
結論: RAGの精度は「検索(retrieval)」と「生成(generation)」を分けて測らないと改善できない。RAGASは Context Precision / Context Recall(検索)と Faithfulness / Answer Relevancy(生成)を、評価用LLMで自動スコアリングするフレームワークで、各指標は0〜1で出力される(2026年6月時点)。
この記事の要点:
- 要点1: RAGの失敗は「検索が悪い」か「生成が悪い」かで打ち手が真逆。Context系とFaithfulness/Relevancy系を分離して測ると、どちらを直すべきかが切り分けられる。
- 要点2: 主要4指標はすべて0〜1スコア。Faithfulness=回答主張のうち文脈で裏づくものの割合、Context Recall=正解に必要な情報が検索で拾えた割合、と定義が明確。
- 要点3: RAGASは
evaluate()数行で回せるが、ほとんどの指標がLLM-as-judgeのため評価モデルのバイアスとAPIコストに注意が要る。
対象読者: RAGを実装したが「精度が上がったのか分からない」開発者・MLエンジニア
難易度: 中級
読了時間: 約11分
「チャンク分割を変えたら、なんとなく回答が良くなった気がする」——RAGを触ったことがある人なら、一度はこの曖昧さに直面したことがあるはずです。埋め込みモデルを差し替え、リランカーを足し、プロンプトを調整する。それでも「で、結局どれが効いたのか?」を数字で言えないと、改善は勘の積み重ねになってしまいます。
RAG(Retrieval-Augmented Generation)が普通の生成タスクと違うのは、「検索」と「生成」という性質の異なる2段階が直列でつながっている点です。最終回答だけを眺めても、検索が悪いのか生成が悪いのかは区別できません。だからこそ、RAG専用の評価設計が必要になります。
この記事では、RAGを定量評価するための指標体系を「検索の指標」と「生成の指標」に分けて整理し、それを自動化するフレームワーク RAGAS の使い方、そしてLLM-as-judge評価の落とし穴と運用への組み込み方までを、実装イメージ付きで解説します。RAGのパイプライン全体像はAIエージェント実装ロードマップでも触れていますが、本記事はその「評価」フェーズを深掘りする位置づけです。
なぜRAGには専用の評価が要るのか
通常のLLM出力評価(要約の質、コードの正しさなど)は、入力と出力の対応だけを見れば成立します。しかしRAGは、ユーザーの質問に対して①ベクトル検索などで文脈を集める(retrieval)→②集めた文脈をもとに回答を生成する(generation)という2工程を経ます。最終回答の良し悪しは、この2工程それぞれの良し悪しの合成です。
典型的な失敗を分解してみます。
- 検索は当たっているのに回答が間違う: 正しい文脈は取れているのに、LLMが文脈を無視して学習知識で答えたり、文脈を曲解している。→ 生成側(プロンプト/モデル)の問題。
- 回答は文脈に忠実だが、そもそも見当外れ: 検索で関係ない文書ばかり拾い、その範囲で「忠実に」答えてしまう。→ 検索側(チャンク分割/埋め込み/リランク)の問題。
この2つは打ち手が真逆です。前者でチャンク戦略をいじっても無駄ですし、後者でプロンプトを磨いても効きません。「最終回答が良いか」という1つの数字では、この切り分けができない。これがRAG専用評価の出発点です。
もう1つの背景として、RAGには「正解ドキュメントが分かっているか」で測れる指標が変わる事情があります。検索を厳密に測るには、本来「この質問にはこの文書が必要」という正解(ground truth)が要ります。しかし現場で全質問に正解文書を紐づけるのは高コストなため、後述するRAGASは正解回答(reference answer)を正解文書の代理として使うなど、現実的な近似を用意しています。なお、RAGの汎用的な検証・QA設計はRAGチャンキング戦略ガイドの延長線上にあり、評価指標はそこで決めた設計の良し悪しを数値で裏づける役割を持ちます。
