを補うのが、文書をナレッジグラフ(エンティティと関係のグラフ構造)に変換してから検索する GraphRAG です。
本記事では、GraphRAGがなぜ効くのか/どこでは効かないのかを正直に切り分け、Microsoft GraphRAG・LlamaIndex Property Graph・Neo4jという2026年6月時点の現行3手段を最小コードつきで比較します。最大の弱点「構築コストの高さ」の判断軸まで踏み込みますが、前提として、多くのケースでは普通のベクトルRAGの方が安く速い、という立場から始めます。
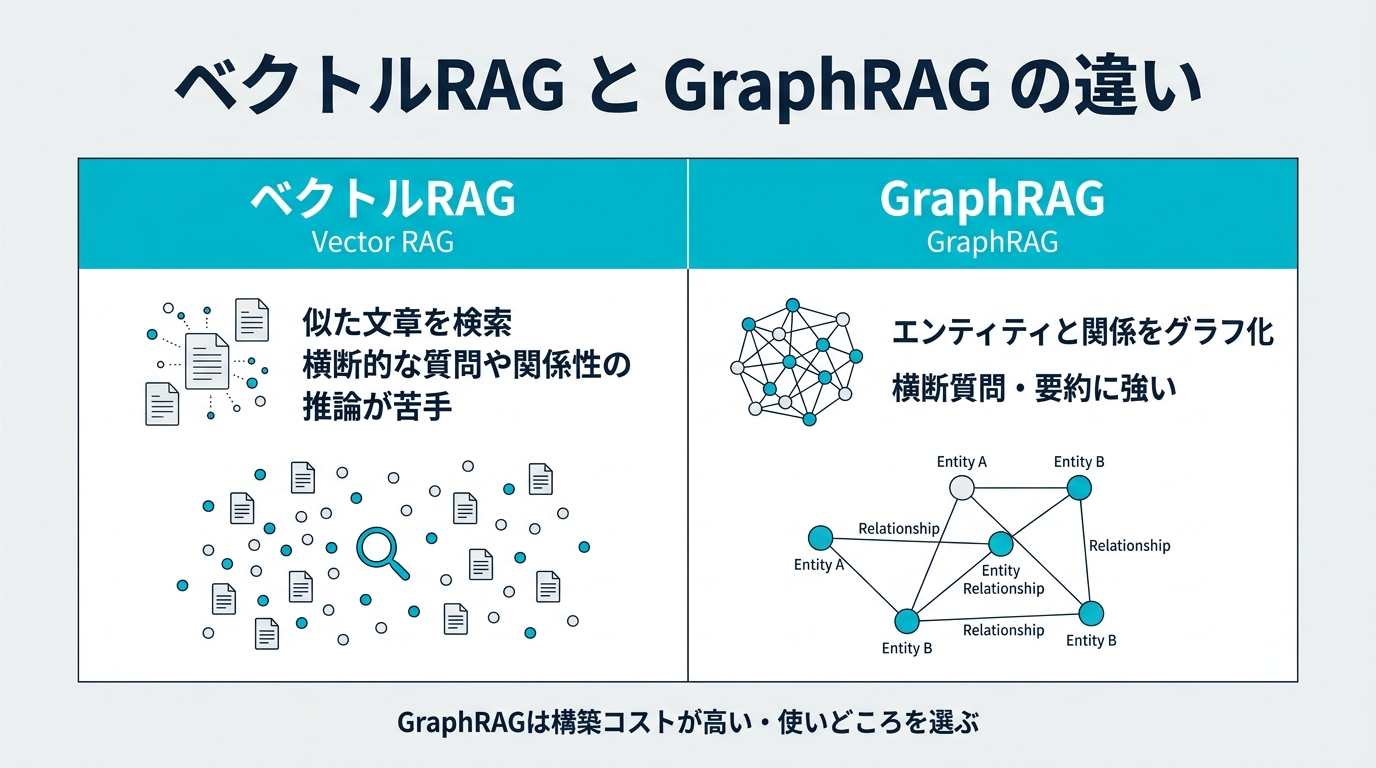
ベクトルRAGの限界とGraphRAGが効くケース・効かないケース
まず「いつGraphRAGを使うべきか」を明確にします。流行っているから入れる、はコストの無駄。判断基準は「質問が単一チャンクで完結するか、複数チャンクの関係を辿る必要があるか」の1点に集約されます。
ベクトルRAGが苦手な質問の型
- マルチホップ(多段推論):「Aさんがいたチームのリーダーがいま担当している案件は?」のように、A→チーム→リーダー→案件と関係を数珠つなぎに辿る質問。各ステップの情報が別チャンクに散っていると、ベクトル検索は途中で切れます。
- グローバル/要約型:「この500件の議事録に共通する主要トピックは?」のように、データセット全体を俯瞰しないと答えられない質問。近いチャンクを数件取っても、全体像は見えません。
- 関係性の集約:「製品Xに関係する取引先と、その関係の種類を全部教えて」のように、特定エンティティを起点に関係を網羅する質問。
GraphRAGはこの3つの型に強い構造を持ちます。文書をエンティティ(人・組織・製品など)と関係(所属・取引・参照など)のグラフに落とし込むため、関係を辿る検索や、コミュニティ単位の要約が自然にできるからです。
逆にGraphRAGを使わない方がいいケース
正直にお伝えすると、以下では素直なベクトルRAGの方が安く・速く・十分です。
- FAQ・単発参照型:「返品ポリシーは?」のように1チャンクで答えが完結する質問が大半なら、グラフ化のコストは回収できません。
- 文書が頻繁に更新される:後述する通りグラフ構築はLLM呼び出しを大量に使うため、毎日全文を作り直すような運用には不向きです。
- 文書数が少ない/構造が薄い:エンティティ間の関係が乏しいテキストでは、グラフを作っても恩恵が出ません。
迷ったら、まずベクトルRAGで作り、関係性・横断質問の精度が壁になってからGraphRAGを足す——この順番を推奨します。ベクトルRAGの設計は埋め込みモデル選定ガイドやリランク&ハイブリッド検索の精度改善ガイドで詰めておくと、GraphRAGへ進む判断もしやすくなります。
GraphRAGの仕組み:文書からナレッジグラフ、そしてハイブリッド検索まで
GraphRAGの処理は「インデックス構築(前処理)」と「検索(クエリ時)」の2フェーズに分かれ、重いのは前者です。
インデックス構築フェーズ(4ステップ)
- チャンク分割:文書を一定サイズのテキスト単位(text unit)に分割する。ここはベクトルRAGと同じ。
- エンティティ・関係抽出:各チャンクをLLMに渡し、「(エンティティ1, 関係, エンティティ2)」の三つ組(トリプル)を抽出する。例:「(佐藤, 所属, Uravation)」。文書全体ぶんを処理するため、ここでLLM呼び出しが大量に発生します。
- グラフ構築・エンティティ解決:抽出したトリプルをマージしてナレッジグラフを作る。「Uravation」と「株式会社Uravation」のような表記ゆれを同一ノードに統合する(エンティティ解決)処理が品質を左右します。
- コミュニティ検出・要約:グラフを Leiden アルゴリズム などで密に結合したクラスタ(コミュニティ)に分割し、各コミュニティの内容をLLMで要約しておく。この「コミュニティ要約」が、後述するグローバル検索の燃料になります。
検索フェーズ:グラフ+ベクトルのハイブリッド
クエリ時には用途に応じて2系統の検索を組み合わせます。これがGraphRAGの肝です。
- ローカル検索(Local Search):特定エンティティを起点に近傍ノード・関係・関連チャンクを集めて回答する。ベクトル類似度でエントリーポイントを見つけ、そこからグラフを辿る——つまりベクトルとグラフの併用です。「製品Xの仕様は?」のようなエンティティ中心の質問に向きます。
