
「長コンテキストのモデルに乗り換えたのに、なぜかエージェントの精度が落ちた」――AIエージェントを運用していると、こういう逆転現象に必ず一度はぶつかります。プロンプトを磨き込んでも、ツール定義を増やしても、履歴を全部詰め込むと逆に賢くなくなる。
2025年から2026年にかけて、現場の関心は「プロンプトエンジニアリング」から「コンテキストエンジニアリング(context engineering)」へと移りました。Anthropicは2026年6月時点で、これを「推論時にコンテキストウィンドウへ載せるトークン群を、最適な状態に整え・維持する一連の戦略」と定義しています(Anthropic, Effective context engineering for AI agents)。
この記事では、限られたコンテキストウィンドウに「何を・どれだけ・どの順で載せるか」を設計する技術を、トークン計測・予算割当・動的圧縮のコード例つきで整理します。RAGやメモリ単体の話とは別軸の、設計の勘所に絞って解説していきます。
なぜ「コンテキストエンジニアリング」が重要になったのか
プロンプトエンジニアリングは「モデルへの指示文をどう書くか」の技術でした。一方コンテキストエンジニアリングは、指示文だけでなく、システムプロンプト・会話履歴・ツール定義・ツール実行結果・検索で取ってきた情報・長期メモリまで含めた「コンテキストウィンドウ全体の構成をどう設計するか」を扱います。Anthropicはこの違いを、プロンプトエンジニアリングの自然な発展形として位置づけています。
「コンテキストウィンドウが100万トークンになれば、もう全部入れればいいのでは?」と思うかもしれません。ところが、ここに大きな落とし穴があります。長コンテキスト対応モデルが普及した2026年でも、トークン予算の制約と精度劣化は消えていません。
長コンテキストでも残る2つの課題
ひとつめは lost in the middle(ロスト・イン・ザ・ミドル) です。2023年のStanfordらの研究は、モデルが入力の「先頭」と「末尾」の情報には強く注目する一方、「真ん中」に置かれた情報の利用が苦手になることを示しました。性能を入力位置に対してプロットするとU字カーブを描く、という報告です(Liu et al., Lost in the Middle, 2023)。重要な情報を履歴の中央に埋めてしまうと、モデルがそれを見落としやすくなります。
ふたつめは context rot(コンテキスト・ロット) です。Chromaの調査は18のフロンティアモデルを対象にし、入力長が伸びるほどすべてのモデルで性能が低下することを報告しています(Chroma, Context Rot)。Anthropicも同じ現象を、Transformerが n トークンに対して n² の組み合わせ的な関係を持つために、長い系列ではモデルの注意(attention)が薄く引き伸ばされてしまう、と説明しています。つまり、コンテキストは「容量」ではなく、使うほど目減りする「予算」として扱うべき有限のリソースなのです。
だからこそ、何を入れて何を捨てるかを設計する技術――コンテキストエンジニアリングが、エージェント開発の中心テーマに浮上しました。
コンテキストに載るものと予算配分
まず、エージェントのコンテキストウィンドウに何が入っているのかを棚卸ししましょう。設計の出発点は「自分のエージェントが各リクエストで何トークン消費しているか」を把握することです。
| 構成要素 | 中身 | 性質 | 削りやすさ |
|---|---|---|---|
| システムプロンプト・指示 | 役割・制約・出力形式 | 毎回ほぼ固定 | 低(だが冗長は削る) |
| ツール定義 | 関数名・引数スキーマ・説明 | 毎回固定だが肥大しやすい | 中(使うものだけに絞る) |
| 会話履歴 | 過去のユーザー発話・モデル応答 | ターンごとに増える | 高(要約・刈り込み対象) |
| ツール実行結果 | API応答・検索結果・ログ | ターンごとに増え、巨大化しやすい | 高(縮約の主戦場) |
