
結論:AIエージェント実装は「①RAGでデータを用意する → ②エージェントを動かす → ③本番に耐えさせる」の3層で考え、各層を担う技術を正しい順序で組み合わせるのが最短ルートです。
- 要点1:RAGを組むなら、まず「ドキュメント抽出 → Embedding選定 → LlamaIndexで土台構築 → リランクで精度仕上げ」の順で固める。検索精度の8割はこの順序設計で決まります。
- 要点2:エージェント本体は「推論・プランニング設計 → コンテキスト管理 → ストリーミング応答」の3点セット。賢さ・コスト・体感速度をこの順で詰めます。
- 要点3:本番投入で差がつくのは信頼性設計(リトライ・冪等性・タイムアウト)と評価(合成データ生成)。ここを飛ばすと、デモは動くのに本番で落ちます。
対象読者:これからAIエージェント/RAGを実装する開発者・PM。個別の技術記事を読む前に「全体地図」と「学ぶ順序」を押さえたい方。
今日やること:自分のプロダクトが「①データ整備」「②推論設計」「③運用堅牢化」のどこで詰まっているかを1つ特定し、対応する中核記事から読み始める。
「AIエージェントを作りたいけど、結局どの技術を、どの順番で学べばいいんだ?」
これはAIエージェント開発を始めた人が、ほぼ全員ぶつかる壁です。RAG、Embedding、リランク、ReAct、コンテキストエンジニアリング、ストリーミング、冪等性……。それぞれ良質な解説記事はあるのに、いざ自分のプロダクトに落とそうとすると「で、何から手をつければ?」となります。
実際にAIエージェントを構築してみると分かるのですが、これらの技術はバラバラの知識ではなく、明確な依存関係と実装順序を持っています。データの土台がないと推論は精度が出ないし、推論が動いても信頼性設計がなければ本番で落ちる。順番を間違えると、後から大きな手戻りが発生します。
この記事は、AIエージェント実装に必要な中核9技術を「何のための技術か・いつ使うか・どの順で学ぶか」で地図化した索引(ピラー)記事です。薄いリンク集ではなく、各技術の役割・選び方・組み合わせの順序まで踏み込みます。深掘りが必要になったら、各セクションから個別の実装ガイドへ進んでください(2026年6月時点の構成です)。
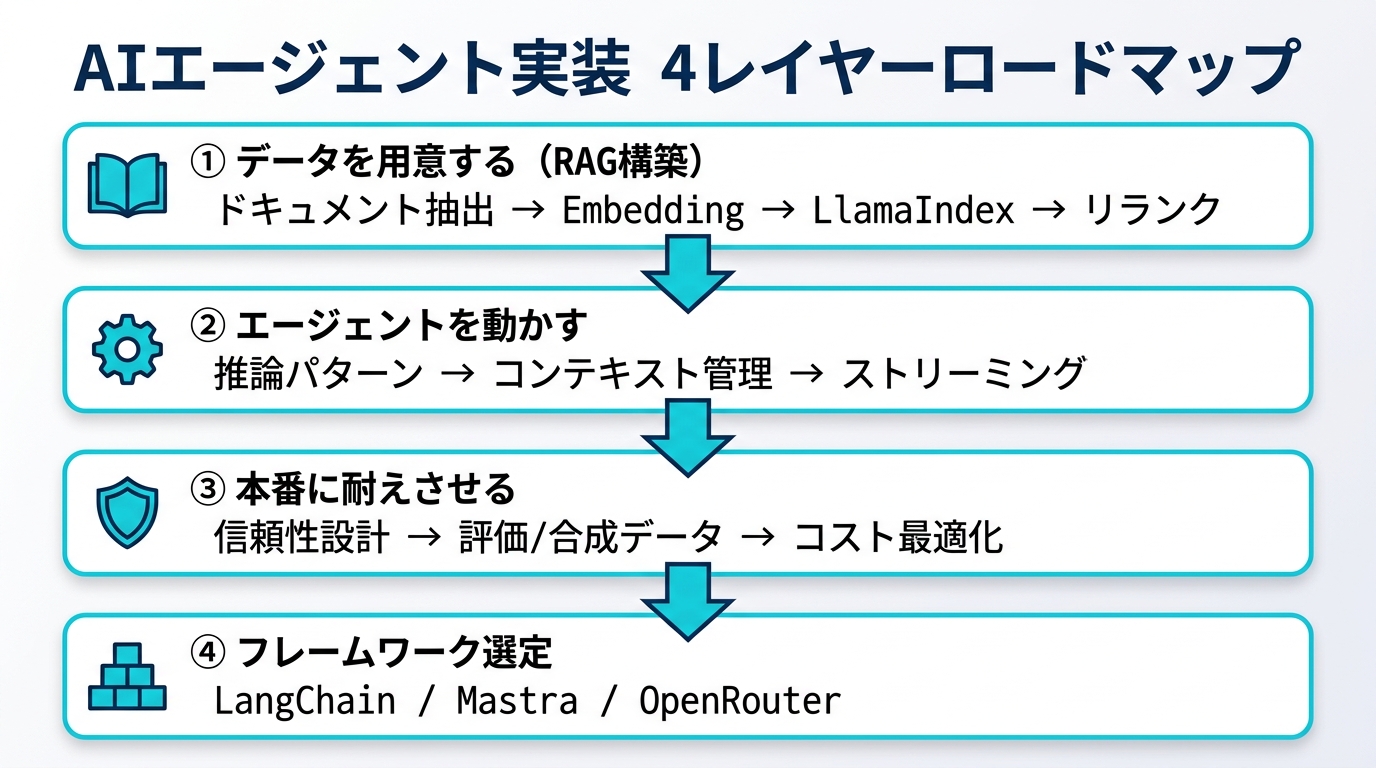
AIエージェント実装の全体地図 — 4つのレイヤー
まず全体像です。AIエージェント実装は、大きく次の4レイヤーに分解できます。下に行くほど「賢さ」から「堅牢さ」へ重心が移ります。
| レイヤー | 目的 | 担う中核技術 | 取り組む順序 |
|---|---|---|---|
| ① データを用意する(RAG構築) | エージェントに正しい知識を渡す | ドキュメント抽出 / Embedding / LlamaIndex / リランク | 最初に固める |
| ② エージェントを動かす | 賢く・速く振る舞わせる | 推論・プランニング / コンテキスト管理 / ストリーミング | データの次 |
| ③ 本番に耐えさせる | 落ちない・評価できる | 信頼性設計 / 合成データ生成(評価) | PoCを抜ける前 |
| ④ 基盤を選ぶ(フレームワーク) | ①〜③を載せる土台 | LangChain / Mastra / OpenRouter ほか | 並行して検討 |