- グローバル検索(Global Search):事前生成したコミュニティ要約全体にmap-reduce的に部分回答を作り、最後に統合する。全体を俯瞰する質問に向く一方、計算コストが高い手法です(Microsoft公式も「resource-intensive」と明記)。
「グラフだけ」でも「ベクトルだけ」でもなく、エントリー検索はベクトル、関係の展開と全体要約はグラフという分業が、GraphRAGの精度の源泉です。
実装の選択肢:現行3手段を比較する
2026年6月時点で実用に足るGraphRAG実装手段は大きく3つ。思想と「どこまで面倒を見てくれるか」が違います。
| 手段 | 立ち位置 | コミュニティ要約/グローバル検索 | 向いている人 |
|---|---|---|---|
| Microsoft GraphRAG | 研究実装をパッケージ化したパイプライン | 標準搭載(Leiden+要約+global/local/DRIFT) | 論文どおりのグローバル要約をまず試したい |
| LlamaIndex Property Graph | RAGフレームワーク内のグラフ機能 | 標準では非搭載(自前で組む) | 既存のLlamaIndex資産にグラフ検索を足したい |
| Neo4j(neo4j-graphrag)+LLM | グラフDBベンダー公式SDK | 非搭載(DB側の柔軟性を活かす) | 本番でグラフを永続管理・運用したい |
以下、それぞれの最小コードと特徴を見ていきます。注意:本番投入前には必ずテスト環境で動作確認してください。料金・仕様は変動するため各公式ドキュメントで最新を確認することを前提にしています。
選択肢1:Microsoft GraphRAG(論文準拠・グローバル検索が標準)
Microsoftが公開するOSS(MITライセンス、2026年6月時点で v3.1.0、PyPIパッケージ名 graphrag)。論文「From Local to Global」の手法をそのままパイプライン化し、エンティティ抽出・Leidenによるコミュニティ検出・要約・global/local/DRIFT検索が一通り入っています。「グローバル要約型のGraphRAGをまず体験したい」ならここが最短です。
# 動作環境: Python 3.10+, graphrag (2026年6月時点 v3.1.0)
# pip install graphrag
# 1) 作業ディレクトリを初期化(設定ファイル settings.yaml が生成される)
graphrag init --root ./ragtest
# 2) 入力テキストを ./ragtest/input/ に置き、APIキー等を .env に設定したうえで
# インデックス構築(ここでLLM呼び出しが大量に走る=コスト注意)
graphrag index --root ./ragtest
# 3) データセット全体を俯瞰するグローバル検索
graphrag query --root ./ragtest --method global
--query "この資料群で最も重要なテーマを3つ挙げて"
# 4) 特定エンティティ中心のローカル検索
graphrag query --root ./ragtest --method local
--query "製品Xに関係する取引先を教えて"
ポイント
--method globalはコミュニティ要約を総なめするため、トークン消費とレイテンシが大きい。費用対効果を見ながら使い分けます。- ローカル検索を community 情報で拡張した DRIFT検索(
--method drift)も用意されており、Microsoftによれば「より多様な事実を回答に取り込める」とされています。 - 公式リポジトリ自身が「GraphRAGのインデックス構築は高コストな操作になりうる」と警告しています。小さなサンプルで費用を測ってから本番データに広げてください。
選択肢2:LlamaIndex Property Graph Index(既存RAG資産に足す)
すでにLlamaIndexでベクトルRAGを組んでいるなら、PropertyGraphIndex が現実的です。文書からトリプルを抽出する「抽出器」と、検索時の「リトリーバー」を部品として差し替えられるのが特徴で、ベクトル検索とグラフ検索を sub_retrievers で同時併用できます。