RAG評価の全体像を、検索フェーズと生成フェーズの指標がどこに対応するかで整理すると次のようになります。
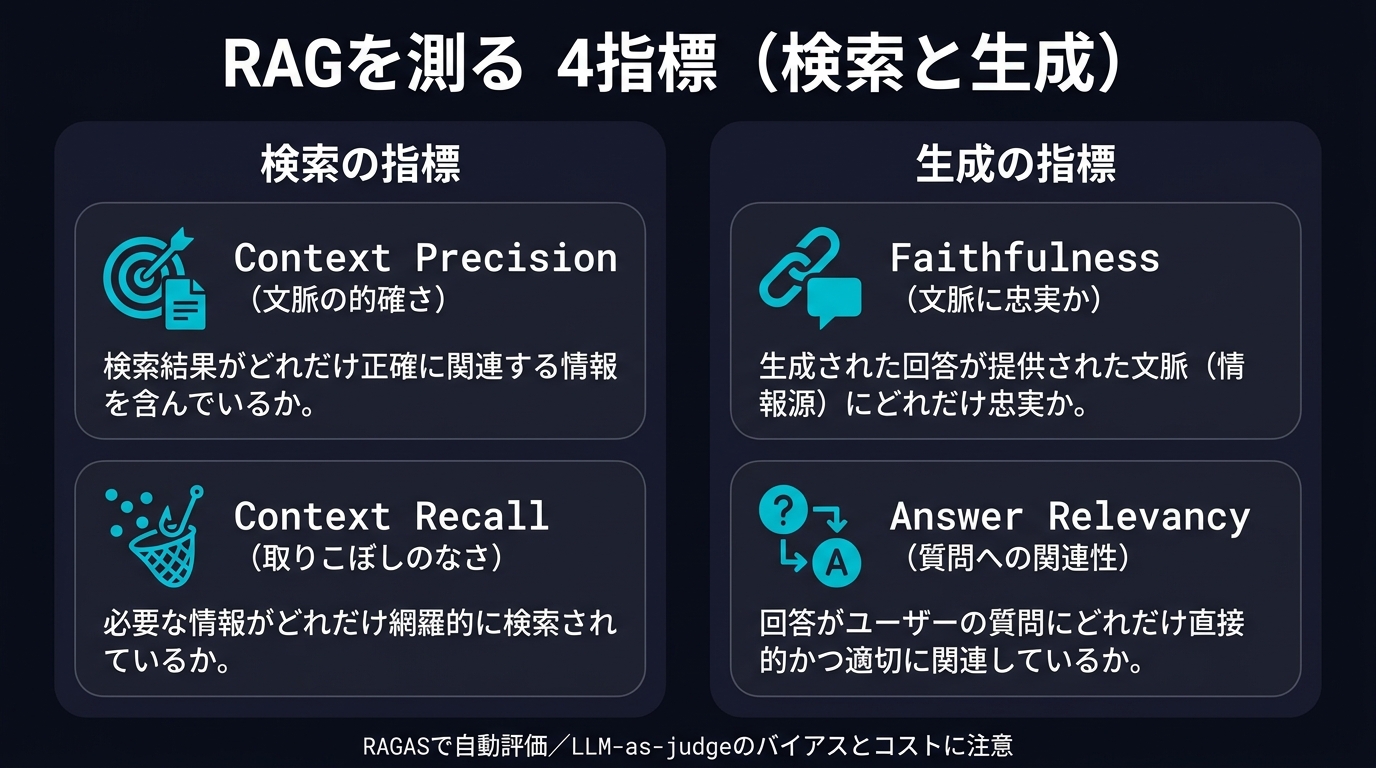
検索(retrieval)を測る指標:Context Precision と Context Recall
検索フェーズの評価は、情報検索(IR)の古典的な指標である Precision / Recall の考え方をRAGに持ち込んだものです。RAGASでは Context Precision と Context Recall として実装されています(定義は公式ドキュメントRAGAS Available Metrics、2026年6月時点)。
| 指標 | 測るもの | 計算の考え方 | 主な入力 | 範囲 |
|---|---|---|---|---|
| Context Precision | 関連する文脈を、上位に並べられているか(ランキングの精度) | 上位K件での precision@k の加重平均(mean precision@k) | user_input / retrieved_contexts / reference または response | 0〜1 |
| Context Recall | 正解に必要な情報を、取りこぼさず検索できたか(網羅性) | reference の主張のうち、retrieved_contexts で裏づく主張の割合 | user_input / retrieved_contexts / reference | 0〜1 |
Context Precision:関連文脈が上位に来ているか
Context Precision は「検索で取ってきた文脈の中で、関連するチャンクを無関係なチャンクより上位にランク付けできているか」を測ります。precision@k(上位k件中の関連文書の割合)を関連位置で加重平均する形で、関連文書が上位に来るほどスコアが高くなる設計です。RAGでは検索結果の上位だけがプロンプトに入ることが多いため、「上位に正しいものが来ているか」は実用上きわめて重要です。
RAGASのContext Precisionには複数のバリエーションがあります。
- reference あり(LLMベース): 正解回答と各文脈の関連性をLLMで判定。
- response ベース(LLMベース): 正解回答がない場合、生成した回答と文脈の関連性で代用。
- 非LLM(文字列類似度ベース): Levenshtein距離などの文字列類似度で関連性を判定し、LLM呼び出しを避ける。
- ID ベース: 文書IDの一致率(マッチしたID数 / 取得ID数)で算出。コンテンツ照合より高速。
Context Recall:必要な情報を取りこぼしていないか
Context Recall は「正解にとって必要な情報のうち、どれだけを検索で拾えたか」という網羅性を測ります。LLMベースの実装では、正解回答(reference)を主張(claim)に分解し、各主張が retrieved_contexts に裏づけられるかを確認して、その割合をスコアにします。
Context Recall =(reference の主張のうち retrieved_contexts で裏づく主張数)÷(reference の全主張数)
つまり Context Recall は reference(正解回答)を必須とする点に注意が必要です。正解回答を用意できない場合は、文字列比較で retrieved_contexts と reference_contexts を直接突き合わせる非LLM版や、文書IDで比較するID版を使います。Recallが低いということは「答えに必要な根拠がそもそも検索段階で落ちている」ことを意味し、この場合はチャンク分割・埋め込みモデルの選定・検索件数(top-k)の見直しが先決になります。