ポイント:多くのチームが①を飛ばして②から入り、「精度が出ない」と悩みます。RAGの検索品質が低いまま推論を磨いても、ゴミを入れてゴミが出るだけです。まずデータ層、次に推論層、最後に運用層——この優先順位を崩さないことが、実装全体を通しての最重要原則です。
なお、ここで紹介する技術はすべて単独でも価値がありますが、本領を発揮するのは組み合わせたときです。各リンク先には個別の実装手順・コード例があるので、地図で全体像を掴んでから深掘りするのが効率的です。
レイヤー① データを用意する:RAGパイプラインの構築順序
RAG(Retrieval-Augmented Generation)は、AIエージェントが社内文書や最新情報を「根拠付きで」答えるための土台です。ここは順序が特に重要なので、推奨ルートを先に示します。
RAG構築の推奨順序:ドキュメント抽出 → Embedding選定 → LlamaIndexで実装 → リランクで仕上げ
1. ドキュメント抽出・パース(最初の関門)
RAGの精度は、検索より前の「元データをどれだけ綺麗に構造化できるか」で大きく左右されます。PDFの表が崩れる、ヘッダー・フッターが混入する、といった抽出段階の汚れは、後段のEmbeddingやリランクをどれだけ磨いても取り返せません。最初に取り組むべき工程です。
👉 詳細:ドキュメント抽出・パース RAG取り込み実装ガイド
2. Embeddingモデル選定(検索精度の土台)
Embeddingは、文書とクエリを「意味の近さ」で比較できるベクトルに変換する技術です。ここでの選定(日本語対応か、次元数、コスト、APIかローカルか)が、検索のヒット率を直接決めます。抽出した綺麗なデータを、最初にここでベクトル化します。
3. LlamaIndex(RAGデータフレームワークで実装を束ねる)
抽出・分割・Embedding・検索・保存といったRAGの一連の処理を、自前でつなぐと配線だらけになります。LlamaIndexはこのRAGパイプライン全体をデータフレームワークとして束ねてくれるため、PoCを素早く立ち上げたいときに有効です。「どこから手をつけるか」が見えたら、ここで実装の骨格を組みます。
👉 詳細:LlamaIndex RAGデータフレームワーク完全ガイド
4. リランク・ハイブリッド検索(精度の最後の一押し)
Embedding検索(ベクトル検索)だけだと、キーワード一致が必要な場面で取りこぼします。そこでキーワード検索と組み合わせる「ハイブリッド検索」と、取得した候補を再スコアリングする「リランク」を入れます。これはRAGの仕上げ工程で、土台ができてから追加すると効果を実感しやすい技術です。
👉 詳細:リランク・ハイブリッド検索 RAG精度向上完全ガイド
レイヤー② エージェントを動かす:推論・コンテキスト・応答
データの土台ができたら、エージェント本体を動かします。ここは「賢さ → コスト効率 → 体感速度」の順で詰めるのがおすすめです。
5. 推論・プランニングパターン(ReAct / Reflexion など)
エージェントを「賢く」振る舞わせる中核が、推論・プランニングの設計です。ツールを使いながら考えるReAct、自分の出力を振り返って改善するReflexionなど、目的に応じたパターンの選択が品質を左右します。単純な一問一答ではなく、複数ステップのタスクをこなさせたいなら、まずここを設計します。