# 動作環境: Python 3.10+, llama-index 系パッケージ
# pip install llama-index llama-index-graph-stores-neo4j
from llama_index.core import PropertyGraphIndex, Settings
from llama_index.core.indices.property_graph import (
SimpleLLMPathExtractor, # LLMで単一ホップのトリプルを抽出(デフォルト)
VectorContextRetriever, # ベクトル類似でノードを引き、つながるパスを取得
LLMSynonymRetriever, # キーワード/類義語からノードを引く
)
# documents は事前に読み込んだ Document のリストとする
index = PropertyGraphIndex.from_documents(
documents,
kg_extractors=[SimpleLLMPathExtractor()], # 抽出器を差し替え可能
embed_kg_nodes=True, # ノードに埋め込みを付与
)
# ベクトル+グラフのハイブリッド検索(複数リトリーバーを同時実行)
retriever = index.as_retriever(
sub_retrievers=[VectorContextRetriever(index.property_graph_store),
LLMSynonymRetriever(index.property_graph_store)],
)
nodes = retriever.retrieve("製品Xに関係する取引先は?")
ポイント
- 抽出器は
SimpleLLMPathExtractorのほか、スキーマで型を縛るSchemaLLMPathExtractor、型を動的拡張するDynamicLLMPathExtractor、既存リレーションを使うImplicitPathExtractorから選択可。スキーマを固定するほどノイズが減り、精度が安定します。 - リトリーバーは
VectorContextRetriever/LLMSynonymRetrieverに加え、自然文をCypher化するTextToCypherRetriever、テンプレートCypherを使うCypherTemplateRetrieverを用途で組み合わせます。 - グラフストアは
SimplePropertyGraphStore(インメモリ)からNeo4jPropertyGraphStore等の本番向けまで差し替え可。検証はインメモリ、本番はNeo4jという移行が自然です。 - ただしコミュニティ要約・グローバル検索は標準非搭載。全体俯瞰質問が主目的ならMicrosoft GraphRAGが近道です。データ取り込み設計はLlamaIndex完全ガイドを参照。
選択肢3:Neo4j(neo4j-graphrag)+LLM(本番運用・永続管理向け)
グラフを「使い捨てのインデックス」でなく「運用し続けるデータ資産」として持ちたいなら、グラフDBのNeo4jが軸になります。公式SDK neo4j-graphrag(Python 3.10以上、旧 neo4j-genai の後継)には、テキスト/PDFからグラフを構築する SimpleKGPipeline が含まれ、エンティティ解決やスキーマによる剪定まで面倒を見てくれるのがDBベンダー製の強みです。
# 動作環境: Python 3.10+, neo4j-graphrag
# pip install neo4j-graphrag
import neo4j
from neo4j_graphrag.experimental.pipeline.kg_builder import SimpleKGPipeline
driver = neo4j.GraphDatabase.driver(URI, auth=(USER, PASSWORD))
# テキスト/PDFからエンティティ・関係を抽出してNeo4jへ書き込む
kg_builder = SimpleKGPipeline(
llm=llm, # 抽出に使うLLM
driver=driver,
embedder=embedder, # ノード埋め込み用
entities=["Person", "Company", "Product"], # スキーマで型を固定
relations=["WORKS_AT", "SUPPLIES", "RELATED_TO"],
from_pdf=False,
)