生成(generation)を測る指標:Faithfulness と Answer Relevancy
検索が正しくても、生成が文脈を裏切れば回答は信用できません。生成フェーズの代表指標が Faithfulness(忠実性) と Answer Relevancy(回答の関連性) です。
| 指標 | 測るもの | 計算の考え方 | 必要な要素 | 範囲 |
|---|---|---|---|---|
| Faithfulness | 回答が検索文脈と事実的に整合しているか(ハルシネーション検知) | 裏づけられた主張数 ÷ 回答の全主張数 | LLM | 0〜1 |
| Answer Relevancy | 回答が質問の意図にどれだけ沿っているか(事実性は測らない) | 回答から逆生成した質問と元質問の埋め込みコサイン類似度の平均 | LLM+Embedding | 0〜1(理論上 -1〜1) |
Faithfulness:回答は文脈に忠実か(ハルシネーション検知)
Faithfulness は「生成した回答が、検索で得た文脈とどれだけ事実的に整合しているか」を測ります。計算は明快で、回答を個々の主張(claim)に分解し、各主張が文脈で裏づけられるかをLLMで検証し、その割合をスコアにします。
Faithfulness =(文脈で裏づけられた主張数)÷(回答の全主張数)
公式ドキュメント(Faithfulness)の例では、回答に含まれる2つの日付主張のうち1つが文脈と矛盾する場合、スコアは0.5になります。Faithfulnessが低い回答は「文脈にない情報を勝手に足している=ハルシネーション」のサインです。ハルシネーション自体の防止策はリランク・ハイブリッド検索ガイドで扱う検索品質の改善とも連動しますが、Faithfulnessはその効果を「文脈に対する忠実度」という1つの数字で観測できる点に価値があります。
Answer Relevancy:回答は質問に答えているか
Answer Relevancy(Response Relevancy)は「回答が質問の意図にどれだけ沿っているか」を測ります。計算手順がやや独特で、次の3ステップです。
- LLMで、生成した回答から「この回答が答えになりそうな質問」を複数(デフォルト3つ)逆生成する。
- 逆生成した各質問と、元のユーザー質問を埋め込みベクトル化し、コサイン類似度を計算する。
- 類似度の平均をスコアとする。
直感的には、「回答から元の質問がきれいに復元できるなら、その回答は質問にちゃんと答えている」という発想です。冗長な情報や、質問とずれた回答はスコアが下がります(公式は「不完全な回答や不要な詳細を含む回答にペナルティを与える」と明記)。重要な注意点として、Answer Relevancy は事実の正しさ(factuality)は測りません。あくまで「質問の意図との一致」を見る指標であり、事実性はFaithfulnessや正解照合系の指標で別途担保する必要があります。理論上はコサイン類似度の範囲ゆえ -1〜1 を取りうるものの、実用上は0〜1の値として扱われます。
RAGASフレームワークの使い方
これらの指標を1本ずつ手で実装するのは現実的ではありません。RAGASは評価データセットと指標を渡すだけでまとめてスコアリングしてくれます。最小構成は次のとおりです(API・クラス名は2026年6月時点の安定版を参照。バージョンで変わりうる点に注意)。
評価データセットの準備
RAGASの評価データは、1サンプルあたり以下の4要素を持つ辞書のリストです。
dataset = [
{
"user_input": "RAGの検索精度はどの指標で測る?",
"retrieved_contexts": [
"Context PrecisionとContext Recallは検索フェーズの指標で...",
"Faithfulnessは生成された回答の忠実性を..."