👉 詳細:AIエージェントの推論・プランニングパターン(ReAct / Reflexion)
6. コンテキストエンジニアリング(管理・圧縮)
推論を回し始めると、すぐにコンテキストウィンドウが膨れ上がります。会話履歴・検索結果・ツール出力をどう取捨選択し、圧縮し、必要なものだけ渡すか——これがコンテキストエンジニアリングです。賢さの次に取り組むべき技術で、ここを詰めるとトークンコストと応答品質が同時に改善します。長く動くエージェントほど効きます。
👉 詳細:コンテキストエンジニアリング 管理・圧縮実装ガイド
7. ストリーミング応答(SSE・逐次表示)
エージェントの処理は数秒かかることが珍しくありません。回答を一括で待たせるとUXが大きく劣化します。SSE(Server-Sent Events)などで生成結果を逐次表示すれば、体感速度が一気に上がります。賢さとコストを整えた後、ユーザー体験の仕上げとして入れる技術です。
👉 詳細:LLMエージェントのストリーミング応答 SSE実装ガイド
レイヤー③ 本番に耐えさせる:信頼性設計と評価
デモは動くのに本番で落ちる——その差を埋めるのがこのレイヤーです。PoCから本番に進む前に必ず通過すべき工程です。
8. 信頼性設計(リトライ・冪等性・タイムアウト)
LLM APIや外部ツールは、ネットワークやレート制限で普通に失敗します。失敗時に安全に再試行できるよう、リトライ・冪等性(同じ操作を2回実行しても結果が壊れない設計)・タイムアウトを組み込みます。ここを軽視すると、本番で「決済を二重実行」「無限リトライでコスト爆発」といった事故につながります。本番投入の最低条件と考えてください。
👉 詳細:AIエージェントの信頼性設計(リトライ・冪等性・タイムアウト)
9. 合成データ生成(評価・テスト・学習データ)
「精度が上がった/下がった」を感覚で語らないために、評価が必要です。とはいえ実データのテストケースは集めにくい。そこでLLMで評価用・テスト用・ファインチューニング用のデータを合成します。信頼性設計と並行して整えると、改善のたびに定量的に効果測定できるようになります。
👉 詳細:合成データ生成 LLM評価・ファインチューニングガイド
レイヤー④ 基盤を選ぶ:フレームワークとゲートウェイ
①〜③の技術をどの土台に載せるか。フレームワーク選定は他のレイヤーと並行して進めて構いません。代表的な選択肢を、用途とあわせて整理します(いずれも詳細は各実装ガイドへ)。
- 処理を細かく組み立てたい(Python) → LCELで宣言的にチェーンを書くLangChain LCEL 完全ガイド。
- TypeScript / Webアプリ中心 → 型安全にエージェントを組むMastra(TypeScript)AIエージェントフレームワーク完全ガイド。
- 複数モデルを切り替え・コスト最適化したい → ゲートウェイ経由でモデルを使い分けるOpenRouter LLMゲートウェイ マルチモデル・コスト最適化。
- LLM出力を確実に構造化したい(Python) → 型に沿った出力を強制するInstructor 構造化出力ガイド。エージェントの安定動作に直結します。