| 取得情報(RAG等) | 外部知識・ドキュメント片 | 必要時に動的取得 | 高(件数と長さを絞る) |
| メモリ・ノート | 長期に残す要約・決定事項 | コンテキスト外に保持 | ―(外部保存が前提) |
ポイントは、「毎回固定で削りにくいもの」と「ターンごとに膨らむ削りやすいもの」を分けて考えることです。システムプロンプトとツール定義は固定費、会話履歴とツール結果は変動費。エージェントが長く動くほど効いてくるのは変動費の方です。
予算配分の考え方はシンプルです。コンテキストウィンドウの上限から、固定費(システム+ツール)と「次の応答を生成するために空けておく出力枠」を引いた残りが、履歴・取得情報・メモリで分け合える「可変予算」になります。この可変予算を超えそうになったら、圧縮や刈り込みを発動する――これが動的圧縮の基本設計です。
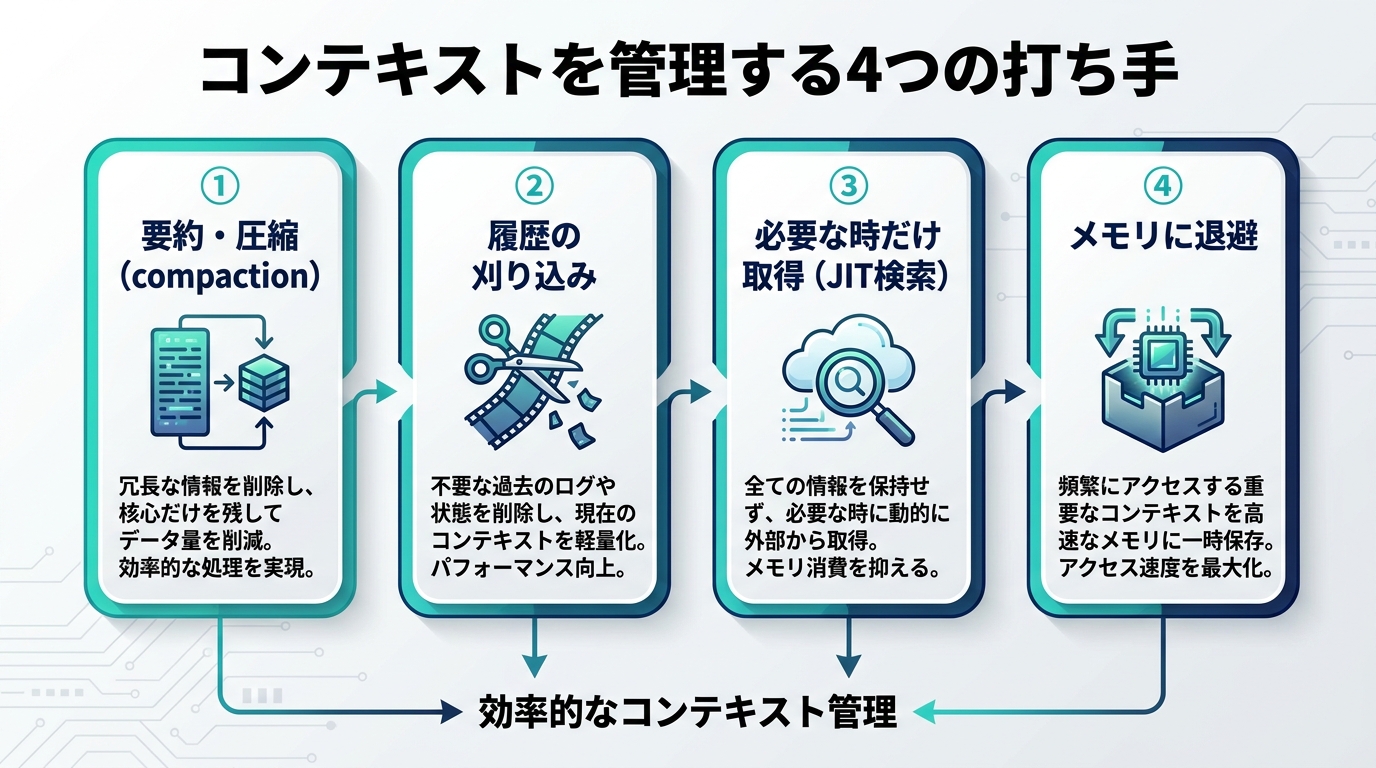
主要テクニック:圧縮・刈り込み・縮約・取捨選択
可変予算をやりくりする代表的な手法を整理します。一気に全部入れる必要はなく、エージェントの性質に合わせて組み合わせます。
1. 要約・コンパクション(compaction)
会話履歴が長くなったら、古いやり取りを要約に置き換えて再初期化します。Anthropicはこれをコンパクションと呼び、「アーキテクチャ上の決定事項は残し、冗長な出力は捨てる」ことを推奨しています。決定・前提・未解決の課題は残し、途中の試行錯誤ログは要約に畳むイメージです。
2. 履歴の刈り込み(トリミング)
要約せずに古いメッセージを単純に落とす方法です。直近Nターンだけ残す、あるいはトークン上限に収まるよう先頭から削る。lost in the middle を踏まえると、本当に重要な指示はシステムプロンプト側(先頭)か直近(末尾)に置くのが安全です。
3. ツール結果の縮約
巨大なAPI応答やログをそのまま貼り付けるのは、context rot を最も招きやすいアンチパターンです。JSONなら必要なフィールドだけ抜く、ログなら件数を絞る、長文なら要点だけにする。ツール結果の縮約は、変動費を抑える最大の効きどころです。
4. 重要度による取捨選択
取得情報を載せる際は「上位何件まで」「1件あたり何トークンまで」を決め打ちします。関連度スコアでソートし、予算に収まる分だけ採用する。件数を増やすほど精度が上がる、という直感は長コンテキストでは成り立たないことを思い出してください。
5. ジャストインタイム取得
すべてのデータを事前ロードせず、エージェントが必要になった時点でツール経由で取りに行く設計です。Anthropicはこれを人間の認知に近いアプローチとして挙げています。最初から全部載せるのではなく、「いま必要な分だけ」を都度フェッチすることで、コンテキストを高シグナルに保てます。
メモリとの接続:短期と長期で何を残すか
コンテキストエンジニアリングとメモリは地続きです。コンテキストウィンドウは「短期記憶」、その外に置く永続ストアが「長期記憶」と整理すると分かりやすいでしょう。
Anthropicが紹介する 構造化ノートテイキング(structured note-taking) は、エージェントが NOTES.md のような外部ファイルに進捗・決定・残タスクを書き出し、コンテキストを消費せずに長時間タスクの一貫性を保つ手法です。コンテキストが圧縮で畳まれても、ノートを読み直せば文脈を復元できます。
残すべきは「再生成が難しいもの」です。ユーザーの要求・確定した設計判断・失敗から得た教訓・外部システムの状態などは長期メモリへ。逆に、途中の冗長な思考ログや一度きりのツール出力は、要約して捨ててよい短期情報です。MemGPT/Letta のようなメモリ専用フレームワークは「どう保存・想起するか」を担いますが、コンテキストエンジニアリングは「想起した結果をどう載せるか」を担う、という役割の違いがあります。
RAGとの役割分担
RAG(検索拡張生成)とコンテキストエンジニアリングは、よく混同されますが別軸の技術です。
| 観点 | RAG | コンテキストエンジニアリング |