# await kg_builder.run_async(text="...社内文書テキスト...")
ポイント
- ノーコードで試すなら、ブラウザ上でPDFやURLからグラフを作れる「Neo4j LLM Knowledge Graph Builder」が手軽。まず可視化して抽出品質を目視確認してからコードに落とすと失敗が減ります。
- グラフがDBに永続化されるので、増分更新・部分削除・Cypherでの厳密クエリがしやすく、更新が入る業務データと相性が良いです。
- こちらもコミュニティ要約型のグローバル検索は標準機能でなく、必要なら自前実装になります(LangChainの
LLMGraphTransformerと組み合わせる構成例も公式ブログで紹介されています)。
コミュニティ要約とグローバル/ローカル検索の使い分け
GraphRAGの「効き」を最大化する鍵は、コミュニティ要約を軸にした検索モード選択です。Leidenによるコミュニティ検出はグラフを階層的なクラスタ(C0:最も粗い〜C3:最も細かい)に分け、各レベルの要約を事前生成することで回答の深さとトークンコストをトレードオフできるのが要点です。Microsoftの論文(arXiv:2404.16130)は、最も粗いルートレベル(C0)の要約を使うと、元テキストをそのまま要約する方式に比べてコンテキストトークンを97%以上削減できたと報告しています(2026年6月時点で確認)。
検索モードは次の3つで使い分けます。
- 「全体で何が言えるか」型 → グローバル検索:粗いレベルの要約から始め、足りなければ細かいレベルへ。トークン効率と網羅性をコミュニティ階層で調整。
- 「この対象について詳しく」型 → ローカル検索:特定エンティティの近傍に集中。安く速く、根拠チャンクも示しやすい。
- 「特定対象+周辺文脈も欲しい」型 → DRIFT検索:ローカル検索にコミュニティ情報を足し、より多様な事実を拾う。
同論文の評価では、約100万トークンのポッドキャスト書き起こし(8,564エンティティ/20,691関係)や約170万トークンのニュース記事群で、GraphRAGがベクトルRAGに対し回答の網羅性(comprehensiveness)と多様性(diversity)でおおむね優位という結果でした(LLMによるペアワイズ判定)。ただし特定コーパス・特定評価での結果であり、あらゆるデータで再現される保証はありません。自分のデータで小さく検証するのが鉄則です。
【要注意】GraphRAG導入でよくある失敗パターンと回避策
失敗1:いきなり全文をグローバル検索向けに作り込む
❌ 大量文書を一気にインデックス化し、最初からグローバル検索前提で組む。
⭕ まず数十文書で抽出品質とコストを測り、ローカル検索から始める。
なぜ重要か:エンティティ抽出は文書数に比例してLLM呼び出しが増えます。小さく測らず本番規模で回すと想定外のAPI費用が出ます。
失敗2:スキーマを決めずに抽出する
❌ 抽出器に型指定を渡さず「よしなに」全エンティティ・全関係を取る。
⭕ 「Person / Company / Product」のように許可する型を絞る。
なぜ重要か:型を絞らないと表記ゆれや無意味なノードが増え、グラフがノイズだらけに。SchemaLLMPathExtractor やNeo4jのスキーマ指定で枠をはめると精度と再現性が上がります。
失敗3:エンティティ解決を放置する
❌ 「Uravation」「株式会社Uravation」を別ノードのまま運用。
⭕ 表記ゆれを同一ノードへ統合するエンティティ解決を必ず入れる。
なぜ重要か:同一実体が分裂すると関係が辿れず、GraphRAGの強みが消えます。検索が効かない原因の多くはここです。
失敗4:ベクトルRAGで足りる場面に投入してしまう
❌ FAQ用途や単発参照にGraphRAGを使い、コストだけ膨らむ。
⭕ 横断質問・関係性・全体要約という明確な必要性がある時だけ採用する。
なぜ重要か:GraphRAGは精度のために構築コストを払う技術。必要性がないと、ただ高くて遅いRAGになります。
コストと構築の手間:採用判断のための現実的なトレードオフ
最後に「で、入れるべきか」の判断軸を整理します。GraphRAGの主なコストは次の3つです。
- 構築時のLLM費用:全文書をLLMでエンティティ抽出+要約するため、埋め込みだけのベクトルRAGより桁違いに高くなりがち。文書量が多いほど効きます。