応用:長期記憶・操作・エージェント間連携を足す
基本3層が動いたら、用途に応じて次のような応用技術を足していきます。必須ではありませんが、エージェントの能力を一段引き上げる選択肢です。
- 会話やタスクをまたいで記憶を保持したい → MemGPT 長期記憶エージェントガイド。コンテキスト管理(技術6)の発展形として捉えると理解しやすいです。
- 画面を見て操作させたい → Anthropic Computer Use API ハンズオン(Python / Docker)。GUI操作を伴うタスクの自動化に。
- 複数のエージェントを連携させたい → A2A(Agent2Agent)プロトコル実装ガイド。エージェント同士の通信を標準化します。
- 外部サービスと安全に接続したい → MCP OAuth 認可によるセキュアなエージェント連携。認可を伴う統合で重要になります。
技術の選び方:3つの判断軸
「全部やる」必要はありません。実際の実装では、次の3軸で優先順位をつけると無駄がありません。
| 判断軸 | 問い | 答えから決まること |
|---|---|---|
| 根拠が必要か | 社内文書や最新情報に基づいて答えさせるか? | 必要ならレイヤー①(RAG一式)が最優先 |
| 多段タスクか | 1回の応答で済むか、複数ステップを自律的にこなすか? | 多段なら推論パターン(技術5)とコンテキスト管理(技術6)が必須 |
| 本番運用か | デモ止まりか、ユーザーに使わせるか? | 本番なら信頼性設計(技術8)と評価(技術9)を先に |
正直にお伝えすると、すべての技術を一度に導入するのは現実的ではありません。まず「根拠が必要・多段タスク・本番運用」のどれに該当するかを切り分け、該当するレイヤーから着手するのが、手戻りを最小化する進め方です。小さく作って検証し、段階的に広げる——これがAIエージェント実装で最も効くアプローチです。
【要注意】よくある失敗パターンと回避策
失敗1:RAGの精度を、検索アルゴリズムだけで上げようとする
❌ Embeddingモデルやリランクばかり試す
⭕ まずドキュメント抽出・パースの品質を疑う
なぜ重要か:実際に構築してみると、RAGの精度問題の多くは元データの汚れに起因します。抽出段階で表やレイアウトが崩れていると、後段を磨いても上限が低いままです。順序として、抽出 → Embedding → リランクの上流から潰すのが鉄則です。
失敗2:推論を磨く前に、いきなり巨大なワークフローを組む
❌ 最初から10ステップの自律エージェントを設計
⭕ まず1〜2ステップで動かし、推論パターンとコンテキスト管理を検証してから拡張
なぜ重要か:ステップが増えるほど、どこで失敗したか追えなくなります。小さく組んで各ステップを観測可能にしてから広げると、最終的な品質が格段に上がります。
失敗3:信頼性設計と評価を「後回し」にする
❌ デモが動いたので、そのまま本番投入
⭕ 本番前にリトライ・冪等性・タイムアウトと、評価用データを用意する
なぜ重要か:LLMや外部APIは普通に失敗します。冪等性のない再試行は二重実行事故を、評価のない改善は「直したつもりで悪化」を招きます。本番に出す前の最低条件として組み込んでください。
よくある質問(FAQ)
Q1. AIエージェント実装は、何から学べば良いですか?