|---|---|---|
| 主な役割 | 外部知識を「検索して取得する」 | 取得したものを含め「どう載せるか」を設計する |
| 関心事 | 適合度・再現率(取り逃さないか) | トークン予算・順序・精度劣化の回避 |
| 失敗の出方 | 関係ない文書を引いてくる | 引いた文書を詰め込みすぎて精度が落ちる |
RAGが「何を取ってくるか」を解くなら、コンテキストエンジニアリングは「取ってきたうちの何を、何件、どの位置に置くか」を解きます。検索精度を上げても、上位20件をそのまま全部コンテキストに流し込めば lost in the middle で台無しになる。検索(取得)と配置(積載)は、別々に最適化すべき工程なのです。検索側の精度を詰めたい場合は、当サイトのリランク・ハイブリッド検索でRAG精度を高める完全ガイドや、データフレームワークの選び方をまとめたLlamaIndex完全ガイドも参考になります。
【要注意】よくある失敗パターンと回避策
失敗1:とりあえず全部コンテキストに詰め込む
❌ 履歴・取得文書・ツール結果を上限ギリギリまで載せる
⭕ 可変予算の上限を決め、超えたら圧縮・刈り込みを発動する
なぜ重要か:context rot により、入力が長いほどモデルの精度は下がります。トークン量は「使えるリソース」ではなく「使うほど劣化する予算」です。詰め込みは精度低下とコスト増を同時に招きます。
失敗2:重要な情報を履歴の真ん中に置く
❌ 守ってほしい制約を10ターン前のメッセージに書いたまま放置
⭕ 不変の制約はシステムプロンプト(先頭)へ、直近の指示は末尾へ
なぜ重要か:lost in the middle の U字カーブにより、中央の情報は見落とされやすい。位置は精度に直結する設計変数です。
失敗3:古い情報を圧縮せず混入させる
❌ 解決済みの試行錯誤や撤回した仮説が履歴に残り続ける
⭕ コンパクション時に「現在も有効な決定」だけを要約に残す
なぜ重要か:古い・矛盾した情報がコンテキストに残ると、モデルがそれを引きずって誤った前提で動きます。圧縮は「容量節約」だけでなく「ノイズ除去」の役割も持ちます。
実装の勘所:トークン計測・予算割当・動的圧縮
ここからは手を動かします。トークンを計測し、予算を割り当て、超過時に履歴を圧縮する最小構成を作ります。動作環境:Python 3.11+ / tiktoken>=0.7 / anthropic>=0.40(2026年6月時点)。本番環境で使用する前に、必ずテスト環境で動作確認してください。
ステップ1:トークンを計測する
まず、メッセージ列が何トークンかを測ります。ここでは概算用に tiktoken を使います(モデルが異なる場合の正確な数は各社のトークナイザに依存するため、あくまで予算管理の目安として使います)。
# 動作環境: Python 3.11+, tiktoken>=0.7
# pip install tiktoken
import tiktoken
# 概算用のエンコーダ(予算管理の目安)
_enc = tiktoken.get_encoding("cl100k_base")
def count_tokens(text: str) -> int:
return len(_enc.encode(text))
def count_messages(messages: list[dict]) -> int:
# role + content をまとめて概算
total = 0
for m in messages:
total += count_tokens(m.get("role", ""))
total += count_tokens(m.get("content", ""))
total += 4 # メッセージ区切りの固定オーバーヘッド分
return total
ポイント:トークナイザはモデルごとに違うため、これは正確値ではなく「予算の見積もり」です。重要なのは絶対値より、上限に対する割合を継続的に監視できることです。
ステップ2:コンテキスト予算を割り当てる