],
"response": "検索精度はContext PrecisionとContext Recallで測ります。",
"reference": "RAGの検索フェーズはContext PrecisionとContext Recallで評価する。"
},
# ... さらにサンプルを追加
]
user_input: ユーザーの質問retrieved_contexts: 検索で取得した文脈(ランク順のリスト)response: RAGが生成した回答reference: 正解回答(Context Recall や正解照合系で必要)
評価の実行
評価モデル(LLM-as-judge)をラップし、使いたい指標を並べて evaluate() を呼ぶだけです。
from ragas import EvaluationDataset, evaluate
from ragas.llms import LangchainLLMWrapper
from ragas.metrics import (
LLMContextRecall,
Faithfulness,
ResponseRelevancy,
LLMContextPrecisionWithReference,
)
# 評価データをRAGAS形式に変換
evaluation_dataset = EvaluationDataset.from_list(dataset)
# 評価用LLM(judge)をラップ
evaluator_llm = LangchainLLMWrapper(llm)
# 検索+生成の両方を一括評価
result = evaluate(
dataset=evaluation_dataset,
metrics=[
LLMContextPrecisionWithReference(), # 検索:上位に正しい文脈が来ているか
LLMContextRecall(), # 検索:必要な情報を拾えたか
Faithfulness(), # 生成:文脈に忠実か
ResponseRelevancy(), # 生成:質問に答えているか
],
llm=evaluator_llm,
)
print(result) # 各指標のスコア(0〜1)が返る
結果は context_precision / context_recall / faithfulness / answer_relevancy といったキーでスコアが返ります。検索系のスコアが低ければ検索を、生成系が低ければ生成を直す——という冒頭の切り分けが、ここで初めて数字で実行できるようになります。Embeddingを使う指標(Answer Relevancy)では評価用の埋め込みモデルも別途渡す構成になる点だけ、バージョンのドキュメントで確認してください。
評価データセットをどう作るか
評価の質は、評価データセットの質で決まります。ポイントは3つです。
- 本番に近い質問を集める: 実ログ(ユーザーの実際の問い合わせ)からサンプリングするのが理想。机上で作った質問は実運用の弱点を見逃します。
- 正解(reference)を用意する: Context RecallやFactualCorrectness系は正解回答/正解文脈を必要とします。全件は無理でも、まず数十件のゴールデンセットを人手で作る価値があります。
- 合成データで量を補う: 人手だけでは件数が足りない場合、LLMで質問と正解のペアを生成する手もあります(ただし合成データ特有のバイアスに注意)。
LLM-as-judge評価の落とし穴と運用への組み込み
ここまで見たRAGAS指標の多く(Faithfulness、Context Recall、reference版Context Precision、Answer Relevancyの質問生成部分)はLLM-as-judge=評価そのものにLLMを使う方式です。便利な反面、固有の落とし穴があります。
よくある失敗パターンと回避策
失敗1: 評価モデルのバイアスを無視する
❌ judgeに使うLLMが特定の言い回しや長い回答を好むクセを持つと、スコアが偏る。
⭕ 重要指標は人手評価と突き合わせ、judgeのスコアが人間判断と相関するかを最初に確認する。reference版・非LLM版を併用して相互チェックする。
失敗2: スコアを「絶対値」として信じる
❌ 「Faithfulness 0.82だから合格」と単発の絶対値で判断してしまう。
⭕ LLM評価には揺らぎがある。同じデータセットでの相対比較(施策前後の差分)を主に見る。閾値は自分のデータで較正する。
失敗3: コストを見積もらない
❌ LLMベース指標は1サンプルあたり複数回のLLM呼び出しが発生する。数千件×複数指標を毎回回すと、API課金が無視できない額になる。
⭕ 回帰テストは小さめのゴールデンセットに絞り、フルセットはマイルストーン時のみ。非LLM版(文字列類似度・ID照合)で代替できる指標は代替する。