自分のプロダクトが「①根拠の必要なRAG」「②多段の推論」「③本番運用」のどこで詰まるかを先に切り分け、該当レイヤーの中核記事から始めるのが最短です。RAGが必要なら、ドキュメント抽出 → Embedding → LlamaIndex → リランクの順がおすすめです。
Q2. RAGとAIエージェントは何が違いますか?
RAGは「外部知識を検索して根拠付きで答える」仕組み、AIエージェントは「推論しながらツールを使ってタスクを遂行する」主体です。多くの実装ではエージェントの知識源としてRAGを組み込むため、本記事ではRAG(レイヤー①)をエージェント実装の土台と位置づけています。
Q3. RAGを組むとき、技術を導入する順序はありますか?
あります。ドキュメント抽出・パース → Embeddingモデル選定 → LlamaIndexで実装 → リランク・ハイブリッド検索で仕上げ、の順が推奨です。上流の抽出品質が下流の精度上限を決めるため、検索アルゴリズムより先にデータ品質を固めます。
Q4. コンテキストエンジニアリングとプロンプトエンジニアリングは違いますか?
役割が異なります。プロンプトは「どう指示するか」、コンテキストエンジニアリングは「どの情報を、どれだけ、どう圧縮して渡すか」の設計です。長く動くエージェントではコンテキスト管理(技術6)の比重が大きくなり、トークンコストと応答品質を同時に左右します。
Q5. 本番投入の前に、最低限おさえるべき技術はどれですか?
信頼性設計(リトライ・冪等性・タイムアウト)と、評価のための合成データ生成です。前者は障害時の事故を防ぎ、後者は改善の効果を定量的に測れるようにします。この2つを飛ばすと、デモは動くのに本番で落ちる典型パターンに陥ります。
参考・出典
- LlamaIndex 公式ドキュメント — LlamaIndex(参照日: 2026-06-04)
- LangChain Expression Language (LCEL) 概念ガイド — LangChain 公式(参照日: 2026-06-04)
- Effective context engineering for AI agents — Anthropic Engineering(参照日: 2026-06-04)
- Embeddings guide — OpenAI Platform 公式(参照日: 2026-06-04)
- Context windows — Anthropic 公式ドキュメント(参照日: 2026-06-04)
まとめ:今日から始める3つのアクション
- 今日やること:自分のプロダクトが「①データ整備」「②推論設計」「③運用堅牢化」のどこで詰まっているかを1つ特定し、対応する中核記事を1本読む。
- 今週中:RAGが必要なら、ドキュメント抽出 → Embedding → LlamaIndex → リランクの順で、最小構成のパイプラインを1本通す。
- 今月中:本番を見据えて、信頼性設計(リトライ・冪等性・タイムアウト)と評価用の合成データを用意し、改善を定量測定できる状態にする。
あわせて読みたい:
- LlamaIndex RAGデータフレームワーク完全ガイド — RAGの実装骨格をまず組みたい方へ
- AIエージェントの推論・プランニングパターン — エージェントを「賢く」する設計の入口
- Claude Agent SDK サブエージェント実装ガイド — 並列処理や専門タスクへの委任を実装したい方へ
この記事を読んで、AIエージェント実装の全体像が見えてきた方へ。
Uravationでは、AIエージェントの設計・導入・運用に関する研修・コンサルティングを行っています。RAG構築から本番運用の信頼性設計まで、自社プロダクトへの実装を伴走支援します。
著者:佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー10万人超。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』。
新着の実装テクニック
- セマンティックキャッシュ実践ガイド|LLMのコスト削減
- GraphRAG実践ガイド|ナレッジグラフでRAGの精度を上げる
- AIエージェント本番デプロイ・サービング実践ガイド
- PromptOps実践ガイド|プロンプトを本番で管理する
- RAGチャンキング戦略 完全ガイド|検索精度を決める分割設計
- AIエージェントのHuman-in-the-loop設計ガイド