- 再構築の手間:文書更新のたびに抽出をやり直す必要があり、増分更新を設計しないと運用が重い(永続管理ならNeo4j型が有利)。
- クエリ時コスト:特にグローバル検索は要約を総なめするためトークン消費が大きい。ローカル/DRIFTとの使い分けで抑えます。
一方リターンは「全体俯瞰・横断質問でのトークン効率(C0要約で97%以上削減)と回答品質の向上」。つまり“質問が重い”ほど投資は回収しやすく、質問が軽い(単発・FAQ中心)なら回収できません。
実務的な落としどころは、①まずベクトルRAGを本番運用し、②横断・関係性質問の精度が壁になったら、③その質問が来るサブ領域だけGraphRAGを足す(全文書をグラフ化しない)。この「部分適用」が最も現実的です。エージェント全体への組み込みはAIエージェント実装ロードマップ、グラフの永続先となるDB選定はベクトルデータベース比較ガイドもあわせて検討してください。
よくある質問(FAQ)
Q1. GraphRAGとは何ですか?
文書をエンティティと関係のナレッジグラフに変換し、グラフ構造で検索・回答するRAGの一種です。通常のベクトルRAGが苦手な「横断的な質問」「関係性の推論」「データセット全体の要約」を補強できます。
Q2. 普通のベクトルRAGとの一番の違いは?
ベクトルRAGは「意味が近いチャンク」を取るだけですが、GraphRAGは「エンティティ間の関係」を辿れます。さらにコミュニティ要約を使えば、全体を俯瞰する質問にも答えやすくなります。
Q3. どの実装から始めればいいですか?
グローバル要約を手早く試すならMicrosoft GraphRAG、既存のLlamaIndex資産に足すならPropertyGraphIndex、本番でグラフを永続管理するならNeo4jの neo4j-graphrag が出発点です。まずは小さなデータでMicrosoft GraphRAGを動かすのがおすすめです。
Q4. GraphRAGはベクトルRAGの上位互換ですか?
いいえ。構築コストが高く、FAQや単発参照のような軽い質問にはオーバースペックです。横断質問・関係性・全体要約という明確な必要性がある場合に限って効果的で、多くのケースではベクトルRAGで十分です。
Q5. 構築コストはどのくらい高いですか?
全文書をLLMでエンティティ抽出し、要約まで生成するため、埋め込みだけのベクトルRAGより大幅に高くなります。Microsoft公式も「高コストな操作になりうる」と警告しているので、必ず小さなサンプルで費用を測ってから本番に広げてください(料金・仕様は変動するため各公式で最新を確認)。
まとめ:今日から始める3つのアクション
- 今日:手元のRAGで「横断質問・関係性の質問」がどれだけ失敗するかを10件ほど試し、GraphRAGの必要性を数で確認する。
- 今週中:Microsoft GraphRAG(
pip install graphrag)に小さなサンプル文書を入れ、global/localの違いとコストを体感する。 - 今月中:効果が見えた領域だけに部分適用する設計に落とし込み、永続管理が要るならNeo4jへの移行を検討する。
この記事を読んでGraphRAGの導入イメージが固まってきた方へ
UravationではRAG・AIエージェントの設計・PoC・社内導入研修を支援しています。「ベクトルRAGで詰まっている」「どこまでグラフ化すべきか相談したい」段階からお気軽にどうぞ。
参考・出典
- Microsoft GraphRAG(GitHub公式リポジトリ・MITライセンス、2026年6月時点 v3.1.0)
- GraphRAG 公式ドキュメント:Query Engine(Global / Local / DRIFT Search)
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization(arXiv:2404.16130)
- LlamaIndex 公式ドキュメント:Property Graph Index
- Neo4j GraphRAG for Python(neo4j-graphrag)公式ドキュメント
- neo4j-graphrag(PyPI)
- Neo4j LLM Knowledge Graph Builder(Neo4j Labs)