コストを抑える具体策として、検索フェーズの評価は文書IDが分かっているならID照合の非LLM版に寄せるのが効きます。LLM呼び出しゼロで Context Precision / Recall を概算でき、毎コミットの軽量チェックに向きます。重い Faithfulness 等はマイルストーン時のフルセット評価に回す、という二層構成が現実的です。
from ragas.metrics import NonLLMContextPrecisionWithReference
# retrieved_contexts と reference_contexts の文字列類似度で関連性を判定
# → LLM呼び出しなし。CIの軽量回帰チェック向き
non_llm_precision = NonLLMContextPrecisionWithReference()
result = evaluate(
dataset=evaluation_dataset,
metrics=[non_llm_precision], # judge LLM 不要
)
「毎コミットは非LLM版で素早く・週次やリリース時はLLM版でしっかり」と頻度を分けるだけで、評価コストは大きく下げられます。
失敗4: 正解のないまま検索指標を測ろうとする
❌ Context Recallはreferenceがないと成立しないのに、用意せずに「Recallが出ない」と悩む。
⭕ referenceが用意できないフェーズでは、まずFaithfulnessとAnswer Relevancy(referenceなしで測れる)から始める。
評価を回し続ける運用ループ
評価は「一度測って終わり」ではなく、改善のたびに回す回帰テストとして組み込むのが本筋です。実務での回し方は次のとおりです。
- ゴールデンセットを固定する: 30〜100件程度の代表質問+正解を用意し、これを基準データとして固定する。
- ベースラインを測る: 現行RAGで4指標のスコアを記録。これが比較の原点になる。
- 1施策ずつ変える: チャンクサイズ、埋め込みモデル、リランカー、プロンプトを同時に複数いじらない。1つ変えて再評価し、どの指標が動いたかを見る。
- しきい値で回帰を検知する: 「Faithfulnessが前回比 -0.05 を超えたらCIを落とす」など、劣化を自動検知する閾値をパイプラインに入れる。
- 本番ログでドリフトを監視する: オフライン評価に加え、本番の回答をサンプリングして定期評価し、データ分布の変化による精度劣化を早期に捕まえる。
この運用ループにより、「なんとなく良くなった気がする」が「Context Recallが0.71→0.84に上がった=検索の取りこぼしが減った」という言語化された改善に変わります。評価をCIや観測基盤に統合する話は、より広いLLMアプリの評価設計としてAI Evals × LLM-as-a-Judge設計でも整理しています。RAG特化(本記事)とアプリ全体のEval設計(同記事)を組み合わせると、評価の射程が漏れにくくなります。
まとめ: 今日から始める3つのアクション
- 今日: 自分のRAGの回答を5件選び、「検索が悪いのか/生成が悪いのか」を手で分類してみる。これだけで切り分けの感覚が掴めます。
- 今週中:
pip install ragasで導入し、10件の評価データ(user_input / retrieved_contexts / response / reference)を作ってevaluate()を回し、4指標のベースラインを記録する。 - 今月中: ゴールデンセットを30件規模に拡張し、チャンク・埋め込み・リランクの施策を1つずつ変えて回帰評価する運用ループをCIに組み込む。
AIエージェント・ツールの最新情報をキャッチアップしたい方へ
Agent Labでは、週1回のニュースレターでAIツールの最新比較・活用事例をお届けしています。
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』(SBクリエイティブ)。
ご質問・ご相談は お問い合わせフォーム からお気軽にどうぞ。
参考・出典
- RAGAS — Available Metrics — Ragas 公式ドキュメント(参照日: 2026-06-04)
- RAGAS — Faithfulness — Ragas 公式ドキュメント(参照日: 2026-06-04)
- RAGAS — Context Precision — Ragas 公式ドキュメント(参照日: 2026-06-04)
- RAGAS — Context Recall — Ragas 公式ドキュメント(参照日: 2026-06-04)
- RAGAS — Response Relevancy(Answer Relevancy) — Ragas 公式ドキュメント(参照日: 2026-06-04)
- RAGAS — Evaluate a simple RAG — Ragas 公式ドキュメント(参照日: 2026-06-04)
- explodinggradients/ragas — GitHub リポジトリ(参照日: 2026-06-04)
あわせて読みたい:AIエージェントの継続的評価とCI/CD回帰検知 運用ガイド