固定費(システム+ツール定義)と出力枠を差し引いて、履歴に使える可変予算を求めます。
from dataclasses import dataclass
@dataclass
class ContextBudget:
window: int # モデルのコンテキスト上限
reserved_output: int # 応答生成用に空けておく枠
system_tokens: int # システムプロンプト
tool_tokens: int # ツール定義
def history_budget(self) -> int:
used = self.reserved_output + self.system_tokens + self.tool_tokens
return max(self.window - used, 0)
# 例: 上限200,000、出力枠8,000、固定費を計測値から算出
budget = ContextBudget(
window=200_000,
reserved_output=8_000,
system_tokens=count_tokens(SYSTEM_PROMPT),
tool_tokens=TOOL_DEF_TOKENS,
)
print("履歴に使える可変予算:", budget.history_budget())
ポイント:reserved_output を必ず確保するのが肝です。ここを忘れると、入力で枠を使い切って応答が途中で切れる事故が起きます。
ステップ3:予算超過時に履歴を動的圧縮する
履歴が可変予算を超えたら、古いメッセージを要約に畳んで再構成します。直近ターンはそのまま残し、それより前を1つの要約メッセージに置き換えるシンプルなコンパクションです。
# 動作環境: Python 3.11+, anthropic>=0.40
# 古い履歴を要約に畳む最小コンパクション
KEEP_RECENT = 6 # 直近6メッセージは原文のまま残す
def compact_history(messages: list[dict], budget: int) -> list[dict]:
if count_messages(messages) <= budget:
return messages # 予算内なら何もしない
recent = messages[-KEEP_RECENT:]
old = messages[:-KEEP_RECENT]
if not old:
return messages # 畳む対象がなければそのまま
# 古い履歴を1つの要約に圧縮(決定・前提・残タスクを残す方針)
summary_text = summarize_old_messages(old)
summary_msg = {
"role": "user",
"content": f"[これまでの要約]n{summary_text}",
}
return [summary_msg, *recent]
def summarize_old_messages(old: list[dict]) -> str:
# 実運用ではLLMに「決定事項・前提・未解決課題のみ残して要約」と指示する
# ここでは要点抽出のプレースホルダ
joined = "n".join(m.get("content", "") for m in old)
# 注意: 本番では要約用に低コストモデル(例: Haiku系)を使うとコスト効率が良い
return joined[:2000] # 例示用の単純切り詰め
ポイント:要約の指示は「決定事項・前提・未解決課題だけを残す」と明示します。何を残すかを決めるのがコンパクションの本質で、単なる文字数削減ではありません。要約自体は低コストモデルに任せると、運用コストを抑えられます。コスト設計全般はAIエージェントのコスト最適化7原則も合わせてご覧ください。
ステップ4:プロンプトキャッシュで固定費を回収する
システムプロンプトとツール定義は毎回ほぼ同じ内容です。これらを プロンプトキャッシュ に載せると、2回目以降の入力コストを大きく下げられます。Anthropicのドキュメントによれば、2026年6月時点でキャッシュ読み出しは基本入力単価の0.1倍、5分キャッシュの書き込みは1.25倍です(Anthropic, Prompt caching)。固定費の塊である先頭部分をキャッシュ境界にするのが定石です。
# 動作環境: anthropic>=0.40(2026年6月時点)
# システム+ツール定義をキャッシュ境界に置く
import anthropic
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2000,
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # 毎回固定の指示
"cache_control": {"type": "ephemeral"}, # ここまでをキャッシュ
}
],
messages=compact_history(messages, budget.history_budget()),
)
ポイント:キャッシュ境界はコンテキストの「動かない部分」と「動く部分」の境目に置きます。料金・仕様は変動するため、導入前に必ず公式ドキュメントで最新の単価とキャッシュTTLを確認してください。
評価:圧縮しても精度が落ちていないか
コンテキストエンジニアリングは「やって終わり」ではなく、効果測定が必須です。圧縮を入れた結果、コストは下がったが精度も下がった、では本末転倒だからです。
- 固定の評価セットを用意する:典型的なタスク20〜50件を、期待出力つきで揃えます。
- 圧縮あり/なしで比較する:同じ評価セットを、コンパクション無効版と有効版で流し、正答率・タスク完遂率を測ります。
- トークン消費とコストを記録する:1タスクあたりの入力トークン・キャッシュヒット率・推定コストをログに残します。
- 長時間タスクで劣化を見る:ターン数を増やしていき、どのあたりで精度が落ち始めるかを観察します。これが context rot の自分のシステムでの実測値になります。
- 位置を入れ替えてテストする:重要情報を先頭・中央・末尾に置き換え、結果が変わるかを確認します。変われば lost in the middle の影響を受けている証拠です。
正直にお伝えすると、コンテキストエンジニアリングに「全部入れれば最適」という万能解はありません。タスク・モデル・コンテキスト充填率によって最適な配分は変わります。だからこそ、自分のエージェントで計測し、予算と圧縮の閾値を調整し続ける運用が前提になります。
まとめ:今日から始める3つのアクション
- 今日:自分のエージェントが1リクエストで何トークン使っているかを
count_messagesで計測し、構成要素ごとの内訳を出す。 - 今週中:可変予算(上限−固定費−出力枠)を定義し、超過時にツール結果の縮約と履歴コンパクションを発動する仕組みを入れる。
- 今月中:固定の評価セットで「圧縮あり/なし」を比較し、精度を落とさずにコストを下げられているかを定量チェックする。
この記事を読んで、自社エージェントのコンテキスト設計を見直したくなった方へ
Uravationでは、AIエージェントの設計・運用・社内導入の研修とコンサルティングを行っています。トークン予算設計やコスト最適化の伴走もご相談ください。
参考・出典
- Effective context engineering for AI agents — Anthropic(参照日: 2026-06-03)
- Prompt caching — Anthropic / Claude API Docs(参照日: 2026-06-03)
- Context Rot: How Increasing Input Tokens Impacts LLM Performance — Chroma(参照日: 2026-06-03)
- Lost in the Middle: How Language Models Use Long Contexts — Liu et al., 2023(参照日: 2026-06-03)
この記事はAIgent Lab編集部がお届けしました。


